
Chapter 1. Optimizing an Apache Hive Data Warehouse
Using a Hive-based data warehouse requires setting up the appropriate environment for your needs. After you establish the computing paradigm and architecture, you can tune the data warehouse infrastructure, interdependent components, and your client connection parameters to improve the performance and relevance of business intelligence (BI) and other data-analytic applications.
Tuning Hive and other Apache components that run in the background to support processing of HiveQL is particularly important as the scale of your workload and database volume increases. When your applications query data sets that constitute a large-scale enterprise data warehouse (EDW), tuning the environment and optimizing Hive queries are often part of an ongoing effort by IT or DevOps teams to ensure service-level agreement (SLA) benchmarks or other performance expectations.
Increasingly, most enterprises require that Hive queries run against the data warehouse with low-latency analytical processing, which is often referred to as LLAP by Hortonworks. LLAP of real-time data can be further enhanced by integrating the EDW with the Druid business intelligence engine.
![[Tip]](../common/images/admon/tip.png) | Tip |
|---|---|
The best approach is to use Apache Ambari to configure and monitor applications and queries that run on a Hive data warehouse. These tips are described throughout this guide. |
Hive Processing Environments
The environment that you use to process queries and return results can depend on one or more factors, such as the capacity of your system resources, how in-depth you want to analyze data, how quickly you want queries to return results, or what tradeoffs that you can accept to favor one model over another.
Overall Architecture
A brief overview of the components and architecture of systems using Hive EDW for data processing is in the Hive Architectural Overview of HDP 2.5. With a few exceptions, the architecture information there applies to both batch processing and LLAP of Hive queries. However, there are some differences in the way the components of an environment processing batch workloads operate from the functioning of the same components in a Hive LLAP environment.
Dependencies for Optimal Hive Query Processing
Increasingly, enterprises want to run SQL workloads that return faster results than batch processing can provide. Hortonworks Data Platform (HDP) supports Hive LLAP, which enables application development and IT infrastructure to run queries that return real-time or near-real-time results. Use cases for implementing this technology include environments where users of business intelligence (BI) tools or web dashboards need to accelerate analysis of data stored in a Hive EDW.
A performance benchmark that enterprises increasingly want to reach with data analytics applications is support for interactive queries. Interactive queries are queries on Hive data sets that meet low-latency benchmarks that are variably gauged but for Hive LLAP in HDP is specified as 15 seconds or less.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
Hive LLAP with Apache Tez utilizes newer technology available in Hive 2.x to be an increasingly needed alternative to other execution engines like MapReduce and earlier implementations of Hive on Tez. Tez runs in conjunction with Hive LLAP to form a newer execution engine architecture that can support faster queries. |
| Important |
|---|---|
The Hive LLAP with Tez engine requires a different Apache Hadoop YARN configuration from the configuration required for environments where Hive on Tez is the execution engine. With Ambari 2.5.0 and later versions, you can more easily enable and configure YARN components that are the foundation of Hive LLAP than you could in previous HDP releases. |
Connectivity to Admission Control (HiveServer2)
HiveServer2 is a service that enables multiple clients to simultaneously execute queries against Hive using an open API driver, such as JDBC or ODBC.
For optimal performance, use HiveServer2 as the connectivity service between your client application and the Hive EDW. HiveServer1 is deprecated because HiveServer2 has improvements for multiclient concurrency and authentication. Also, HiveServer2 is designed to provide better support for open API clients like JDBC and ODBC.
HiveServer2 is one of several architectural components for admission control, which enables optimal Hive performance when multiple user sessions generate asynchronous threads simultaneously. Admission control operates by scaling the Hive processing of concurrent queries to a workload that is suited to the system resources and to the total demand of incoming threads, while holding the other queries for later processing or cancelling the queries if conditions warrant this action. Admission control is akin to “connection pooling” in RDBMS databases.
