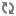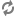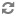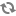Apache Hive 0.14 provides new INSERT ... VALUES, UPDATE, and DELETE SQL statements. The INSERT ... VALUES statement enables users to write data to Apache Hive from values provided in SQL statements. The UPDATE and DELETE statements allows users to modify and delete values already written to Hive. All three statements support auto-commit, meaning that each statement is a separate transaction that is automatically committed after the SQL statement is executed.
The INSERT ... VALUES, UPDATE, and DELETE statements require the following property values in the hive-site.xml configuration file:
| Configuration Property | Required Value |
|---|---|
|
|
|
|
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
Administrators must use a transaction manager that supports ACID and the ORC file format to use transactions. See Hive Transactions for information about configuring other properties related to use ACID-based transactions. |
INSERT ... VALUES Statement
The INSERT ... VALUES statement is revised to support adding multiple values into table columns directly from SQL statements. A valid INSERT ... VALUES statement must provide values for each column in the table. However, users may assign null values to columns for which they do not want to assign a value. In addition, the PARTITION clause must be included in the DML.
INSERT INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] VALUES values_row [, values_row...]
In this syntax, values_row is (value [, value]) and where value is either NULL or any SQL literal.
The following example SQL statements demonstrate several usage variations of this statement:
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3,2)) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC;
INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32); CREATE TABLE pageviews (userid VARCHAR(64), link STRING, from STRING) PARTITIONED BY (datestamp STRING) CLUSTERED BY (userid) INTO 256 BUCKETS STORED AS ORC;
INSERT INTO TABLE pageviews PARTITION (datestamp = '2014-09-23') VALUES ('jsmith', 'mail.com', 'sports.com'), ('jdoe', 'mail.com', null); INSERT INTO TABLE pageviews PARTITION (datestamp) VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21'); UPDATE Statement
Use the UPDATE statement to modify data already written to Apache Hive. Depending on the condition specified in the optional WHERE clause, an UPDATE statement may affect every row in a table. You must have both the SELECT and UPDATE privileges to use this statement.
UPDATE tablename SET column = value [, column = value ...] [WHERE expression];
The UPDATE statement has the following limitations:
The expression in the WHERE clause must be an expression supported by a Hive SELECT clause.
Partition and bucket columns cannot be updated.
Query vectorization is automatically disabled for UPDATE statements. However, updated tables can still be queried using vectorization.
Subqueries are not allowed on the right side of the SET statement.
The following example demonstrates the correct usage of this statement:
UPDATE students SET name = null WHERE gpa <= 1.0;
DELETE Statement
Use the DELETE statement to delete data already written to Apache Hive.
DELETE FROM tablename [WHERE expression];
The DELETE statement has the following limitation: query vectorization is automatically disabled for the DELETE operation. However, tables with deleted data can still be queried using vectorization.
The following example demonstrates the correct usage of this statement:
DELETE FROM students WHERE gpa <= 1,0;