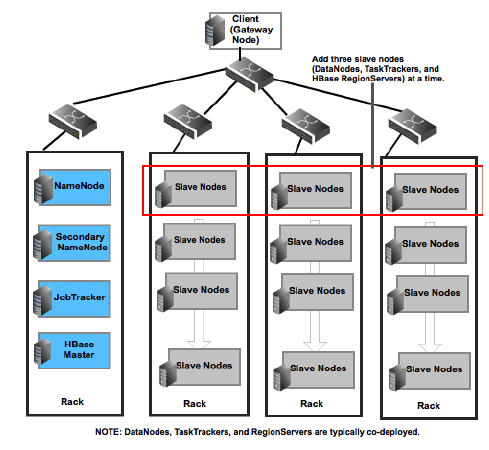
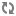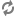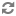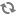A typical Hadoop cluster comprises of machines based on the various machine roles (master, slaves, and clients).
For more details, see: Machine Roles In A Typical Hadoop Cluster. The following illustration provides information about a typical Hadoop cluster.
A smallest cluster can be deployed using a minimum of four machines (for evaluation purpose only). One machine can be used to deploy all the master processes (NameNode, Secondary NameNode, JobTracker, HBase Master), Hive Metastore, WebHCat Server, and ZooKeeper nodes. The other three machines can be used to co-deploy the slave nodes (TaskTrackers, DataNodes, and RegionServers).
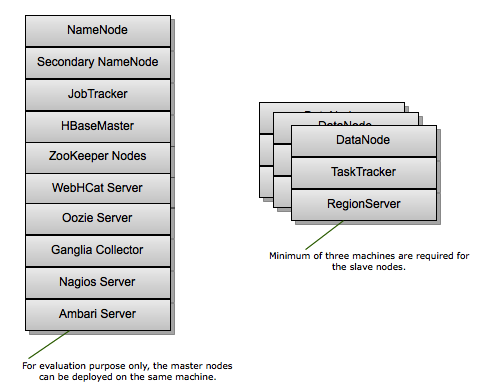
A minimum of three machines is required for the slave nodes in order to maintain the replication factor of three. For more details, see: Data Replication in Apache Hadoop
Machine roles in a typical Hadoop cluster:
In Hadoop and HBase, the following two types of machines are available:
Masters (HDFS NameNode, Secondary NameNode, MapReduce JobTracker, and the HBase Master)
![[Note]](../common/images/admon/note.png)
Note It is recommended to add only limited number of disks to the master nodes, because the master nodes do not have high storage demands.
Slaves (HDFS DataNodes, MapReduce TaskTrackers, and HBase RegionServers)
Additionally, we strongly recommend that you use separate client machines for performing the following tasks:
Load data in the HDFS cluster
Submit MapReduce jobs (describing how to process the data)
Retrieve or view the results of the job after its completion
Submit Pig or Hive queries
Based on the recommended settings for the client machines, the following illustration provides details of a Hadoop cluster: