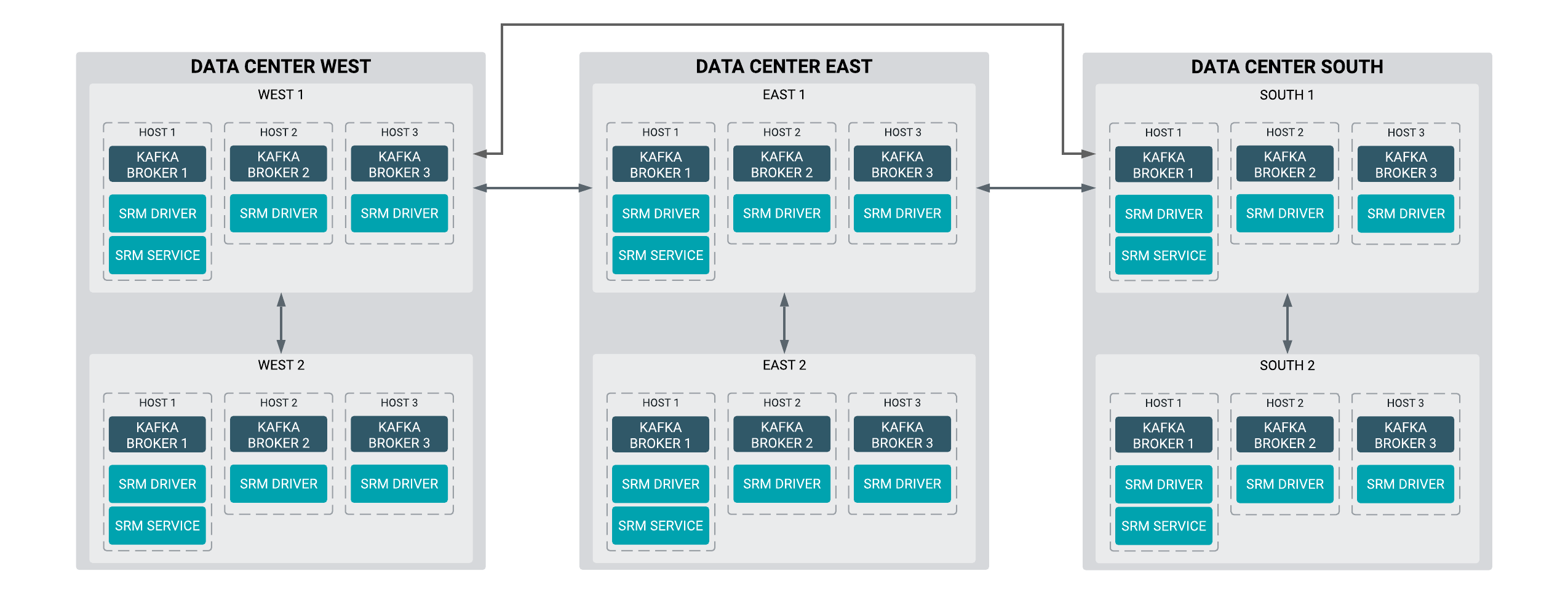
Cross Data Center Replication of Multiple Clusters
Configuration example with three data centers that have two Kafka clusters
each.
In more advanced deployments, you may have multiple Kafka clusters in each of several data
centers. To prevent creating a fully-connected mesh of all Kafka clusters, Cloudera
recommends leveraging a single Kafka cluster in each data center for cross data center
replication.
This example demonstrates the steps required to configure a deployment with three data
centers that each have two Kafka clusters. Additionally, it also provides example commands
to start bidirectional replication of all topics within each data center and an example on
how to replicate a single topic across all data centers.
Figure 1. Cross Data Center Replication of Multiple
Clusters
Install the following configuration file on every broker.
# six clusters in different data centers
clusters = west1, west2, east1, east2, south1, south2
# clusters in west DC
west1.bootstrap.servers = west1_host1:9092, west1_host2:9092, west1_host3:9092
west2.bootstrap.servers = west2_host1:9092, west2_host2:9092, west2_host3:9092
# clusters in east DC
east1.boostrap.servers = east1_host1:9092, east1_host2:9092, east1_host3:9092
east2.boostrap.servers = east2_host1:9092, east2_host2:9092, east2_host3:9092
# clusters in south DC
south1.boostrap.servers = south1_host1:9092, south1_host2:9092, south1_host3:9092
south2.boostrap.servers = south2_host1:9092, south2_host2:9092, south2_host3:9092
# cross data center replication via west1, east1, south1
west1->east1.enabled = true
west1->south1.enabled = true
east1->west1.enabled = true
east1->south1.enabled = true
south1->west1.enabled = true
south1->east1.enabled = true
# bidirectional replication within each DC
west1->west2.enabled = true
west2->west1.enabled = true
east1->east2.enabled = true
east2->east1.enabled = true
south1->south2.enabled = true
south2->south1.enabled = true
Run the srm-driver with the
--clusters option on every Kafka broker host.
Running the
srm-driver with the --clusters option allows you to
specify which clusters each instance of the driver should write to. In this example, both
instances of the driver are set up to read data from all clusters but only write to the
cluster they are running on. This allows you to distribute replication workloads.
In the west data
center:
srm-driver --clusters west1 west2
In the east data
center:
srm-driver --clusters east1 east2
In the south data
center:
srm-driver --clusters south1 south2
Optional: If you want to monitor replication, run
srm-service on one host per cluster. Each instance of the service
should target the cluster its running on.
# on a single host in west1:
$ srm-service --target west1
# on a single host in west2:
$ srm-service --target west2
# on a single host in east1:
$ srm-service --target east1
# on a single host in east2:
$ srm-service --target east2
# on a single host in south1:
$ srm-service --target south1
# on a single host in south2:
$ srm-service --target south2
Replicate topics between hosts within each data center: