
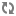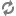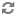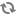
Event Details
Once we have performed our search, our table will be populated only with the events that
match the search criteria. From here, we can choose the Info icon (  ) on the left-hand side of the table to view the details of that
event:
) on the left-hand side of the table to view the details of that
event:
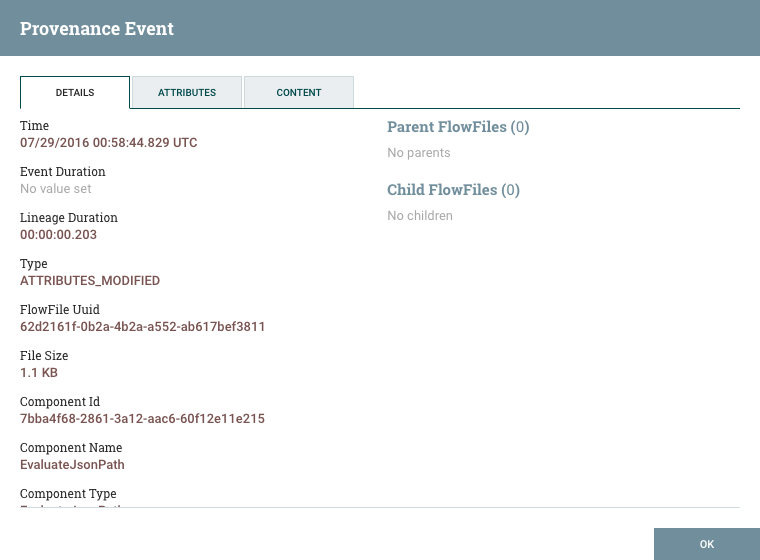
From here, we can see exactly when that event occurred, which FlowFile the event affected, which component (Processor, etc.) performed the event, how long the event took, and the overall time that the data had been in NiFi when the event occurred (total latency).
The next tab provides a listing of all Attributes that existed on the FlowFile at the time that the event occurred:
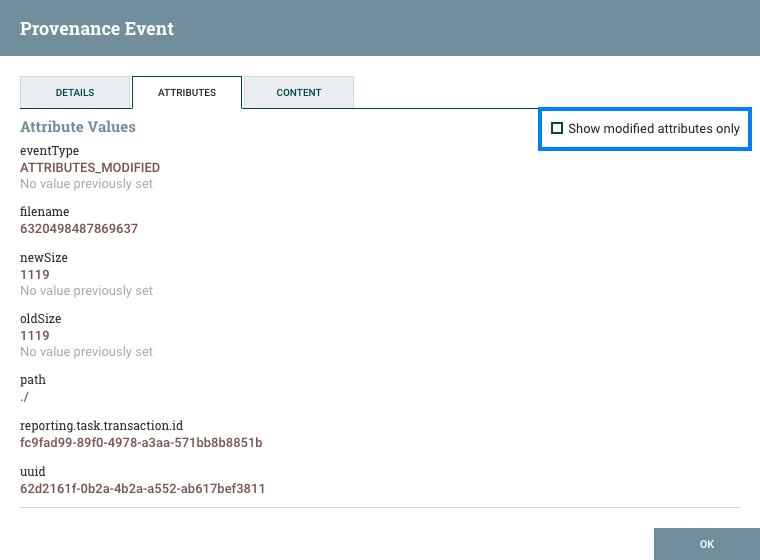
From here, we can see all the Attributes that existed on the FlowFile when the event occurred, as well as the previous values for those Attributes. This allows us to know which Attributes changed as a result of this event and how they changed. Additionally, in the right-hand corner is a checkbox that allows the user to see only those Attributes that changed. This may not be particularly useful if the FlowFile has only a handful of Attributes, but can be very helpful when a FlowFile has hundreds of Attributes.
This is very important because it allows the user to understand the exact context in which the FlowFile was processed. It is helpful to understand why the FlowFile was processed the way that it was, especially when the Processor was configured using the Expression Language.
Finally, we have the Content tab:
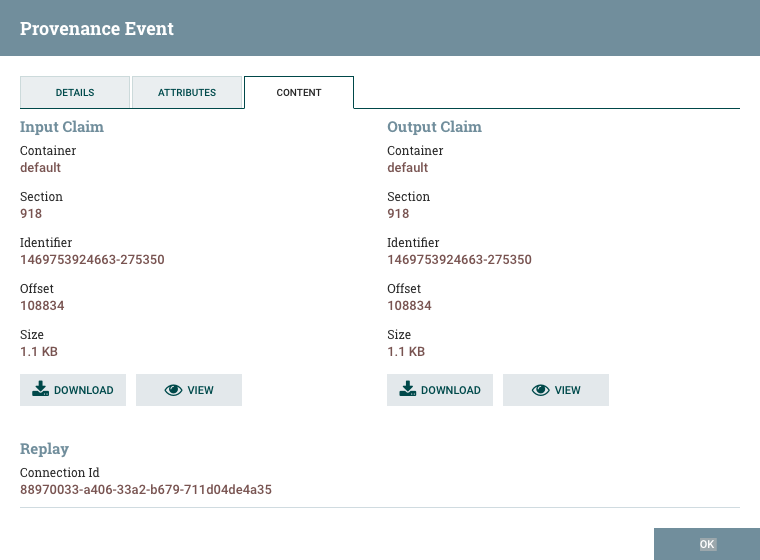
This tab provides us information about where in the Content Repository the FlowFile's content was stored. If the event modified the content of the FlowFile, we will see the before (input) and after (output) content claims. We are then given the option to Download the content or to View the content within NiFi itself, if the data format is one that NiFi understands how to render.
Additionally, in the Replay section of the tab, there is a Replay button that allows the user to re-insert the FlowFile into the flow and re-process it from exactly the point at which the event happened. This provides a very powerful mechanism, as we are able to modify our flow in real time, re-process a FlowFile, and then view the results. If they are not as expected, we can modify the flow again, and re-process the FlowFile again. We are able to perform this iterative development of the flow until it is processing the data exactly as intended.