To optimize Hive performance, you must set parameters that affect admission control according to your needs and system resources.
| Important |
|---|---|
HiveServer2 coordinates admission control in conjunction with YARN and Apache Tez for batch queries and with YARN and the LLAP daemons for interactive queries. |
Execution Engines (Apache Tez and Hive LLAP)
Both the Hive on Tez engine for batch queries and the enhanced Tez + Hive LLAP engine run on YARN nodes.
Tez Execution on YARN
Hive on Tez is an advancement over earlier application frameworks for Hadoop data processing, such as using Hive on MapReduce2 or MapReduce1. The Tez framework is required for high-performance batch workloads. Tez is also part of the execution engine for Hive LLAP.
After query compilation, HiveServer2 generates a Tez graph that is submitted to YARN. A Tez ApplicationMaster (AM) monitors the query while it is running.
The maximum number of queries that can be run concurrently is limited by the number of ApplicationMasters.
Hive LLAP Execution Engine
The architecture of Hive LLAP is illustrated in the following diagram.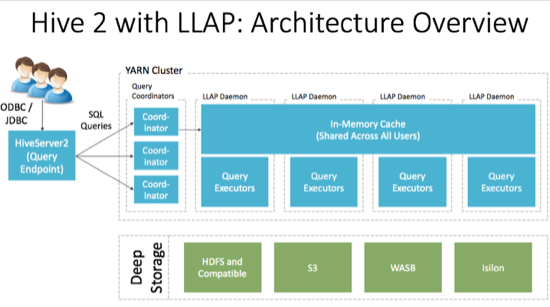
HiveServer2: provides JDBC and ODBC interface, and query compilation
Query coordinators: coordinate the execution of a single query LLAP daemon: persistent server, typically one per node. This is the main differentiating component of the architecture, which enables faster query runtimes than earlier execution engines.
Query executors: threads running inside the LLAP daemon
In-memory cache: cache inside the LLAP daemon that is shared across all users
Workload Management with Queues and Containers (Hive, YARN, and Tez)
Batch Processing
Each queue must have the capacity to support one complete Tez Application, as defined by its ApplicationMaster (AM). Consequently, the maximum number of queries that can be run concurrently is also limited by the number of Apache Tez Application Masters.
A Hive-based analytic application relies on execution resources called YARN containers. Containers are defined by the Hive configuration. The number and longevity of containers that reside in your environment depend on whether you want to run with batch workloads or enable Hive LLAP in HDP.
Interactive Workloads
Interactive workloads operate with YARN and queues differently from the way that batch workloads manage workloads.
When using the Hive LLAP on Tez engine, Admission Control is handled differently than for earlier Hive on Tez implementations. Resources are managed by Hive LLAP globally, rather than each Tez session managing its own.
Hive LLAP has its own resource scheduling and pre-emption built in that doesn't rely on YARN. As a result, a single queue is needed to manage all LLAP resources. In addition, each LLAP daemon runs as a single YARN container.
SQL Planner and Optimizer (Apache Hive and Apache Calcite)
A cost-based optimizer (CBO) generates more efficient query plans. In Hive, the CBO is enabled by default, but it requires that column statistics be generated for tables. Column statistics can be expensive to compute so they are not automated. Hive has a CBO that is based on Apache Calcite and an older physical optimizer. All of the optimizations are being migrated to the CBO. The physical optimizer performs better with statistics, but the CBO requires statistics.
Storage Formats
Hive supports various file formats. You can write your own SerDes (Serializers, Deserializers) interface to support new file formats.
| Tip |
|---|---|
The Optimized Row Columnar (ORC) file format for data storage is recommended because this format provides the best Hive performance overall. |
Storage Layer (Example: HDFS Filesystem)
While a Hive EDW can run on one of a variety of storage layers, HDFS and Amazon S3 are among the most prevalently used and known filesystems for data analytics that run in the Hadoop stack. Amazon S3 is a commonly used filesystem used for a public cloud infrastructure.
