This section describes the interaction between HCatalog with Sqoop.
HCatalog is a table and storage management service for Hadoop that enables users with different data processing tools – Pig, MapReduce, and Hive – to more easily read and write data on the grid. HCatalog’s table abstraction presents users with a relational view of data in the Hadoop distributed file system (HDFS) and ensures that users need not worry about where or in what format their data is stored: RCFile format, text files, or SequenceFiles.
HCatalog supports reading and writing files in any format for which a Hive SerDe (serializer-deserializer) has been written. By default, HCatalog supports RCFile, CSV, JSON, and SequenceFile formats. To use a custom format, you must provide the InputFormat and OutputFormat as well as the SerDe.
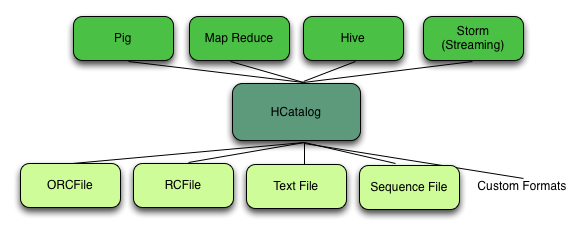
The ability of HCatalog to abstract various storage formats is used in providing RCFile (and future file types) support to Sqoop.
HCatalog interaction with Sqoop is patterned on an existing feature set that supports Avro and Hive tables. This section introduces five command line options, and some command line options defined for Hive are reused.
--hcatalog-databaseSpecifies the database name for the HCatalog table. If not specified, the default database name ‘default’ is used. Providing the
--hcatalog-databaseoption without--hcatalog-tableis an error. This is not a required option.--hcatalog-tableThe argument value for this option is the HCatalog tablename.
The presence of the
--hcatalog-tableoption signifies that the import or export job is done using HCatalog tables, and it is a required option for HCatalog jobs.--hcatalog-homeThe home directory for the HCatalog installation. The directory is expected to have a lib subdirectory and a share/hcatalog subdirectory with necessary HCatalog libraries. If not specified, the system environment variable HCAT_HOME will be checked and failing that, a system property hcatalog.home will be checked. If none of these are set, the default value will be used and currently the default is set to /usr/lib/hcatalog. This is not a required option.
--create-hcatalog-tableThis option specifies whether an HCatalog table should be created automatically when importing data. By default, HCatalog tables are assumed to exist. The table name will be the same as the database table name translated to lower case. Further described in Automatic Table Creation below.
--hcatalog-storage-stanzaThis option specifies the storage stanza to be appended to the table. Further described in Automatic Table Creation below.
The following Sqoop options are also used along with the --hcatalog-table option
to provide additional input to the HCatalog jobs. Some of the existing Hive import job options are
reused with HCatalog jobs instead of creating HCatalog-specific options for the same purpose.
--map-column-hiveThis option maps a database column to HCatalog with a specific HCatalog type.
--hive-homeThe Hive home location.
--hive-partition-keyUsed for static partitioning filter. The partitioning key should be of type STRING. There can be only one static partitioning key.
--hive-partition-valueThe value associated with the partition.
HCatalog integration in Sqoop has been enhanced to support direct mode connectors. Direct mode connectors are high performance connectors specific to a database. The Netezza direct mode connector is enhanced to use this feature for HCatalog jobs.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
Only the Netezza direct mode connector is currently enabled to work with HCatalog. |
Sqoop Hive options that are not supported with HCatalog jobs:
--hive-import--hive-overwrite
In addition, the following Sqoop export and import options are not supported with HCatalog jobs:
--direct--export-dir--target-dir--warehouse-dir--append--as-sequencefile--as-avrofile
All input delimiter options are ignored.
Output delimiters are generally ignored unless either
--hive-drop-import-delims or
--hive-delims-replacement is used. When the
--hive-drop-import-delims or
--hive-delims-replacement option is specified, all
database columns of typeCHAR are post-processed to either remove
or replace the delimiters, respectively. (See Delimited Text Formats
and Field and Line Delimiter Characters below.) This is only needed
if the HCatalog table uses text format.
Sqoop uses read-committed transaction isolation in its mappers to import
data. However, this may not be ideal for all ETL workflows, and you might want to
reduce the isolation guarantees. Use the --relaxed-isolation option to
instruct Sqoop to use read-uncommitted isolation level.
The read-uncommitted transaction isolation level is not supported on
all databases, such as Oracle. Specifying the --relaxed-isolation may
also not be supported on all databases.
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
There is no guarantee that two identical and subsequent uncommitted reads will return the same data. |
One of the key features of Sqoop is to manage and create the table metadata when importing
into Hadoop. HCatalog import jobs also provide for this feature with the option
--create-hcatalog-table. Furthermore, one of the important benefits
of the HCatalog integration is to provide storage agnosticism to Sqoop data movement jobs.
