
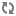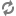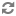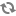
Trident Aggregations
In addition to functions and filters, Trident defines a number of aggregator interfaces that allow topologies to combine tuples.
There are three types of Trident aggregators:
CombinerAggregatorReducerAggregatorAggregator
As with functions and filters, Trident aggregations are applied to
streams via methods in the Stream class, namely aggregate(),
partitionAggregate(), and
persistentAggregate().
CombinerAggregator
The CombinerAggregator interface is used to combine a set of
tuples into a single field. In the word count example the Count class is an
example of a CombinerAggregator that summed field values across a partition. The
CombinerAggregator interface is as follows:
public interface CombinerAggregator<T> extends Serializable {
T init(TridentTuple tuple);
T combine(T val1, T val2);
T zero();
}When executing Aggregator, Storm calls init() for
each tuple, and calls combine() repeatedly to process each tuple in
the partition.
When complete, the last value returned by combine() is emitted.
If the partition is empty, the value of zero() will be
emitted.
ReducerAggregator
The ReducerAggregator interface has the following interface
definition:
public interface ReducerAggregator<T> extends Serializable {
T init();
T reduce(T curr, TridentTuple tuple);
}When applying a ReducerAggregator to a partition, Storm first
calls the init() method to obtain an initial value. It then calls
the reduce() method repeatedly, to process each tuple in the
partition. The first argument to the reduce() method is the current
cumulative aggregation, which the method returns after applying the tuple to the
aggregation. When all tuples in the partition have been processed, Storm emits
the last value returned by reduce().
Aggregator
The Aggregator interface represents the most general form of
aggregation operations:
public interface Aggregator<T> extends Operation {
T init(Object batchId, TridentCollector collector);
void aggregate(T val, TridentTuple tuple, TridentCollector collector);
void complete(T val, TridentCollector collector);
}A key difference between Aggregator and other Trident aggregation
interfaces is that an instance of TridentCollector is passed as a
parameter to every method. This allows Aggregator implementations to emit tuples
at any time during execution.
Storm executes Aggregator instances as follows:
Storm calls the
init()method, which returns an objectTrepresenting the initial state of the aggregation.Tis also passed to theaggregate()andcomplete()methods.Storm calls the
aggregate()method repeatedly, to process each tuple in the batch.Storm calls
complete()with the final value of the aggregation.
The word count example uses the built-in Count class that
implements the CombinerAggregator interface. The Count
class could also be implemented as an Aggregator:
public class Count extends BaseAggregator<CountState> {
static class CountState {
long count = 0;
}
public CountState init(Object batchId, TridentCollector collector) {
return new CountState();
}
public void aggregate(CountState state, TridentTuple tuple, TridentCollector collector) {
state.count+=1;
}
public void complete(CountState state, TridentCollector collector) {
collector.emit(new Values(state.count));
}
}