

Core concepts
Cloudbreak includes the following core concepts: credentials, clusters, blueprints, cluster extensions, and external sources.
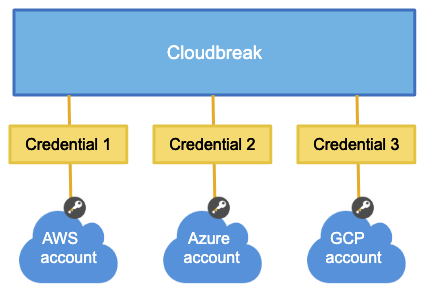
Credentials
After launching Cloudbreak, you are required to create a Cloudbreak credential for each cloud provider on which you would like to provision clusters. Only after you have completed that step, you can start creating clusters.
Cloudbreak credential allows Cloudbreak to authenticate with the cloud provider and obtain authorization to provision cloud provider resources on your behalf.
The authentication and authorization process varies depending on the cloud provider, but is typically done via assigning a specific IAM role to Cloudbreak which allows Cloudbreak to perform certain actions within your cloud provider account.
Clusters
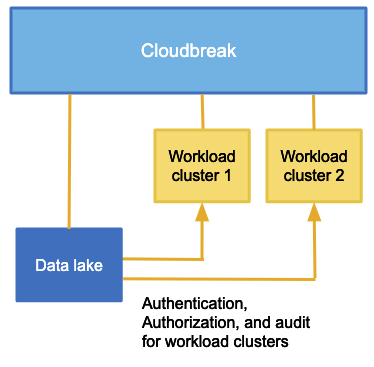
Cloudbreak allows you to create two types of clusters: workload clusters (referred to as "workload clusters", "ephemeral clusters", or "clusters") and data lake clusters (referred to as "data lakes").
- A master node runs the components for managing the cluster (including Ambari), storing data, processing tasks, as well as other master components.
- A worker node runs the components that are used for executing processing tasks and handling storing data in HDFS.
- A compute node can optionally be used for running data processing tasks.
 | Note |
|---|---|
Default HDF cluster blueprints do not follow this pattern. Furthermore, you can upload your own HDP and HDF workload cluster blueprints with custom node types. |
| Note |
|---|---|
The data lake functionality is technical preview. |
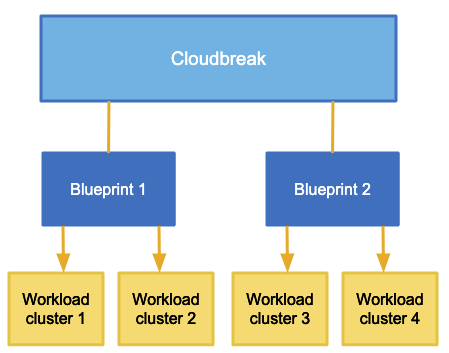
Blueprints
Ambari blueprints are a declarative definition of a cluster. A blueprint allows you to specify stack, component layout, and configurations to materialize a cluster instance via Ambari REST API, without having to use the Ambari cluster install wizard. Ambari blueprints are specified in JSON format. After you provide the blueprint to Cloudbreak, the host groups in the JSON are mapped to a set of instances when starting the cluster, and the specified services and components are installed on the corresponding nodes.
Cloudbreak includes a few default blueprints and allows you to upload your own blueprints.
Cluster extensions
Cloudbreak allows you to utilize the following cluster extensions:
- Recipes: Cloudbreak allows you to upload custom scripts, called "recipes". A recipe is a script that runs on all nodes of a selected node group at a specific time. You can use recipes for tasks such as installing additional software or performing advanced cluster configuration. For example, you can use a recipe to put a JAR file on the Hadoop classpath.
- Management packs: Management packs allow you to deploy a range of services to your Ambari-managed cluster. You can use a management pack to deploy a specific component or service, such as HDP Search, or to deploy an entire platform, such as HDF.
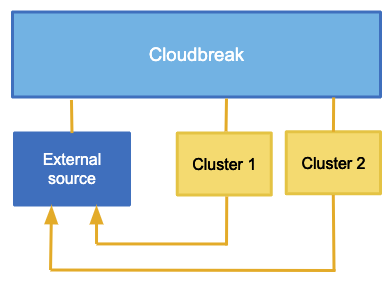
External sources
Cloudbreak allows you to define external sources that are created independently of a cluster – and therefore their lifespan is not limited by the lifespan of any cluster – and that can be reused with multiple clusters. The external sources that can be registered in Cloudbreak include:
| External source | Description |
|---|---|
| Authentication configurations (LDAP/AD) | Cloudbreak allows you to register an existing LDAP/AD instance as an external source and use it for multiple clusters. |
| Database configurations | Cloudbreak allows you to register existing RDBMS instances as external sources to be used as databases for specific cluster components (such as Ambari, Ranger, Hive, and so on), and then reuse them for multiple clusters. |
| Image catalogs | Cloudbreak provides a default image catalog with default prewarmed and base images, and allows you to create custom image catalogs with custom base images. While base images include only OS and tools, prewarmed images also include Ambari and stack. |
| Proxy configurations | Cloudbreak allows you to register an existing proxy to be used for your clusters. |
Workspaces
| Note |
|---|---|
It is not possible to share resources between workspaces; That is, every resource is attached to the workspace in which it was created and it cannot be shared with or moved to another workspace. |