Spark execution model
Spark application execution involves runtime concepts such as driver, executor, task, job, and stage. Understanding these concepts is vital for writing fast and resource efficient Spark programs.
At runtime, a Spark application maps to a single driver process and a set of executor processes distributed across the hosts in a cluster.
The driver process manages the job flow and schedules tasks and is available the entire time the application is running. Typically, this driver process is the same as the client process used to initiate the job, although when run on YARN, the driver can run in the cluster. In interactive mode, the shell itself is the driver process.
The executors are responsible for performing work, in the form of tasks, as well as for storing any data that you cache. Executor lifetime depends on whether dynamic allocation is enabled. An executor has a number of slots for running tasks, and will run many concurrently throughout its lifetime.
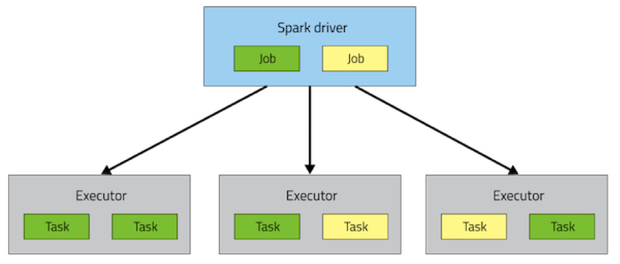
Invoking an action inside a Spark application triggers the launch of a job to fulfill it. Spark examines the dataset on which that action depends and formulates an execution plan. The execution plan assembles the dataset transformations into stages. A stage is a collection of tasks that run the same code, each on a different subset of the data.