Use BulkLoad
In many situations, writing HFiles programmatically with your data, and bulk-loading that data into HBase on the RegionServer, has advantages over other data ingest mechanisms.
HBase uses an internal file format called HFile to store its data on disk. BulkLoad operations
bypass the write path completely, providing the following benefits:
- The data is available to HBase immediately but does cause additional load or latency on the cluster when it appears.
- BulkLoad operations do not use the write-ahead log (WAL) and do not cause flushes or split storms.
- BulkLoad operations do not cause excessive garbage collection.
If you use BulkLoads with HBase, your workflow is similar to the following:
- Extract your data from its existing source. For instance, if your data is
in a MySQL database, you might run the
mysqldumpcommand. The process you use depends on your data. If your data is already in TSV or CSV format, skip this step and use the includedImportTsvutility to process your data into HFiles. See the ImportTsv documentation for details. - Process your data into HFile format. See
http://hbase.apache.org/book.html#_hfile_format_2
for details about HFile format. Usually you use a MapReduce job for
the conversion, and you often need to write the Mapper yourself
because your data is unique. The job must to emit the row key as the
Key, and either aKeyValue, aPut, or aDeleteas theValue. The Reducer is handled by HBase; configure it using HFileOutputFormat.configureIncrementalLoad() and it does the following:- Inspects the table to configure a total order partitioner
- Uploads the partitions file to the cluster and adds it to the
DistributedCache - Sets the number of
reducetasks to match the current number of regions - Sets the output key/value class to match
HFileOutputFormatrequirements - Sets the Reducer to perform the appropriate sorting (either
KeyValueSortReducerorPutSortReducer)
- One HFile is created per region in the output folder. Input data is
almost completely re-written, so you need available disk space at
least twice the size of the original data set. For example, for a
100 GB output from
mysqldump, you should have at least 200 GB of available disk space in HDFS. You can delete the original input file at the end of the process. - Load the files into HBase. Use the
LoadIncrementalHFilescommand (more commonly known as the completebulkload tool), passing it a URL that locates the files in HDFS. Each file is loaded into the relevant region on the RegionServer for the region. You can limit the number of versions that are loaded by passing the--versions= Noption, whereNis the maximum number of versions to include, from newest to oldest (largest timestamp to smallest timestamp).If a region was split after the files were created, the tool automatically splits the HFile according to the new boundaries. This process is inefficient, so if your table is being written to by other processes, you should load as soon as the transform step is done.
The following illustration shows the full BulkLoad process.
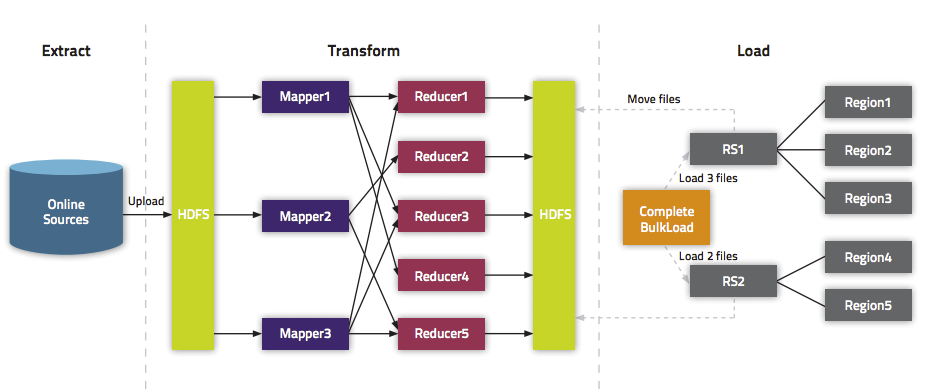
For an explanation of how secure BulkLoad works, see Bulk Loading .
Extra Steps for BulkLoad With Encryption Zones
When using BulkLoad to import data into HBase in the a cluster using encryption zones,
the following information is important.
- Both the staging directory and the directory into which you place your generated
HFiles need to be within HBase's encryption zone (generally under the
/hbasedirectory). Before you can do this, you need to change the permissions of/hbaseto be world-executable but not world-readable (rwx--x--x, or numeric mode711). - You also need to configure the HMaster to set the permissions of the HBase root
directory correctly. If you use Cloudera Manager, edit the Master Advanced
Configuration Snippet (Safety Valve) for hbase-site.xml. Otherwise, edit
hbase-site.xml on the HMaster. Add the
following:
If you skip this step, a previously-working BulkLoad setup will start to fail with permission errors when you restart the HMaster.<property> <name>hbase.rootdir.perms</name> <value>711</value> </property>