Working with versioned S3 buckets
AWS S3 supports "Versioning" in buckets, where the bucket is configured to save older versions of objects. When an object is overwritten (or even deleted), the old version can be accessed when a request is made for the object using the original version ID.
For more information, see Using Versioning.
- S3Guard will record the versionId of new files written into the store. It can then use that value when opening a file, so that it can guarantee that the specific version listed in the S3Guard table is opened. This can compensate for eventual consistency of overwritten data —even if the old version is initially found when opening the file, the S3A connector can retry until the new version is found.
- When a file is opened for reading, the version ID of that file is recorded, and then for the duration of the file read (seconds, minutes, hours...) only that version of the data is read. Even if the file is overwritten, the single ongoing file read will always read the original data.
- When a file is copied (as in a rename operation), the version ID is used to guarantee that even if the source file is overwritten, the copied file will be the original version.
- It can be used as an alternative to moving deleted files to a trash location: simply delete the files and then recover them later. Note: The S3A connector does not provide a recovery tool.
- Too many S3 Tombstone markers from deleted objects will slow down directory listings, and can result in clients being throttled (https://docs.aws.amazon.com/AmazonS3/latest/dev/troubleshooting.html#troubleshooting-by-symptom-increase-503-reponses )
- Old versions of files are still billed for.
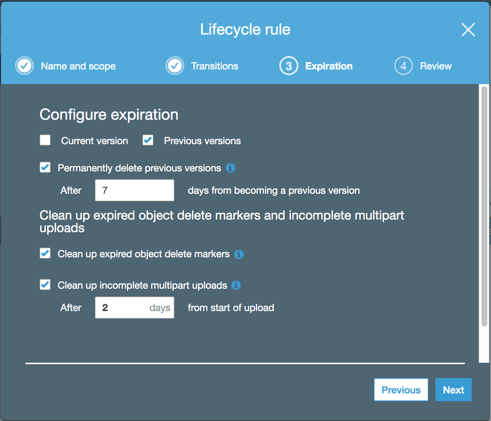
To keep costs down and minimize performance problems, we recommend having a lifecycle rule on the bucket which deletes older versions of files after a number of days. This can be done from the Management tab of the AWS S3 console.
Here is an example policy which deletes all versions of objects which were overwritten more than a week previously, while also cleaning up tombstone markers and incomplete file uploads: