Apache Hive 3 tables
Table type definitions and a diagram of the relationship of table types to ACID properties clarifies Hive tables. The location of a table depends on the table type. You might choose a table type based on its supported storage format.
You can create ACID (atomic, consistent, isolated, and durable) tables for unlimited transactions or for insert-only transactions. These tables are Hive managed tables. Alternatively, you can create an external table for non-transactional use. Because Hive control of the external table is weak, the table is not ACID compliant.
The following diagram depicts the Hive table types.
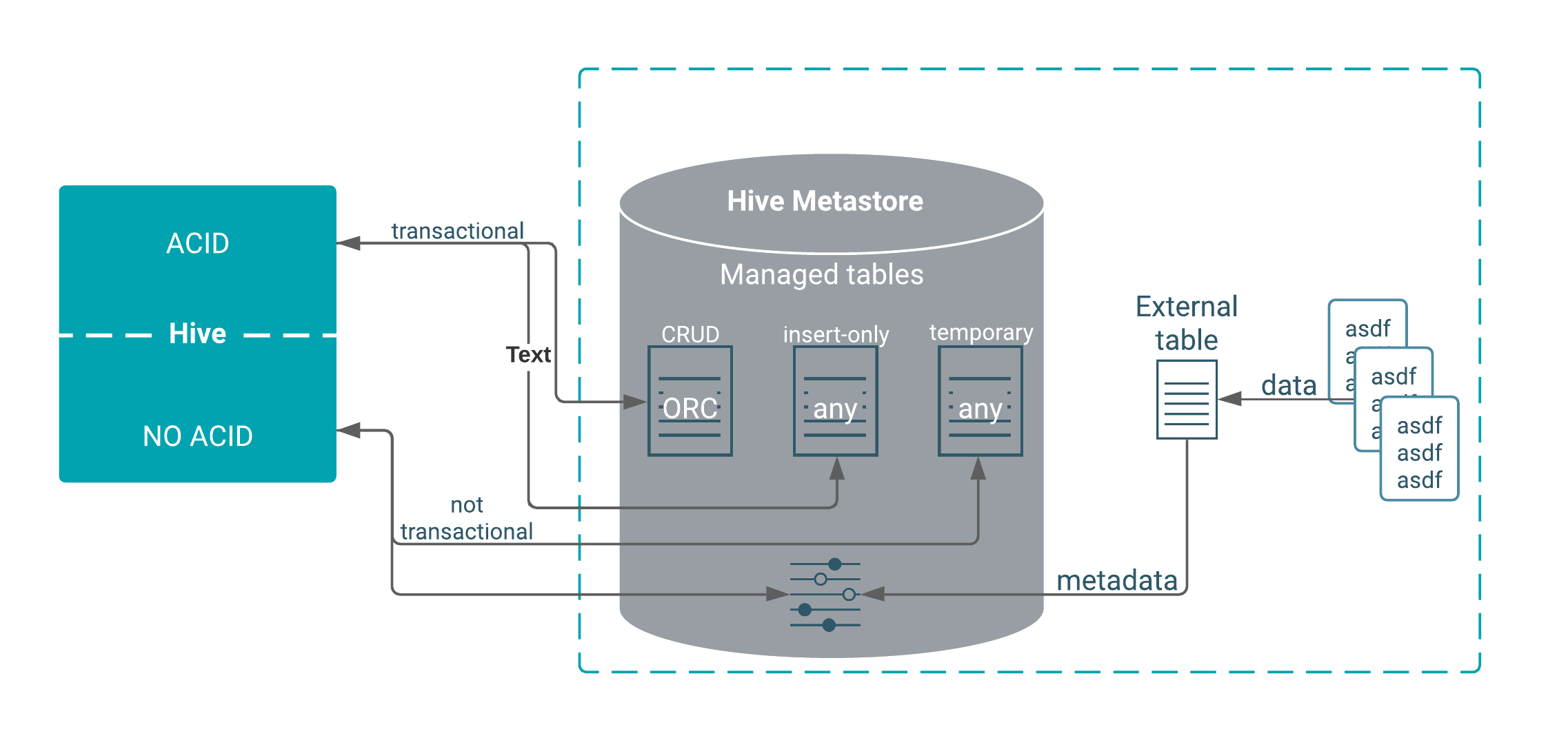
The following matrix includes the types of tables you can create using Hive, whether or not ACID properties are supported, required storage format, and key SQL operations.
| Table Type | ACID | File Format | INSERT | UPDATE/DELETE |
|---|---|---|---|---|
| Managed: CRUD transactional | Yes | ORC | Yes | Yes |
| Managed: Insert-only transactional | Yes | Any | Yes | No |
| Managed: Temporary | No | Any | Yes | No |
| External | No | Any | Yes | No |
Although you cannot use the SQL UPDATE or DELETE statements to delete data in some types of tables, you can use DROP PARTITION on any table type to delete the data.
Table storage formats
The data in CRUD tables must be in ORC format. Implementing a storage handler that supports AcidInputFormat and AcidOutputFormat is equivalent to specifying ORC storage.
Insert-only tables support all file formats.
The managed table storage type is Optimized Row Column (ORC) by default. If you accept the default by not specifying any storage during table creation, or if you specify ORC storage, you get an ACID table with insert, update, and delete (CRUD) capabilities. If you specify any other storage type, such as text, CSV, AVRO, or JSON, you get an insert-only ACID table. You cannot update or delete columns in the insert-only table.
Transactional tables
Transactional tables are ACID tables that reside in the Hive warehouse. To achieve ACID compliance, Hive has to manage the table, including access to the table data. Only through Hive can you access and change the data in managed tables. Because Hive has full control of managed tables, Hive can optimize these tables extensively.
Hive is designed to support a relatively low rate of transactions, as opposed to serving as an online analytical processing (OLAP) system. You can use the SHOW TRANSACTIONS command to list open and aborted transactions.
Transactional tables in Hive 3 are on a par with non-ACID tables. No bucketing or sorting is required in Hive 3 transactional tables. Bucketing does not affect performance. These tables are compatible with native cloud storage.
Hive supports one statement per transaction, which can include any number of rows, partitions, or tables.
External tables
External table data is not owned or controlled by Hive. You typically use an external table when you want to access data directly at the file level, using a tool other than Hive. You can also use a storage handler, such as Druid or HBase, to create a table that resides outside the Hive metastore.
Hive 3 does not support the following capabilities for external tables:
- Query cache
- Materialized views, except in a limited way
- Automatic runtime filtering
- File merging after insert
- ARCHIVE, UNARCHIVE, TRUNCATE, MERGE, and CONCATENATE. These statements only work for Hive Managed tables.
When you run DROP TABLE on an external table, by default Hive drops only the metadata
(schema). If you want the DROP TABLE command to also remove the actual data in the external
table, as DROP TABLE does on a managed table, you need to set the
external.table.purge property to true as described later.