Stateless NiFi Source and Sink
The Stateless NiFi Source and Sink connectors allow you to run NiFi dataflows within Kafka Connect. Using these connectors can grant you access to a number of NiFi features without having the need to deploy or maintain NiFi on your cluster. Learn more about what Stateless NiFi is and how it shipped in CDP.
Apache NiFi is a powerful tool for authoring and running dataflows. It provides many capabilities that are necessary for large-scale enterprise deployments, such as data persistence and resilience, data lineage and traceability, as well as multi-tenancy. This, however, requires an administrator who ensures that this process is running and operational. Additionally, in most cases, adding more capabilities to your deployments results in more complexity.
There are times, however, when users do not need all the power of NiFi, and running it in a much simpler form factor is sufficient. A common use case is to use NiFi to pull data from many different sources, perform manipulations (for example, convert JSON to Avro), filter some records, and then publish the data to Apache Kafka. Another common use case is to pull data from Apache Kafka, perform manipulations and filtering, and then publish the data elsewhere.
For deployments where NiFi acts only as a bridge into and out of Kafka, it can be simpler to operationalize such a deployment by running the dataflow within Kafka Connect. The Stateless NiFi Source and Sink connectors allow users to do just that.
Stateless NiFi
Dataflows within Kafka Connect run using the Stateless NiFi dataflow engine. Stateless NiFi differs from the traditional NiFi engine in the following ways:
- Stateless NiFi is an engine that is designed to be embedded. This makes it convenient to run it within the Kafka Connect framework.
- Stateless NiFi does not provide a user interface (UI) or a REST API. Additionally, it does not support modifying the dataflow while it is running.
- Stateless NiFi does not persist flowfile content to disk. Instead, it holds the content in memory.
- Stateless NiFi does not use data prioritizers. Instead, it operates on data in a first-in-first-out order. Dataflows built for Stateless NiFi must have a single source and a single destination. The only exception to this is when the data is routed to exactly one of multiple destinations, such as a failure destination or a success destination.
- Stateless NiFi does not currently provide access to data lineage/provenance.
- Stateless NiFi does not support cyclic graphs. While it is common and desirable in traditional NiFi to have a failure relationship from a processor route back to the same processor, this can result in a StackOverflowException in Stateless NiFi. The preferred approach in Stateless NiFi is to create an output port for failures and route the data to that output port.
Stateless NiFi in CDP
- Stateless NiFi Source and Sink connectors
- The Stateless NiFi Source and Sink connectors are generic connectors that act as the base for Stateless NiFi in Kafka Connect. The idea behind these connectors is that you develop your own dataflow in NiFi, and deploy that dataflow as a Kafka Connect connector using either Stateless Nifi Source or Sink connectors. This way, you can create virtually any connector without having to write a single line of code. All of the heavy lifting is done on the NiFi UI.
- Predefined dataflows and Stateless NiFi-based connectors
- In addition to the base Stateless NiFi Source and Sink connectors, Cloudera also
ships many connectors that are based on Stateless NiFi. Specifically, Cloudera ships a
set of predefined dataflows with CDP. These dataflows are developed and maintained by
Cloudera. Each dataflow covers a common data movement use case. These predefined flows
are presented as standalone connectors on the Streams Messaging Manager (SMM) UI.
Using these dataflows/connectors, you can immediately start using Stateless NiFi in
CDP without having to develop your own dataflow. You can find a full list of the Stateless NiFi-based connectors in Connectors. In addition, you can also use the SMM UI to check which of the connectors are Stateless NiFi-based. When adding a new connector using SMM, you are presented with a number of cards that represents the connectors available for deployment. Each card includes the following information about the connector:
- The connector's fully qualified class name.
- The connector's display name. If no display name is available, the card includes the unqualified classname.
- The version of the connector.