A Hive EDW can store data on other filesystems, including WASB and ADLS.
Depending on your environment, you can tune the filesystem to optimize Hive performance by configuring compression format, stripe size, partitions, and buckets. Also, you can create bloom filters for columns frequently used in point lookups.
Setting up Hive LLAP
| Important |
|---|---|
Using Ambari 2.5.0+ to enable Hive LLAP and configure most of its basic parameters is highly recommended for most users. Ambari not only has a GUI to ease the tasks, but also contains multiple wizards that can automatically tune interactive query property settings to suit your environment. |
While most of the Hive LLAP installation and configuration steps can be completed in
Ambari, you must manually configure two properties in the yarn-site.xml
file before sliding the Enable Interactive Query toggle to
"Yes." Then there are two paths for enabling Hive LLAP using Ambari: Typical Setup and
Advanced Setup. Typical Setup is recommended for most users because it requires less
decision-making and leverages more autotuning features of Ambari than the Advanced Setup.
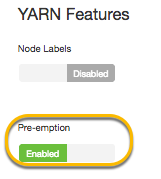
Enabling YARN Preemption for Hive LLAP
About this Task
You must enable and configure YARN preemption, which directs the Capacity Scheduler to position a Hive LLAP queue as the top-priority workload to run among cluster node resources. See YARN Preemption for more information about how YARN preemption functions.
Steps
In Ambari, select Services > YARN > Configs tab > Settings subtab.
Set the Pre-emption slider of the YARN Features section to Enabled:
Click the Advanced subtab.
Set the
yarn-site.xmlproperties required to enable Hive LLAP.Open the drop-down menu.

Use the Add Property ... link in the GUI to add and configure the properties as documented in the following table.
Table 1.1. Manual Configuration of Properties for Enabling Hive LLAP
Property Name Recommended Setting yarn.resourcemanager.monitor.capacity.preemption.natural_termination_factor1yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_roundCalculate the value by dividing 1 by the number of cluster nodes. Enter the value as a decimal.
Example: If your cluster has 20 nodes, then divide 1 by 20 and enter
0.05as the value of this property setting.
Click in the upper right area of the window.
Next Step
Complete either the Enable Hive LLAP: Typical Setup task or the Enable Hive LLAP: Advanced Setup in Ambari in the following sections.
Enable Hive LLAP: Typical Setup
About this Task
Follow this procedure if you are new to Hive LLAP or prefer to let autotuning features of Ambari configure interactive queries.
Prerequisites
Installation of Ambari 2.5.x
The Hive Service and other interdependencies as prompted in Ambari must be running.
YARN preemption must be enabled and configured as documented in the Enabling YARN Preemption for Hive LLAP section above.
If enabled, you must disable maintenance mode for the Hive service and target host for HiveServer Interactive (HSI); otherwise, enabling LLAP fails to install HSI. Alternatively, you need to install HiveServer Interactive on the Ambari server as follows:
curl -u admin:<password> -H "X-Requested-By:ambari" -i -X POST http://host:8080/api/v1/clusters/<cluster_name>/hosts/<host_name>/host_components/HIVE_SERVER_INTERACTIVE
Steps
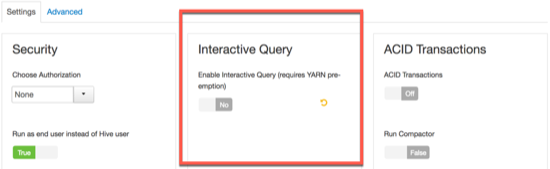
Select the Hive service in the Ambari dashboard.
Click the Configs tab.
