Chapter 1. HDP Data Governance
Enterprises that adopt modern data architectures with Hadoop must reconcile data management realities when they bring existing and new data from disparate platforms under management. As Hadoop is deployed in corporate data and processing environments, metadata and data governance must be vital parts of any enterprise-ready data lake to realize true value.
In HDP, the overall management of the data life cycle in the platform is achieved by using data pipelines, which ingest, move, tag, process, and expire data, and an underlying flexible metadata store that manages all data for all components of HDP. This underlying metadata store simplifies data governance for Hadoop because you no longer must create interfaces to each HDP component. Instead, you can program your third-party governance applications to access one HDP metadata store that gives you access to all metadata for the platform.
Data governance in HDP is managed by the following components:
Apache Falcon: solves enterprise challenges related to Hadoop data replication, business continuity, and lineage tracing by deploying a framework for data management and processing. The Falcon framework can also leverage other HDP components, such as Pig, HDFS, and Oozie. Falcon enables this simplified management by providing a framework to define, deploy, and manage data pipelines. Data pipelines contain:
A definition of the dataset to be processed.
Interfaces to the Hadoop cluster where the data resides.
A process definition that defines how the data is consumed and invokes processing logic.
Apache Atlas: extends Falcon's governance capabilities by adding business taxonomical and operational metadata. Atlas is a scalable and extensible set of core governance services that enable enterprises to meet their compliance requirements within the Hadoop stack and to integrate with their data ecosystem outside HDP. Atlas provides:
Data classification.
Centralized auditing.
Search and lineage history.
Security and policy engines.
Falcon Overview
Apache Falcon addresses the following data governance requirements and provides a wizard-like GUI that eliminates hand coding of complex data sets and offers:
Centrally manage the data lifecycle: Falcon enables you to manage the data lifecyle in one common place where you can define and manage policies and pipelines for data ingest, processing, and export.
Business continuity and disaster recovery: Falcon can replicate HDFS and Hive datasets, trigger processes for retry, and handle late data arrival logic. In addition, Falcon can mirror file systems or Hive HCatalog on clusters using recipes that enable to you re-use complex workflows.
Address audit and compliance requirements: Falcon provides audit and compliance features that enable you to visualize data pipeline lineage, track data pipeline audit logs, and tag data with business metadata.
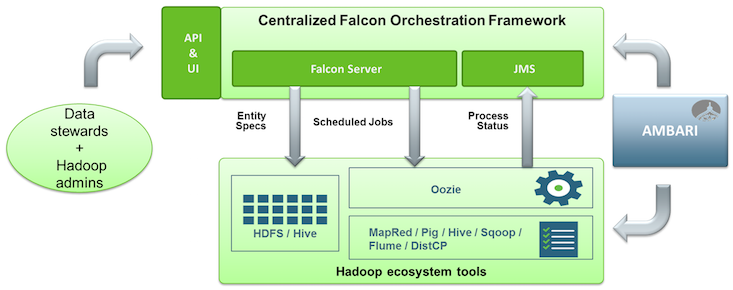
Falcon can be installed and managed by Apache Ambari, and jobs can be traced through the native Falcon UI. Falcon can process data from:
Oozie jobs
Pig scripts
Hive scripts
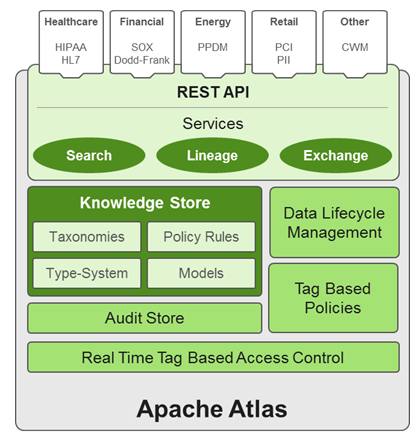
Atlas Overview
Apache Atlas is a low-level service in the Hadoop stack that provides core metadata services. Initially, Atlas provides metadata services for Hive, but in subsequent releases all components of HDP will be brought under Atlas metadata manaagement. Atlas provides:
Knowledge store that leverages existing Hadoop metastores: Categorized into a business-oriented taxonomy of data sets, objects, tables, and columns. Supports the exchange of metadata between HDP foundation components and third-party applications or governance tools.
Data lifecycle management: Leverages existing investment in Apache Falcon with a focus on provenance, multi-cluster replication, data set retention and eviction, late data handling, and automation.
Audit store: Historical repository for all governance events, including security events (access, grant, deny), operational events related to data provenance and metrics. The Atlas audit store is indexed and searchable for access to governance events.
Security: Integration with HDP security that enables you to establish global security policies based on data classifications and that leverages Apache Ranger plug-in architecture for security policy enforcement.
Policy engine: Fully extensible policy engine that supports metadata-based, geo-based, and time-based rules that rationalize at runtime.
RESTful interface: Supports extensibility by way of REST APIs to third-party applications so you can use your existing tools to view and manipulate metadata in the HDP foundation components.