
Introduction to HBase High Availability
HBase, architecturally, has had a strong consistency guarantee from the start. All reads and writes are routed through a single Region Server, which guarantees that all writes happen in order, and all reads access the most recently committed data.
However, because of this "single homing" of reads to a single location, if the server becomes unavailable, the regions of the table that are hosted in the Region Server become unavailable for some time until they are recovered. There are three phases in the region recovery process: detection, assignment, and recovery. Of these, the detection phase is usually the longest, currently on the order of 20 to 30 seconds depending on the ZooKeeper session timeout setting (if the Region Server became unavailable but the ZooKeeper session is alive). After that we recover data from the Write Ahead Log and assign the region to a different server. During this time -- until the recovery is complete -- clients are not able to read data from that region.
For some use cases the data may be read-only, or reading some amount of stale data is acceptable. With timeline-consistent highly available reads, HBase can be used for these kind of latency-sensitive use cases where the application can expect to have a time bound on the read completion.
For achieving high availability for reads, HBase provides a feature called “region replication”. In this model, for each region of a table, there can be multiple replicas that are opened in different Region Servers. By default, the region replication is set to 1, so only a single region replica is deployed and there are no changes from the original model. If region replication is set to 2 or more, then the master assigns replicas of the regions of the table. The Load Balancer ensures that the region replicas are not co-hosted in the same Region Servers and also in the same rack (if possible).
All of the replicas for a single region have a unique replica ID, starting with 0. The region replica with replica ID = 0 is called the "primary region." The others are called “secondary region replicas,” or "secondaries". Only the primary region can accept writes from the client, and the primary always contains the latest changes. Since all writes must go through the primary region, the writes are not highly available (meaning they might be blocked for some time if the region becomes unavailable).
In the following image, for example, Region Server 1 is responsible for responding to queries and scans for keys 10 through 40. If Region Server 1 crashes, the region holding keys 10-40 is unavailable for a short time until the region recovers.
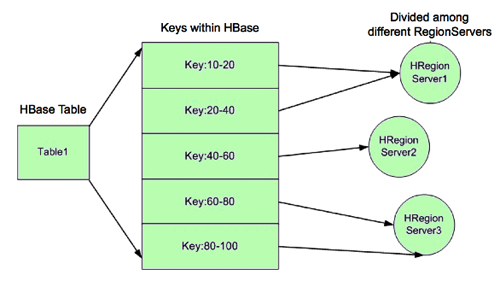
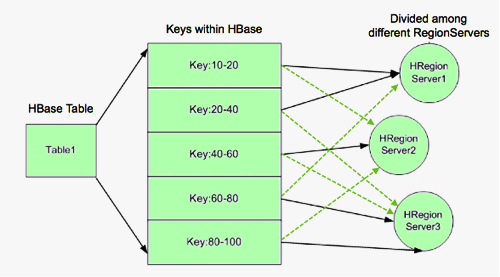
HA provides a way to access keys 10-40 even if Region Server 1 is not available, by hosting replicas of the region and assigning the region replicas to other Region Servers as backups. In the following image, Region Server 2 hosts secondary region replicas for keys 10-20, and Region Server 3 hosts the secondary region replica for keys 20-40. Region Server 2 also hosts the secondary region replica for keys 80-100. There are no separate Region Server processes for secondary replicas. Rather, Region Servers can serve regions in primary or secondary mode. When Region Server 2 services queries and scans for keys 10-20, it acts in secondary mode.
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
Regions acting in secondary mode are also known as Secondary Region Replicas. However, there is no separate Region Server process. A region in secondary mode can read but cannot write data. In addition, the data it returns may be stale, as described in the following section. |
Timeline and Strong Data Consistency
HBase guarantees timeline consistency for all data served from Region Servers in secondary mode, meaning all HBase clients see the same data in the same order, but that data may be slightly stale. Only the primary Region Server is guaranteed to have the latest data. Timeline consistency simplifies the programming logic for complex HBase queries and provides lower latency than quorum-based consistency.
In contrast, strong data consistency means that the latest data is always served. However, strong data consistency can greatly increase latency in case of a Region Server failure, because only the primary Region Server is guaranteed to have the latest data. The HBase API allows application developers to specify which data consistency is required for a query.
| Note |
|---|---|
The HBase API contains a method called |