
Chapter 7. Real-Time Data Analytics with Druid
Druid is an open-source data store designed for online analytical processing (OLAP) queries on event data. Druid supports the following data analytics features:
Streaming data ingestion
Real-time queries
Scalability to trillions of events and petabytes of data
Sub-second query latency
These traits make this data store particularly suitable for enterprise-scale business intelligence (BI) applications in environments that require minimal latency. With Druid you can have applications running interactive queries that "slice and dice" data in motion.
A common use case for Druid is to provide a data store that can return BI about streaming data that comes from user activity on a website or multidevice entertainment platform, from consumer events sent over by a data aggregator, or from any other large-scale set of relevant transactions or events from Internet-connected sources.
Druid is licensed under the Apache License, version 2.0.
Content Roadmap
The following table provides links to Druid information resources. The table points to resources that are not contained in this HDP Data Access Guide.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
The hyperlinks in the table and many others throughout this documentation jump to content published on the druid.io site. Do not download any Druid code from this site for installation in an HDP cluster. Instead, install by selecting Druid as a Service in an Ambari-asssisted HDP installation, as described in Installing and Configuring Druid. |
Table 7.1. Druid Content Roadmap in Other Sources
| Type of Information | Resources | Description |
|---|---|---|
| Introductions | About Druid (Source: druid.io) | Introduces the feature highlights of Druid, and explains in which environments the data store is best suited. The page also links to comparisons of Druid against other common data stores. |
|
(Source: druid.io) |
This page is the portal to the druid.io technical documentation. While the body of this page describes some of the main technical concepts and components, the right-side navigation pane outlines and links to the topics in the druid.io documentation. | |
|
Druid: A Real-time Analytical Data Store (Source: druid.io) | This white paper describes the Druid architecture in detail, performance benchmarks, and an overview of Druid issues in a production environment. The extensive References section at the end of the document point to a wide range of information sources. | |
| Tutorial | (Source: druid.io) | A getting started tutorial that walks you through a Druid package, installation, and loading and querying data. The installation of this tutorial is for instructional purposes only and not intended for use in a Hortonworks Hadoop cluster. |
Developing on Druid | (Source: druid.io) |
Provides an overview of major Druid components to help developers who want to code applications that use Druid-ingested data. The web page links to another about segments, which is an essential entity to understand when writing applications for Druid. |
| Data Ingestion |
(Source: druid.io) |
These two pages introduce how Druid can ingest data from both static files and real-time streams. |
Queries of Druid Data | (Source: druid.io) |
Describes the method for constructing queries, supported query types, and query error messages. |
| Best Practices | (Source: druid.io) |
A list of tips and FAQs. |
Architecture
Druid offers streaming ingestion and batch ingestion to support both of these data analytics modes. A Druid cluster consists of several Druid node types and components. Each Druid node is optimized to serve particular functions. The following list is an overview of Druid node types:
Realtime nodes ingest and index streaming data that is generated by system events. The nodes construct segments from the data and store the segments until these segments are sent to historical nodes. The realtime nodes do not store segments after the segments are transferred.
Historical nodes are designed to serve queries over immutable, historical data. Historical nodes download immutable, read-optimized Druid segments from deep storage and use memory-mapped files to load them into available memory. Each historical node tracks the segments it has loaded in ZooKeeper and transmits this information to other nodes of the Druid cluster when needed.
Broker nodes form a gateway between external clients and various historical and realtime nodes. External clients send queries to broker nodes. The nodes then break each query into smaller queries based on the location of segments for the queried interval and forwards them to the appropriate historical or realtime nodes. Broker nodes merge query results and send them back to the client. These nodes can also be configured to use a local or distributed cache for caching query results for individual segments.
Coordinator nodes mainly serve to assign segments to historical nodes, handle data replication, and to ensure that segments are distributed evenly across the historical nodes. They also provide a UI to manage different datasources and configure rules to load data and drop data for individual datas sources. The UI can be accessed via Ambari Quick Links.
Middle manager nodes are responsible for running various tasks related to data ingestion, realtime indexing, segment archives, etc. Each Druid task is run as a separate JVM.
Overlord nodes handle task management. Overlord nodes maintain a task queue that consists of user-submitted tasks. The queue is processed by assigning tasks in order to the middle manager nodes, which actually run the tasks. The overlord nodes also support a UI that provides a view of the current task queue and access to task logs. The UI can be accessed via Ambari Quick Links for Druid.
![[Tip]](../common/images/admon/tip.png) | Tip |
|---|---|
For more detailed information and diagrams about the architecture of Druid, see Druid: A Real-time Analytical Data Store Design Overview on druid.io. |
Installing and Configuring Druid
Use Apache Ambari to install Druid. Manual installation of Druid to your HDP cluster is not recommended.