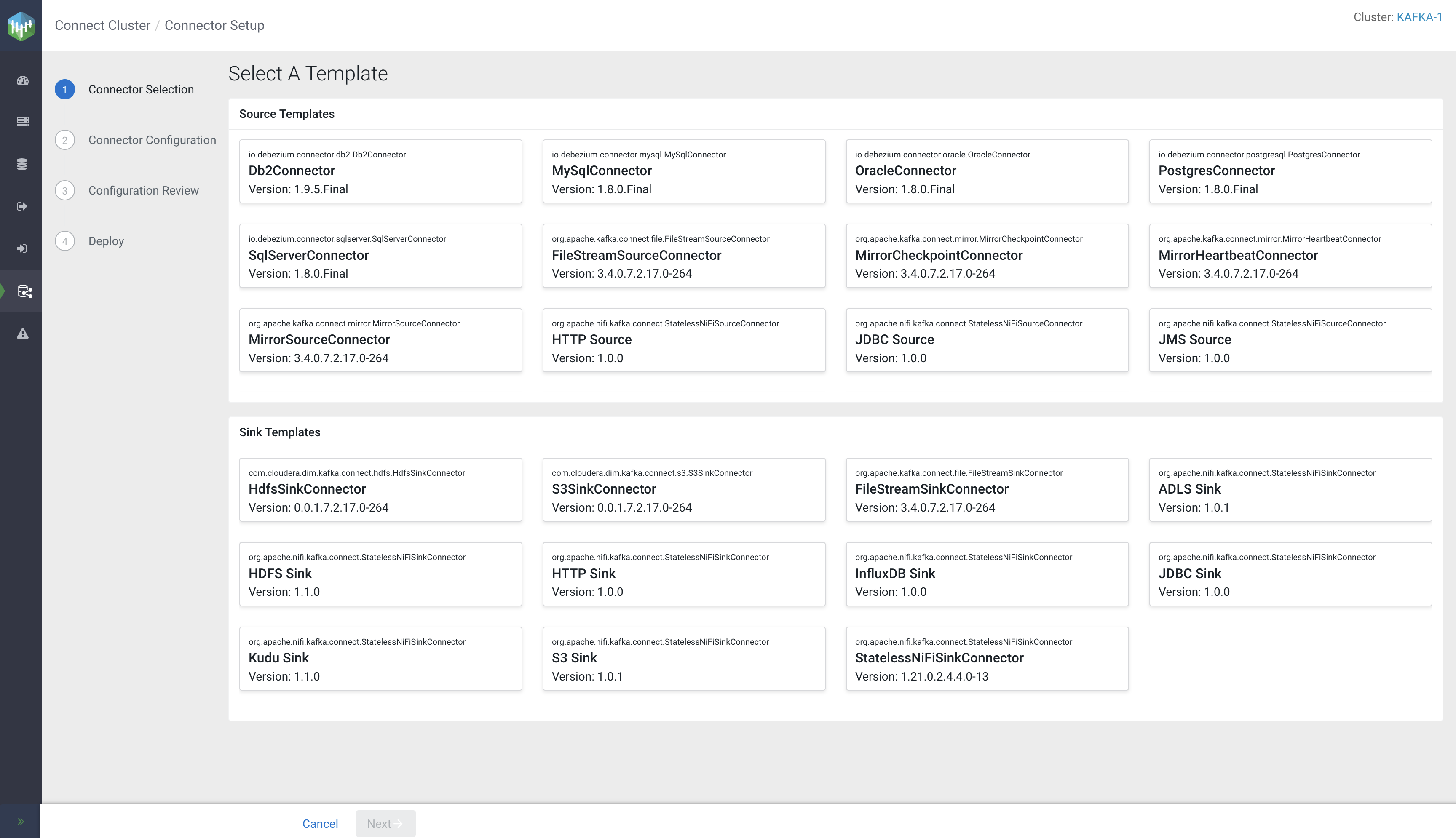
Notice how the fully qualified class name for many of the default available connectors is either org.apache.nifi.kafka.connect.StatelessNiFiSourceConnector or org.apache.nifi.kafka.connect.StatelessNiFiSinkConnector. Even though these are standalone connectors and have a unique display name, they are all Stateless NiFi connectors. Each of them runs a predefined flow designed for a specific use case. For example, JDBC Source runs a dataflow that reads records from a database table and transfers each record to Kafka.