
Chapter 2. Data Management and Falcon Overview
In the Hortonworks Data Platform (HDP), the overall management of the data lifecycle in the platform is achieved through Apache Falcon. Falcon provides powerful, end-to-end data management for the Hadoop platform. It is also a core part of data governance.
Core capabilities include the following:
Data lifecycle management
Management and monitoring of all data movement on HDP
Data transfer in to and out of HDP
Support for complex data processing topologies using data pipelines
Integration with Apache Atlas for data lineage and provenance management
For more information about data governance and Apache Atlas, see the Data Governance Guide.
Apache Falcon solves enterprise challenges related to Hadoop data replication, business continuity, and lineage tracing by deploying a framework for data management and processing. The Falcon framework leverages other HDP components, such as Apache Pig, Apache Hadoop Distributed File System (HDFS), Apache Sqoop, Apache Hive, Apache Spark, and Apache Oozie.
Falcon enables simplified management by providing a framework to define and manage backup, replication, and data transfer. Falcon addresses the following data management and movement requirements:
Centrally manage the data lifecycle: Falcon enables you to manage the data lifecycle in one common place where you can define and manage policies and pipelines for data ingest, processing, and export.
Business continuity and disaster recovery: Falcon can replicate HDFS and Hive datasets, trigger processes for retry, and handle late data arrival logic. In addition, Falcon can mirror file systems or Hive HCatalog databases and tables on clusters using server-side extensions that enable you to re-use complex workflows.
Address audit and compliance requirements: Falcon provides audit and compliance features that enable you to visualize data pipeline lineage, track data pipeline audit logs, and tag data with business metadata.
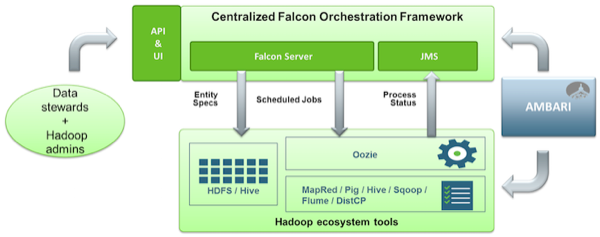
Falcon Access
There are three methods to access Falcon:
Using the Falcon graphical user interface, accessible from Apache Ambari either stand-alone or as an Ambari View
See the Apache Ambari Views guide for installation instructions for the Falcon View.
Using the Falcon CLI
Using the Falcon APIs, as a service
Understanding Entity Relationships
Falcon entities are configured to form a data pipeline. A pipeline consists of a dataset and the processing that acts on the dataset across your HDFS cluster. You can configure data pipelines for data replication and mirroring.
When creating a data pipeline, you must define cluster storage locations and interfaces, dataset feeds, and the processing logic to be applied to the datasets.
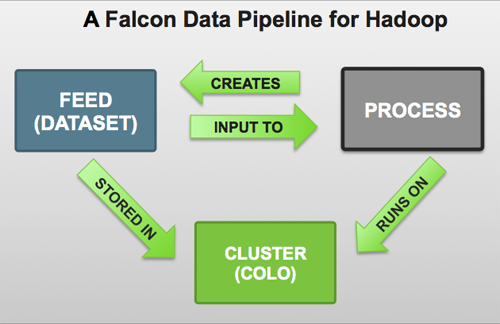
Each pipeline consists of XML pipeline specifications, called entities. These entities act together to provide a dynamic flow of information to load, clean, and process data.
There are three types of entities:
- Cluster
Defines the cluster, including its interfaces, where data and processes are stored.
- Feed
Defines the datasets to be cleaned and processed.
- Process
Defines how the process (such as a Pig or Hive jobs) works with the dataset on top of a cluster. A process consumes feeds, invokes processing logic (including late data handling), and produces further feeds. It also defines the configuration of the Oozie workflow and defines when and how often the workflow should run.
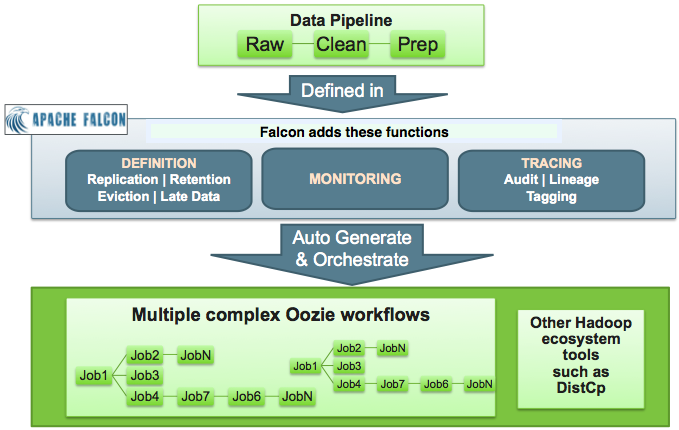
Each entity is defined separately and then linked together to form a data pipeline. Falcon provides predefined policies for data replication, retention, late data handling, retry, and replication. These sample policies are easily customized to suit your needs.
These entities can be reused many times to define data management policies for Oozie jobs, Spark jobs, Pig scripts, and Hive queries. For example, Falcon data management policies become Oozie coordinator jobs:
![[Note]](../common/images/admon/note.png) | Note |
|---|---|
The auditing and lineage functionality is part of data governance and is not addressed in this documentation. See the Data Governance Guide for information about auditing and lineage. |