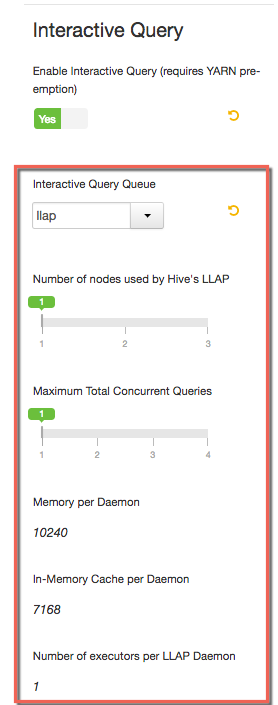
In the Settings tab, locate the Interactive Query section and set the Enable Interactive Query slider to .
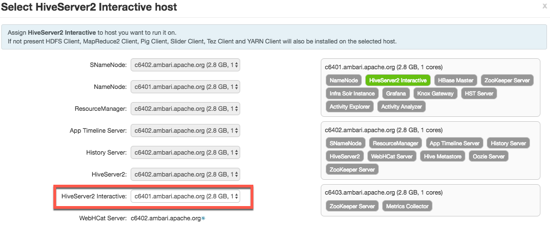
Select the server to host the HiveServer2 Interactive instance in the HiveServer2 Interactive field. In most cases, you can keep the default server host assignment.
Click in the Select HiverServer2 Interactive host window.
When the Settings subtab opens again, review the additional configuration fields that appear in the Interactive Query section of the window:
Retain as the setting in the drop-down menu. This setting dedicates all the LLAP daemons and all the YARN ApplicationMasters of the system to the single, specified queue.
Set the Number of nodes used by Hive LLAP slider to the number of cluster nodes on which to run Hive LLAP. LLAP automatically deploys to the nodes, and you do not need to label the nodes.
Set the Maximum Total Concurrent Queries slider to the maximum number of concurrent LLAP queries to run. The Ambari wizard calculates and displays a range of values in the slider based on the number of nodes that you selected and the number of CPUs in the Hive LLAP cluster.
Review the following settings, which are autogenerated for informational purposes only. (No interactive elements allow you to directly change the values.)
Memory per Daemon: YARN container size for each daemon (MB) In-Memory Cache per Daemon: Size of the cache in each container (MB) Number of executors per LLAP Daemon: The number of executors per daemon: for example, the number of fragments that can execute in parallel on a daemon Review the property settings outside the Interactive Query section of the window to learn how the Hive LLAP instance is configured. The Ambari wizard calculates appropriate values for most other properties on the Settings subtab, based on the configurations in the Interactive Query section of the window.
Important When enabling Hive LLAP, the Run as end user instead of Hive user slider on the Settings subtab has no effect on the Hive instance. If you set the slider to
True, this property switches from Hive user to end user only when you run Hive in batch-processing mode.Click the button near the top of the Ambari window.
If the window appears, review recommendations and adjust if you know settings need to be changed for your environment.
Click > .
Next Steps
Connect Clients to a Dedicated HiveServer2 Endpoint
| Tip |
|---|---|
Hive View 2.0 in Ambari integrates with the general availability release of Hive LLAP. If you
plan to use Hive View 2.0 with a Hive LLAP instance, ensure that the Use
Interactive Mode property of Manage Ambari Views is set to
|
Enable Hive LLAP: Advanced Setup
About this Task
If you are a more advanced user of Hive LLAP and want to use a customized query queue rather than the default llap queue, then use the following procedure to enable interactive queries.
Prerequisites
Installation of Ambari 2.5.x
The Hive Service and other interdependencies as prompted in Ambari must be running.
Your customized interactive query queue must be set up. For more information, see the Capacity Scheduler chapter of the Hortonworks YARN Resource Management Guide.
Complete the tasks in the Queues for Hive LLAP Sites section.
YARN preemption must be enabled and configured as documented in the Enabling YARN Preemption for Hive LLAP section above.
Steps
Select the Hive service in the Ambari dashboard.
Click the Configs tab.
In the Settings tab, locate the Interactive Query section and set the Enable Interactive Query slider to .