To provide for that feature, HCatalog import jobs provide an option that lets a user specifiy
the storage format for the created table.
The option --create-hcatalog-table is used as an indicator that a table
has to be created as part of the HCatalog import job.
The option --hcatalog-storage-stanza can be used to specify the storage
format of the newly created table. The default value for this option is "stored as rcfile".
The value specified for this option is assumed to be a valid Hive storage format expression.
It will be appended to the CREATE TABLE command generated by the HCatalog import job as part of
automatic table creation. Any error in the storage stanza will cause the table creation to fail
and the import job will be aborted.
Any additional resources needed to support the storage format referenced in the option
--hcatalog-storage-stanza should be provided to the job either by
placing them in $HIVE_HOME/lib or by providing them in HADOOP_CLASSPATH and LIBJAR files.
If the option --hive-partition-key is specified, then the value of this
option is used as the partitioning key for the newly created table. Only one partitioning key
can be specified with this option.
Object names are mapped to the lowercase equivalents as specified below when mapped to an HCatalog table. This includes the table name (which is the same as the external store table name converted to lower case) and field names.
HCatalog supports delimited text format as one of the table storage formats. But when delimited text is used and the imported data has fields that contain those delimiters, then the data may be parsed into a different number of fields and records by Hive, thereby losing data fidelity.
For this case, one of these existing Sqoop import options can be used:
--hive-delims-replacement--hive-drop-import-delims
If either of these options is provided on input, then any column of type STRING will be formatted with the Hive delimiter processing and then written to the HCatalog table.
The HCatalog table should be created before using it as part of a Sqoop job if the default table creation options (with optional storage stanza) are not sufficient. All storage formats supported by HCatalog can be used with the creation of the HCatalog tables. This makes this feature readily adopt new storage formats that come into the Hive project, such as ORC files.
The Sqoop HCatalog feature supports the following table types:
Unpartitioned tables
Partitioned tables with a static partitioning key specified
Partitioned tables with dynamic partition keys from the database result set
Partitioned tables with a combination of a static key and additional dynamic partitioning keys
Sqoop currently does not support column name mapping. However, the user is allowed to override
the type mapping. Type mapping loosely follows the Hive type mapping already present in Sqoop
except that SQL types “FLOAT” and “REAL” are mapped to HCatalog type “float”. In the Sqoop type mapping
for Hive, these two are mapped to “double”. Type mapping is primarily used for checking the column
definition correctness only and can be overridden with the --map-column-hive
option.
All types except binary are assignable to a String type.
Any field of number type (int, shortint, tinyint, bigint and bigdecimal, float and double) is assignable to another field of any number type during exports and imports. Depending on the precision and scale of the target type of assignment, truncations can occur.
Furthermore, date/time/timestamps are mapped to string (the full date/time/timestamp representation) or bigint (the number of milliseconds since epoch) during imports and exports.
BLOBs and CLOBs are only supported for imports. The BLOB/CLOB objects when imported are stored in a Sqoop-specific format and knowledge of this format is needed for processing these objects in a Pig/Hive job or another Map Reduce job.
Database column names are mapped to their lowercase equivalents when mapped to the HCatalog fields. Currently, case-sensitive database object names are not supported.
Projection of a set of columns from a table to an HCatalog table or loading to a column projection is allowed (subject to table constraints). The dynamic partitioning columns, if any, must be part of the projection when importing data into HCatalog tables.
Dynamic partitioning fields should be mapped to database columns that are defined with the NOT NULL attribute (although this is not validated). A null value during import for a dynamic partitioning column will abort the Sqoop job.
All the primitive HCatalog types are supported. Currently all the complex HCatalog types are unsupported.
BLOB/CLOB database types are only supported for imports.
With the support for HCatalog added to Sqoop, any HCatalog job depends on a set of jar files being available both on the Sqoop client host and where the Map/Reduce tasks run. To run HCatalog jobs, the environment variable HADOOP_CLASSPATH must be set up as shown below before launching the Sqoop HCatalog jobs.
HADOOP_CLASSPATH=$(hcat -classpath)
export HADOOP_CLASSPATH
The necessary HCatalog dependencies will be copied to the distributed cache automatically by the Sqoop job.
Create an HCatalog table, such as:
hcat -e "create table txn(txn_date string, cust_id string, amount float, store_id int) partitioned by (cust_id string) stored as rcfile;"Then Sqoop import and export of the "txn" HCatalog table can be invoked as follows:
- Import
$SQOOP_HOME/bin/sqoop import --connect <jdbc-url> -table <table-name> --hcatalog-table txn- Export
$SQOOP_HOME/bin/sqoop export --connect <jdbc-url> -table <table-name> --hcatalog-table txn