After you have a running Ambari server set up for HDP, you can install and configure Druid for your Hadoop cluster just like any other Ambari Service.
| Important |
|---|---|
You must use Ambari 2.5.0 or a later version to install and configure Druid. Earlier versions of Ambari do not support Druid as a service. Also, Druid is available as an Ambari Service when you run with the cluster with HDP 2.6.0 and later versions. |
| If you need to install and start an Ambari server, see the Getting Ready section of the Apache Ambari Installation Guide. |
| If a running Ambari server is set up for HDP, see Installing, Configuring, and Deploying a HDP Cluster and the following subsections. While you can install and configure Druid for the Hadoop cluster just like any other Ambari Service, the following subsections contain Druid-specific details for some of the steps in the Ambari-assisted installation. |
Interdependencies for the Ambari-Assisted Druid Installation
To use Druid in a real-world environment, your Druid cluster must also have access to other resources to make Druid operational in HDP:
ZooKeeper: A Druid instance requires installation of Apache ZooKeeper. Select ZooKeeper as a Service during Druid installation. If you do not, the Ambari installer does not complete. ZooKeeper is used for distributed coordination among Druid nodes and for leadership elections among coordinator and overlord nodes.
Deep storage: HDFS or Amazon S3 can be used as the deep storage layer for Druid in HDP. In Ambari, you can select HDFS as a Service for the deep storage of data. Aternatively, you can set up Druid to use Amazon S3 as the deep storage layer by setting the
druid.storage.typeproperty tos3. The cluster relies on the distributed filesystem to store Druid segments so that there is permanent backup of the data.Metadata storage: The metadata store is used to persist information about Druid segments and tasks. MySQL, Postgres, and Derby are supported metadata stores. You have the opportunity to select the metadata database when you install and configure Druid with Ambari.
Batch execution engine: Select YARN + MapReduce2 as the appropriate execution resource manager and execution engine, respectively. Druid hadoop index tasks use MapReduce jobs for distributed ingestion of large amounts of data.
(Optional) Druid metrics reporting: If you plan to monitor Druid performance metrics using Grafana dashboards in Ambari, select Ambari Metrics System as a Service.
| Tip |
|---|---|
If you plan to deploy high availability (HA) on a Druid cluster, review the High Availability in Druid Clusters section below to learn what components to install and how to configure the installation so that the Druid instance is primed for a HA environment. |
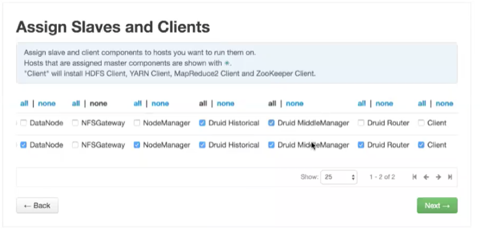
Assigning Slave and Client Components
On the Assign Slaves and Clients window of Ambari, generally you should select Druid Historical and Druid MiddleManager for multiple nodes. (You may also need to select other components that are documented in the Apache Ambari Installation Guide.)The purpose of these components are as follows:
| Druid Historical: Loads data segments. |
| Druid MiddleManager: Runs Druid indexing tasks. |
Configuring the Druid Installation
Use the Customize Services window of Ambari installer to finalize the configuration of Druid.
Select Druid > Metadata storage type to
access the drop-down menu for choosing the metadata storage database. When you click
the drop-down menu, notice the tips about the database types that appear in the GUI. 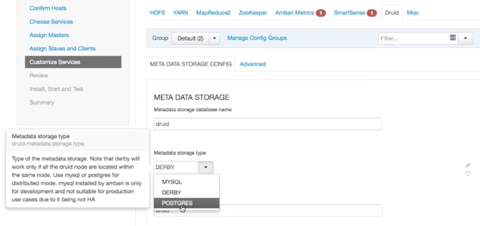
To proceed with the installation after selecting a database, enter your
admin password in the Metadata storage
password fields. If MySQL is your metadata storage database, also
follow the steps in the Setting up MySQL for Druid
section below.
Toggle to the Advanced tab. Ambari has Stack Advisor, which is configuration wizard. Stack Advisor populates many configuration settings based on the your previously entered settings and your environment. Although Stack Advisor provides many default settings for Druid nodes and other related entities in the cluster, you might need to manually tune the configuration parameter settings. Review the following druid.io documentation to determine if you need to change any default settings and how other manual settings operate:
Setting up MySQL for Druid
Complete the following task only if you chose MySQL as the metadata store for Druid.
On the Ambari Server host, stage the appropriate MySQL connector for later deployment.
Install the connector.
RHEL/CentOS/Oracle Linux
yum install mysql-connector-java*SLES
zypper install mysql-connector-java*Debian/Ubuntu
apt-get install libmysql-javaConfirm that
mysql-connector-java.jaris in the Java share directory.ls /usr/share/java/mysql-connector-java.jarMake sure the Linux permission of the
.JARfile is644.Execute the following command:
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
Create the Druid database.
The Druid database must be created prior using the following command:
# mysql -u root -pCREATE DATABASE <DRUIDDATABASE> DEFAULT CHARACTER SET utf8;replacing <DRUIDDATABASE> with the Druid database name.
Create a Druid user with sufficient superuser permissions.