Select the server to host the HiveServer2 Interactive instance in the HiveServer2 Interactive field. In most cases, you can accept the default server host assignment.
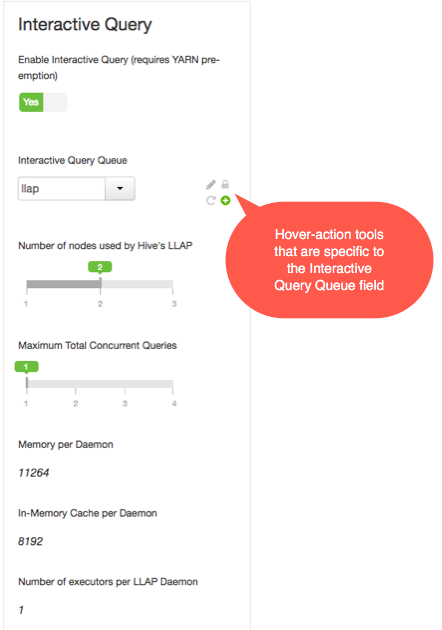
Select a predefined queue to use for the Hive LLAP cluster.
Hover over the field to display the hover-action tools, as illustrated in the following screenshot.
Click the Edit (pencil icon) hover action to make the field a drop-down list.
Select the queue for Hive LLAP. This setting dedicates all the LLAP daemons and all the YARN ApplicationMasters of the system to the single, specified queue.
Important Hover-action tools also appear when you move your pointer to hover over other editable elements of the Ambari window.
Set the Number of nodes used by Hive LLAP slider to the number of cluster nodes on which to run Hive LLAP. LLAP automatically deploys to the nodes, and you do not need to label the nodes.
Set the Maximum Total Concurrent Queries slider to the maximum number of concurrent Hive LLAP queries to run. The Ambari wizard calculates and displays a range of values in the slider based on the number of nodes that you selected and the number of CPUs in the Hive LLAP cluster. If you want to set the value outside the slider range, move your pointer over the field to enable the hover actions and select the Override tool.
Review the following settings, which are autogenerated for informational purposes only. (No interactive elements allow you to directly change the values.)
Memory per Daemon: YARN container size for each daemon (MB) In-Memory Cache per Daemon: Size of the cache in each container (MB) Number of executors per LLAP Daemon: The number of executors per daemon: for example, the number of fragments that can execute in parallel on a daemon Review the property settings outside the Interactive Query section of the window to learn how the Hive LLAP instance is configured. The Ambari wizard calculates appropriate values for most other properties on the Settings tab, based on the configurations in the Interactive Query section of the window.
Important When enabling Hive LLAP, the Run as end user instead of Hive user slider on the Settings tab has no effect on the Hive instance. If you set the slider to
True, this property switches from Hive user to end user only when you run Hive in batch-processing mode.Click the button near the top of the Ambari window.
If the Dependent Configurations window appears, review recommendations and adjust if you know settings need to be changed for your environment.
Click > .
Next Steps
Connect Clients to a Dedicated HiveServer2 Endpoint
| Tip |
|---|---|
Hive View 2.0 in Ambari integrates with the general availability release of Hive LLAP. If you
plan to use Hive View 2.0 with a Hive LLAP instance, ensure that the Use
Interactive Mode property of Manage Ambari Views is set to
|
Connect Clients to a Dedicated HiveServer2 Endpoint
About this Task
Hortonworks supports Hive JDBC drivers that enable you to connect to HiveServer2 so that you can query, analyze, and visualize data stored in the Hortonworks Data Platform. In this task, you get the autogenerated HiveServer2 JDBC URL so that you can connect your client to the Hive LLAP instance.
| Important |
|---|---|
Do not use Hive CLI as your JDBC client for Hive LLAP queries. |
Prerequisite
Complete setup of Hive LLAP with Ambari, including restarting the Hive Service after saving the Enable Interactive Query settings.
