Cloudera Search and other Cloudera Runtime components
Cloudera Search interacts with other Cloudera Runtime components to solve different problems. Learn about Cloudera components that contribute to the Search process and see how they interact with Cloudera Search.
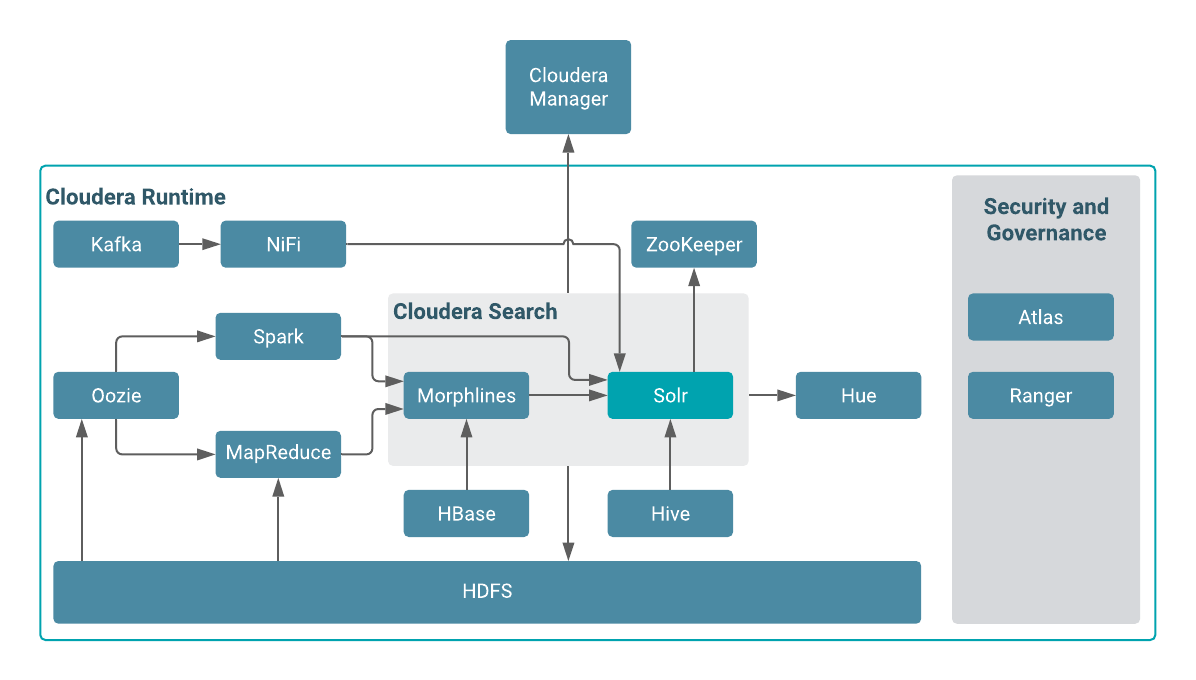
| Component | Contribution | Applicable To |
|---|---|---|
| HDFS | Stores source documents. Search indexes source documents to make them searchable. Files that support Cloudera Search, such as Lucene index files and write-ahead logs, are also stored in HDFS. Using HDFS provides simpler provisioning on a larger base, redundancy, and fault tolerance. With HDFS, Cloudera Search servers are essentially stateless, so host failures have minimal consequences. HDFS also provides snapshotting, inter-cluster replication, and disaster recovery. | All cases |
| MapReduce | Search includes a pre-built MapReduce-based job. This job can be used for on-demand or scheduled indexing of any supported data set stored in HDFS. This job uses cluster resources for scalable batch indexing. | Many cases |
| Hue | Hue includes a GUI-based Search application that uses standard Solr APIs and can interact with data indexed in HDFS. The application provides support for the Solr standard query language and visualization of faceted search functionality. | Many cases |
| Morphlines | A morphline is a rich configuration file that defines an ETL transformation chain. Morphlines can consume any kind of data from any data source, process the data, and load the results into Cloudera Search. Morphlines run in a small, embeddable Java runtime system, and can be used for near real-time applications such as the Lily HBase Indexer as well as batch processing applications such as a Spark job. | Many cases |
| ZooKeeper | Coordinates distribution of data and metadata, also known as shards. It provides automatic failover to increase service resiliency. | Many cases |
| Spark | The CrunchIndexerTool can use Spark to move data from HDFS files into Apache Solr, and run the data through a morphline for extraction and transformation. The Spark-Solr connector framework enables ETL of large datasets to Solr using spark-submit with a Spark job to batch index HDFS files into Solr. | Some cases |
| NiFi | Used for real time and often voluminous incoming event streams that need to be explorable (e.g. logs, twitter feeds, file appends etc). | |
| HBase | Supports indexing of stored data, extracting columns, column families, and key information as fields. Although HBase does not use secondary indexing, Cloudera Search can facilitate full-text searches of content in rows and tables in HBase. | Some cases |
| Cloudera Manager | Deploys, configures, manages, and monitors Cloudera Search processes and resource utilization across services on the cluster. Cloudera Manager helps simplify Cloudera Search administration. | Some cases |
| Atlas | Atlas classifications drive data access control through Ranger. | Some cases |
| Ranger | Enables role-based, fine-grained authorization for Cloudera Search. Ranger can apply restrictions to various actions, such as accessing data, managing configurations through config objects, or creating collections. Restrictions are consistently enforced, regardless of how users attempt to complete actions. Ranger offers both resource-based and tag-based access control policies. | Some cases |
| Oozie | Automates scheduling and management of indexing jobs. Oozie can check for new data and begin indexing jobs as required. | Some cases |
| Hive | Further analyzes search results. | Some cases |
| Kafka | Search uses this message broker project to increase throughput and decrease latency for handling real-time data. | Some cases |
| Sqoop | Ingests data in batch and enables data availability for batch indexing. | Some cases |