Spark Direct Reader mode
A detailed description of Spark Direct Reader mode includes how the Hive Warehouse Connector (HWC) transparently connects to Apache Hive metastore (HMS) to get transaction information, and then reads the data directly from the managed table location using the transaction snapshot. The properties you need to set, and when you need to set them, in the context of the Apache Spark session helps you successfully work in this mode.
Requirements and recommendations
Spark Direct Reader mode requires a connection to Hive metastore. A HiveServer (HS2) connection is not needed.
Spark Direct Reader for reading Hive ACID, transactional tables from Spark is supported for production use. Use Spark Direct Reader mode if your ETL jobs do not require authorization and run as super user.
Component interaction
The following diagram shows component interaction in HWC Spark Direct Reader mode.
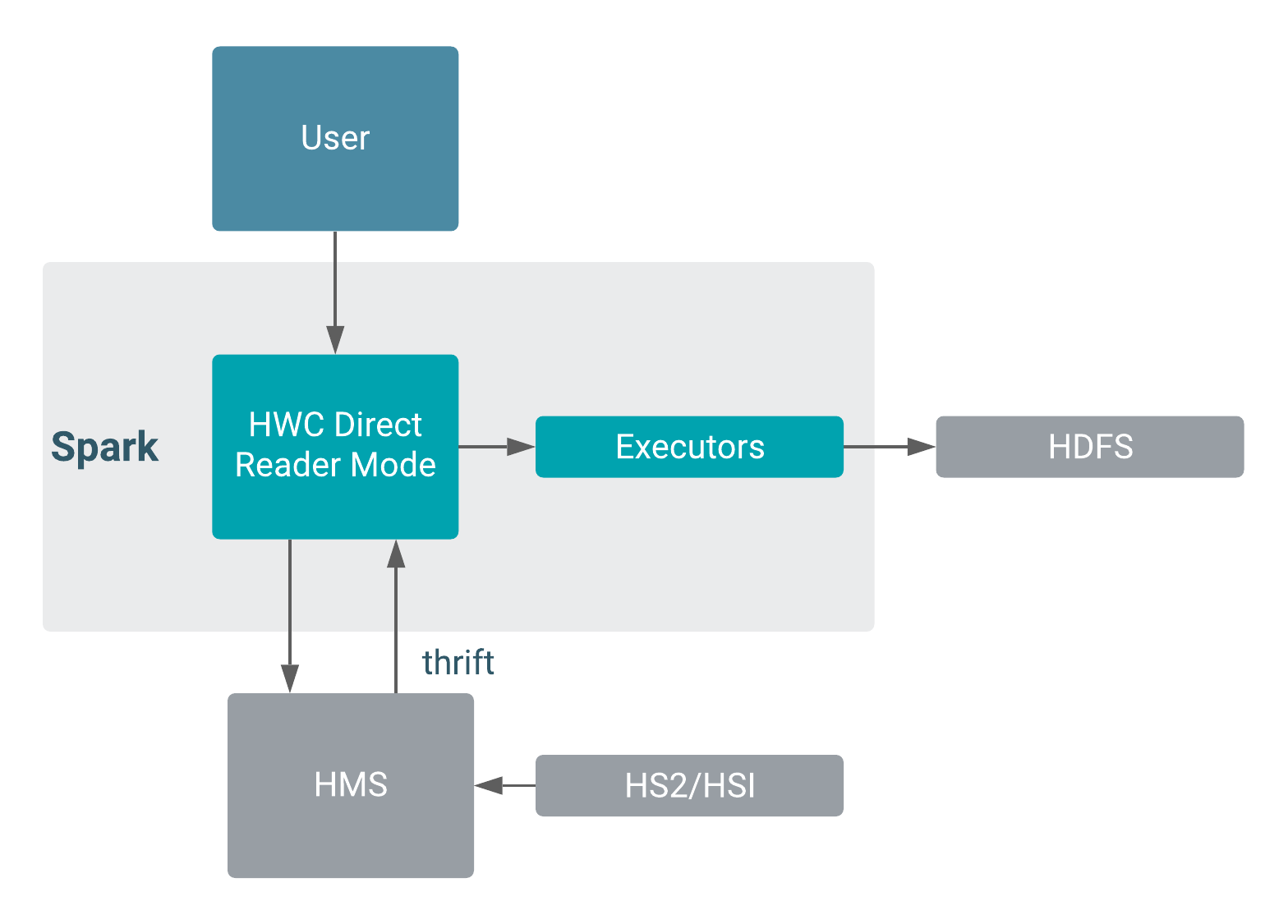
Spark Direct Reader Mode configuration
In configuration/spark-defaults.conf, or using the --conf option in spark-submit/spark-shell set the following properties:
- Name: spark.sql.extensions
- Value:
com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension
- Name: spark.kryo.registrator
- Value:
com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator
- Name: spark.sql.hive.hwc.execution.mode
- Value:
spark
- Name: spark.hadoop.hive.metastore.uris
- Value:
thrift://<host>:<port>
- Name: --jars
- Value: HWC jar
Example: Launch a spark-shell
spark-shell --jars \
/opt/cloudera/parcels/CDH/lib/hive_warehouse_connector/hive-warehouse-connector-assembly-<version>.jar \
--conf "spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension" \
--conf "spark.kryo.registrator=com.qubole.spark.hiveacid.util.HiveAcidKyroRegistrator" \
--conf "spark.hadoop.hive.metastore.uris=<metastore_uri>"Unsupported functionality
- Writes
- Streaming inserts
- CTAS statements
Limitations
- Does not enforce authorization; hence, you must configure read access to the HDFS, or
other, location for managed tables. You must have Read and Execute permissions on hive
warehouse location (
hive.metastore.warehouse.dir). - Supports only single-table transaction consistency. The direct reader does not guarantee that multiple tables referenced in a query read the same snapshot of data.
- Does not auto-commit transactions submitted by rdd APIs. Explicitly close transactions to release locks.
- Requires read and execute access on the hive-managed table locations.
- Does not support Ranger column masking and fine-grained access control.
- Blocks compaction on open read transactions.