Steps
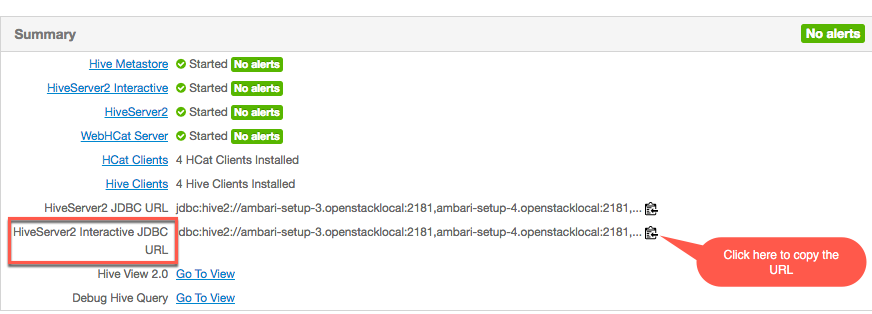
Select the Hive service in the Ambari dashboard.
Click the Summary tab.
Use the clipboard icon to the right of the HiveServer2 Interactive JDBC URL value to copy the URL.
Paste the URL into a JDBC client that you use to query the Hive EDW. For example, the client could be a BI tool or Beeline.
Next Steps
You can run your queries in the client. Hive LLAP should be booted and ready to use.
If query performance is too slow, see the following chapters of this guide.
Multiple Hive LLAP Instances in a Single HDP Cluster
If you want to deliver LLAP to multiple tenants that use a single HDP cluster, you can clone an existing HiveServer2 Interactive configuration of an Ambari-deployed LLAP instance and adjust the configuration to effectively create a new LLAP instance on the same cluster. With the following steps you can manipulate the HiveServer2 Interactive configurations so that you can run a separate LLAP instance on the same cluster. The steps can be repeated to create more than one additional LLAP instance. Because each LLAP instance runs on its own YARN queue, you can run queries through multiple LLAP instances on a single cluster simultaneously.
Procedure 1.1. Setting up Multiple LLAP Instances on the Same HDP Cluster
Prerequisites
Ambari-deployed Hive LLAP instance.
A separate YARN queue for a new LLAP instance with enough capacity to launch a Hive LLAP application, plus a sufficient number of Tez Application Masters to query the Hive LLAP instance.
In Ambari ensure that the Enable Interactive Query slider is set to Yes. This setting enables HiveServer2 Interactive.
Access the HiveServer2 Interactive node running the pre-existing LLAP instance:
Select the Hosts tab of Ambari.
Use the search field to locate the HiveServer2 Interactive node.
On a command-line, log in to the node as root.
Clone the configuration of the HiveServer2 Interactive node. Choose a name for the clone that identifies the nature of the configuration and log files for the new Hive LLAP setup. The steps of this procedure assume that a second Hive LLAP instance is created, so the name myhive2 is used continuously in the following examples.
Run the following commands:
HIVE_INSTANCE_NAME=myhive2
mkdir -p /etc/hive2/conf.${HIVE_INSTANCE_NAME}
cd /etc/hive2/conf.${HIVE_INSTANCE_NAME}
cp -p /etc/hive2/2.6.1*/0/conf.server/*
mkdir -p /var/log/hive.${HIVE_INSTANCE_NAME}
chown hive:hadoop /var/log/hive.${HIVE_INSTANCE_NAME}
Adjust the configuration files for the new HiveServer2 Interactive instance:
Change HIVE_CONF_DIR in
/etc/hive2/conf.${HIVE_INSTANCE_NAME}/hive-env.shto the new configuration path.Example: HIVE_CONF_DIR=/etc/hive2/conf.myhive2
Change the values of the following properties in the
/etc/hive2/conf.${HIVE_INSTANCE_NAME}/hive-site.xmlfile:hive.server2.tez.default.queues: change the value to the queue where container jobs run or to default. If you do not change the value of hive.server2.tez.default.queues, there is not enough capacity for jobs to run in the environment that you are creating.
