This section provides you instructions on the following:
Use the following instructions to set-up Talend Open Studio:
Download and launch the application.
Download the Talend Open Studio add-on for HDP from here.
After the download is complete, unzip the contents in an install location.
Invoke the executable file corresponding to your operating system.
Read and accept the end user license agreement.
Create a new project.
Provide a project name (for example, HDPIntro) and click the Create button.

Click on the dialog.
Select the newly created project and click .
The Connect To TalendForge dialog appears, you can choose to register or click to continue.
You should now see the progress information bar and a welcome window. Wait for the application to initialize and then click to continue. Talend Open Studio (TOS) main window appears and is now ready for use.

This section provides instructions on designing a simple job of importing a file into the Hadoop cluster.
Create a new job.
In the Repository tree view, right-click the “Job Designs” node.
From the contextual menu, select “Create job”.

In the “New Job” wizard provide a name (for example HDPJob) and click “Finish”.
An empty design workspace corresponding to the Job name opens up.
Create a sample input file.
Under the
/tmpdirectory of your TOS master deployment machine, create a text file (for example:input.txt) with the following contents:101;Adam;Wiley;Sales 102;Brian;Chester;Service 103;Julian;Cross;Sales 104;Dylan;Moore;Marketing 105;Chris;Murphy;Service 106;Brian;Collingwood;Service 107;Michael;Muster;Marketing 108;Miley;Rhodes;Sales 109;Chris;Coughlan;Sales 110;Aaron;King;Marketing
Build the job. Jobs are composed of components that are available in the Palette.
Expand the tab in the Palette.
Click on the component
tHDFSPutand click on the design workspace to drop this component.Double-click tHDFSPut to define component in its Basic Settings view.
Set the values in the Basic Settings corresponding to your HDP cluster (see the screenshot given below):

Run the job. You now have a working job. You can run it by clicking the green play icon.
You should see the following:

Verify the import operation. From the gateway machine or the HDFS client, open a console window and execute the following command:
hadoop dfs -ls /user/testuser/data.txt
You should see the following result on your terminal window:
Found 1 items -rw-r--r-- 3 testuser testuser 252 2012-06-12 12:52 /user/ testuser/data.txt
This message indicates that the local file was successfully created in your Hadoop cluster.
Use the following instructions to aggregate data using Apache Pig.
Add Pig component from the Big Data Palette.
Expand the tab in the Big Data Palette.
Click on the component tPigLoad and place it in the design workspace.
Define basic settings for Pig component.
Double-click tPigLoad component to define its Basic Settings.
Click the button (“…” button). Define the schema of the input data as shown below and click :

Provide the values for the mode, configuration, NameNode URI, JobTracker host, load function, and input file URI fields as shown.
![[Important]](../common/images/admon/important.png)
Important Ensure that the NameNode URI and the JobTracker host corresponds to accurate values available in your HDP cluster. The Input File URI corresponds to the path of the previously imported
input.txtfile.
Connect the Pig and HDFS components to define the workflow.
Right-click the source component (
tHDFSPut) on your design workspace.From the contextual menu, select Trigger -> On Subjob Ok.
Click the target component (
tPigLoad).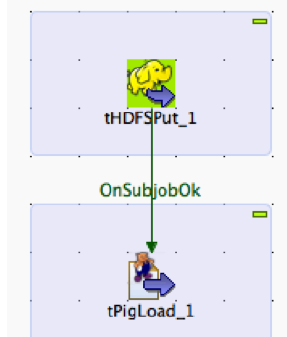
Add and connect Pig aggregate component.
Add the component tPigAggregate next to tPigLoad.
From the contextual menu, right-click on tPigLoad and select -> Pig Combine.
Click on tPigAggregate.

Define basic settings for Pig Aggregate component.
Double-click tPigAggregate to define the component in its Basic Settings.
Click on the “Edit schema” button and define the output schema as shown below:

Define aggregation function for the data.
Add a column to
Group by, choosedept.In the Operations table, choose the
people_countin the Additional Output column, function ascountand input columnidas shown:
Add and connect Pig data storage component
Add the component
tPigStoreResultnext totPigAggregate.From the contextual menu, right-click on
tPigLoad, select Row -> Pig Combine and click ontPigStoreResult.
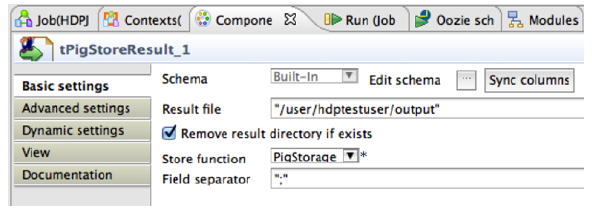
Define basic settings for data storage component.
Double-click tPigStoreResult to define the component in its Basic Settings view.
Specify the result directory on HDFS as shown:
Run the modified Talend job. The modified Talend job is ready for execution.
Save the job and click the play icon to run as instructed in Step 4.
Verify the results.
From the gateway machine or the HDFS client, open a console window and execute the following command:
hadoop dfs -cat /user/testuser/output/part-r-00000
You should see the following output:
Sales;4 Service;3 Marketing;3