
Chapter 1. Hive Architectural Overview
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
This guide is intended as an introduction to Hive performance tuning. The content will be updated on a regular cadence over the next few months. |
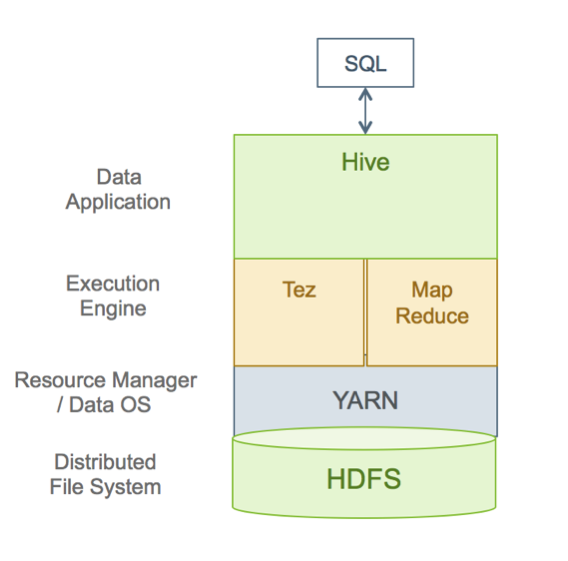
SQL queries are submitted to Hive and they are executed as follows:
Hive compiles the query.
An execution engine, such as Tez or MapReduce, executes the compiled query.
The resource manager, YARN, allocates resources for applications across the cluster.
The data that the query acts upon resides in HDFS (Hadoop Distributed File System). Supported data formats are ORC, AVRO, Parquet, and text.
Query results are then returned over a JDBC/ODBC connection.
A simplified view of this process is shown in the following figure.
Detailed Query Execution Architecture
The following diagram shows a detailed view of the HDP query execution architecture:
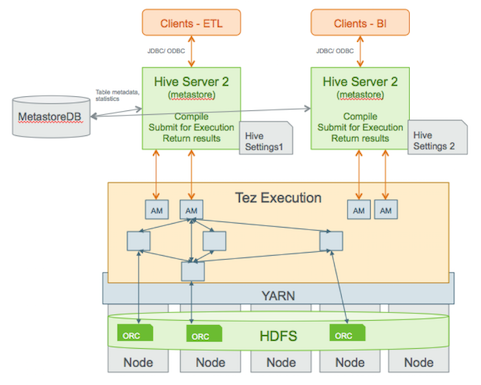
The following sections explain major parts of the query execution architecture.
Hive Clients
You can connect to Hive using a JDBC/ODBC driver with a BI tool, such as Microstrategy, Tableau, BusinessObjects, and others, or from another type of application that can access Hive over a JDBC/ODBC connection. In addition, you can also use a command-line tool, such as Beeline, that uses JDBC to connect to Hive. The Hive command-line interface (CLI) can also be used, but it has been deprecated in the current release and Hortonworks does not recommend that you use it for security reasons.
SQL in Hive
Hive supports a large number of standard SQL dialects. In a future release, when SQL:2011 is adopted, Hive will support ANSI-standard SQL.
HiveServer2
Clients communicate with HiveServer2 over a JDBC/ODBC connection, which can handle multiple user sessions, each with a different thread. HiveServer2 can also handle long-running sessions with asynchronous threads. An embedded metastore, which is different from the MetastoreDB, also runs in HiveServer2. This metastore performs the following tasks:
Get statistics and schema from the MetastoreDB
Compile queries
Generate query execution plans
Submit query execution plans
Return query results to the client
Multiple HiveServer2 Instances for Different Workloads
Multiple HiveServer2 instances can be used for:
Load-balancing and high availability using ZooKeeper
Running multiple applications with different settings
Because HiveServer2 uses its own settings file, using one for ETL operations and another for interactive queries is a common practice. All HiveServer2 instances can share the same MetastoreDB. Consequently, setting up multiple HiveServer2 instances that have embedded metastores is a simple operation.
Tez Execution
After query compilation, HiveServer2 generates a Tez graph that is submitted to YARN. A Tez Application Master (AM) monitor the query while it is running.
Security
HiveServer2 performs standard SQL security checks when a query is submitted, including connection authentication. After the connection authentication check, the server runs authorization checks to make sure that the user who submits the query has permission to access the databases, tables, columns, views, and other resources required by the query. Hortonworks recommends that you use SQLStdAuth or Ranger to implement security. Storage-based access controls, which is suitable for ETL workloads only, is also available.
File Formats
Hive supports many file formats. You can write your own SerDes (Serializers, Deserializers) interface to support new file formats.