hive.server2.zookeeper.namespace: change the value to hiveserver2-${HIVE_INSTANCE_NAME}, substituting the variable with your real value. For example, hiveserver2-myhive2.
hive.server2.thrift.port: replace the default value (10000 in Hive 1; 10500 in Hive 2) with a number that does not clash with the port number of an existing HiveServer2 instance
hive.server2.thrift.http.port: replace the default value (10001 in Hive 1; 10501 in Hive 2) with a number that does not clash with the port number of an existing HiveServer2 instance
hive.server2.webui.port: replace the default value (10002 in Hive 1; 10502 in Hive 2) with a number that does not clash with the port number of an existing HiveServer2 instance
Change the value of property.hive.log.dir in the
hive-log4j2.propertiesfile to the new HiveServer2 configuration path.Example: property.hive.log.dir = /var/log/hive.myhive2
Create a Hive LLAP package for your application by following the steps in Installing LLAP on an Unsecured Cluster or Installing LLAP on a Secured Cluster, depending on the environment that you have. Ensure that the
--queueoption is included in the command and that it directs the execution to the YARN queue to be used for the new LLAP instance. The following is an example of an executing command:hive --service llap --name llap_extra --queue my_queue --instances 5 \ --cache 50000m --xmx 50000m --size 100000m --executors 12 --loglevel WARN \ --args "-XX:+UseG1GC -XX:+ResizeTLAB -XX:+UseNUMA -XX:-ResizePLAB"
Launch LLAP using the
run.shfile that was created after you completed Step 5.Example:
sh llap-slider-${DATE}/run.shConfirm the Hive LLAP instance is running. Wait a moment for the LLAP application to start within YARN. After startup of the application you can validate that the LLAP instance is running properly using the llapstatus command.
Example of llapstatus command:
/usr/hdp/current/hive-server2-hive2/bin/hive --service llapstatus -w -r 0.8 -i 2 -t 200
If LLAP started successfully, you see output similar to the following message:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-159/hive2/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-159/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] WARN conf.HiveConf: HiveConf of name hive.llap.daemon.service.ssl does not exist WARN conf.HiveConf: HiveConf hive.llap.daemon.vcpus.per.instance expects INT type value LLAPSTATUS WatchMode with timeout=200 s -------------------------------------------------------------------------------- LLAP Application running with ApplicationId=application_1507473809953_0012 -------------------------------------------------------------------------------- LLAP Application running with ApplicationId=application_1507473809953_0012 -------------------------------------------------------------------------------- { "amInfo" : { "appName" : "llap1", "appType" : "org-apache-slider", "appId" : "application_1507473809953_0012", "containerId" : "container_e01_1507473809953_0012_01_000001", "hostname" : "ctr-e134-1499953498516-207726-02-000006.hwx.site", "amWebUrl" : "http://ctr-e134-1499953498516-207726-02-000006.hwx.site:44549/" }, "state" : "RUNNING_ALL", "originalConfigurationPath" : "hdfs://ctr-e134-1499953498516-207726-02-000010.hwx.site:8020/user/hive/.slider/cluster/llap1/snapshot", "generatedConfigurationPath" : "hdfs://ctr-e134-1499953498516-207726-02-000010.hwx.site:8020/user/hive/.slider/cluster/llap1/generated", "desiredInstances" : 1, "liveInstances" : 1, "launchingInstances" : 0, "appStartTime" : 1507542670971, "runningThresholdAchieved" : true, "runningInstances" : [ { "hostname" : "ctr-e134-1499953498516-207726-02-000005.hwx.site", "containerId" : "container_e01_1507473809953_0012_01_000002", "logUrl" : "http://ctr-e134-1499953498516-207726-02-000005.hwx.site:54321/node/containerlogs/container_e01_1507473809953_0012_01_000002/hive", "statusUrl" : "http://ctr-e134-1499953498516-207726-02-000005.hwx.site:15002/status", "webUrl" : "http://ctr-e134-1499953498516-207726-02-000005.hwx.site:15002", "rpcPort" : 44315, "mgmtPort" : 15004, "shufflePort" : 15551, "yarnContainerExitStatus" : 0 } ] }Start the new HiveServer2 instance by running the following command:
export HIVE_CONF_DIR=/etc/hive2/conf.${HIVE_INSTANCE_NAME} \ /usr/hdp/current/hive-server2-hive2/bin/hive --service hiveserver2For validation purposes, run this HiveServer2 instance in the foreground until you confirm it is functioning in the next step.
Validate the HiveServer2 instance started and check its version by running the select version() command.
Command example:
beeline \ -u "jdbc:hive2://hs2host.example.com:port/" \ -e "select version()"Output example:
The following sample output assumes that the hive.server2.thrift.port property in Step 4 was set to 20500.
beeline -u "jdbc:hive2://ambari.example.com:20500/" -e "select version()" Connecting to jdbc:hive2://ambari.example.com:20500/ Connected to: Apache Hive (version 2.1.0.2.6.1.0-129) Driver: Hive JDBC (version 1.2.1000.2.6.1.0-129) Transaction isolation: TRANSACTION_REPEATABLE_READ DEBUG : Acquired the compile lock INFO : Compiling command(queryId=hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74): select version() INFO : We are setting the hadoop caller context from HIVE_SSN_ID:917c22bf-9998-413d-88c1-4b641391e060 to hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74 INFO : Semantic Analysis Completed INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:string, comment:null)], properties:null) INFO : Completed compiling command(queryId=hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74); Time taken: 0.136 seconds INFO : We are resetting the hadoop caller context to HIVE_SSN_ID:917c22bf-9998-413d-88c1-4b641391e060 INFO : Concurrency mode is disabled, not creating a lock manager INFO : Setting caller context to query id hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74 INFO : Executing command(queryId=hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74): select version() INFO : Resetting the caller context to HIVE_SSN_ID:917c22bf-9998-413d-88c1-4b641391e060 INFO : Completed executing command(queryId=hive_20170628220829_dbb26dfe-0f65-4492-8b8c-fa1469065f74); Time taken: 0.033 seconds INFO : OK DEBUG : Shutting down query select version() +--------------------------------------------------------------+--+ | _c0 | +--------------------------------------------------------------+--+ | 2.1.0.2.6.1.0-129 rf65a7fce6219dbd86a9313bb37944b89fa3551b1 | +--------------------------------------------------------------+--+ 1 row selected (0.345 seconds) Beeline version 1.2.1000.2.6.1.0-129 by Apache Hive Closing: 0: jdbc:hive2://ambari.example.com:20500/
You can also choose to use the ZooKeeper endpoint, based on the value of the hive.server2.zookeeper.namespace property.
Example:
beeline \ -u "jdbc:hive2://ambari.example.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-myhive2" \ -e "select version()"
Run HiveServer2 in the background after validation.
Command example:
su - hive export HIVE_CONF_DIR=/etc/hive2/conf.${HIVE_INSTANCE_NAME} nohup /usr/hdp/current/hive2-server2/bin/hiveserver2 \ -hiveconf hive.metastore.uris=" " -hiveconf hive.log.file=hiveserver2.log \ >/var/log/hive/hiveserver2.out 2> /var/log/hive/hiveserver2err.log &
New HiveServer2 Instances in a Kerberized Cluster
The new HiveServer2 instance that was created in the procedure above points to the same keytab and uses
the same service principal as the source instance that was cloned. If you need this instance to use a separate keytab or principal,
make these additional changes in the hive-site.xml file.