Enter the following in the MySQL database admin utility:
# mysql -u root -pCREATE USER '<DRUIDUSER>'@'%' IDENTIFIED BY '<DRUIDPASSWORD>';GRANT ALL PRIVILEGES ON <DRUIDDATABASE>.* TO '<DRUIDUSER>'@'%’;FLUSH PRIVILEGES;replacing <DRUIDUSER> with the Druid user name and <DRUIDPASSWORD> with the Druid user password.
Security and Druid
| Important |
|---|---|
Place the Druid endpoints behind a firewall. More robust security features that remove the need to deploy a firewall around Druid are in development. |
You can configure Druid nodes to integrate with a Kerberos-secured Hadoop cluster to enable authentication between Druid and other HDP Services. You can enable the authentication with Ambari 2.5.0+, which lets you secure the HTTP endpoints by including a SPNEGO-based Druid extension. The mechanism by which Kerberos security uses keytabs and principals to strengthen security is described in Kerberos Overview and Kerberos Principals.
A benefit of enabling authentication in this way is that it can connect Druid Web UIs to the core Hadoop cluster while maintaining Kerberos protection. The main Web UIs to use with HDP are the Coordinator Console and the Overlord Console. See Coordinator Node and Overlord Node on the druid.io documentation website for more information about the consoles for these nodes.
Securing Druid Web UIs and Accessing Endpoints
Enabling SPNEGO-based Kerberos authentication between the Druid HTTP endpoints and the rest of the Hadoop cluster requires running the Ambari Kerberos Wizard and manually connecting to Druid HTTP endpoints in a command line. After authenticating successfully to Druid, you can submit queries through the endpoints.
Procedure 7.1. Enabling Kerberos Authentication in Druid
Prerequisite: The Ambari Server and Services on the cluster must have SPNEGO-based Kerberos security enabled. See the Ambari Security Guide if you need to configure and enable SPNEGO-based Kerberos authentication.
| Important |
|---|---|
The whole HDP cluster is down after you configure the Kerberos settings and initialize the Kerberos wizard in the following task. Ensure you can have temporary down-time before completing all steps of this task. |
Follow the steps in Launching the Kerberos Wizard (Automated Setup) until you get to the Configure Identities window of the Ambari Kerberos Wizard. Do not click the button until you adjust advanced Druid configuration settings as follows:
On the Configure Identities window:
Review the principal names, particularly the Ambari Principals on the General tab. These principal names, by default, append the name of the cluster to each of the Ambari principals. You can leave the default appended names or adjust them by removing the
-cluster-namefrom the principal name string. For example, if your cluster is nameddruidand your realm isEXAMPLE.COM, the Druid principal that is created isdruid@EXAMPLE.COM.Select the Advanced tab > drop-down menu.
Use the following table to determine for which Druid properties, if any, you need to change the default settings. In most cases, you should not need to change the default values.
Table 7.2. Advanced Druid Identity Properties of Ambari Kerberos Wizard
Property Default Value Setting Description druid.hadoop.security.spnego.excludedPaths['status']If you want to set more than one path, enter values in the following format:
['/status','/condition']Specify here HTTP paths that do not need to be secured with authentication. A possible use case for providing paths here are to test scripts outside of a production environment.
druid.hadoop.security.spnego.keytabkeytab_dir/spnego.service.keytabThis is the SPNEGO service keytab that is used for authentication.
druid.hadoop.security.spnego.principalHTTP/_HOST@realmThis is the SPNEGO service principal that is used for authentication.
druid.security.extensions.loadlist[druid-kerberos]This indicates the Druid security extension to load for Kerberos.
Confirm your configuration. Optionally, you can download a CSV file of the principals and keytabs that Ambari can automatically create.
Click to proceed with kerberization of the cluster. During the process, all running Services are stopped. Kerberos configuration settings are applied to various components, and keytabs and principals are generated. When the Kerberos process finishes, all Services are restarted and checked.
Tip Initializing the Kerberos Wizard might require a significant amount of time to complete, depending on the cluster size. Refer to the GUI messaging on the screen for progress status.
Procedure 7.2. Accessing Kerberos-Protected HTTP Endpoints
Before accessing any Druid HTTP endpoints, you need to authenticate yourself using Kerberos and get a valid Kerberos ticket as follows:
Log in via the Key Distribution Center (KDC) using the following
kinitcommand, replacing the arguments with your real values:kinit -k -tkeytab_file_pathuser@REALM.COMVerify that you received a valid Kerberos authentication ticket by running the
klistcommand. The console prints aCredentials cachemessage if authentication was successful. An error message indicates that the credentials are not cached.Access Druid with a
curlcommand. When you run the command, you must include the SPNEGO protocol--negotiateargument. (Note that this argument has double hyphens.) The following is an example command. ReplaceanyUser,cookies.txt, andendpointwith your real values.curl --negotiate -u:anyUser -b ~/cookies.txt -c ~/cookies.txt -X POST -H'Content-Type: application/json' http://_endpoint
Submit a query to Druid in the following example
curlcommand format:curl --negotiate -u:anyUser -b ~/cookies.txt -c ~/cookies.txt -X POST -H'Content-Type: application/json' http://broker-host:port/druid/v2/?pretty -d @query.json
High Availability in Druid Clusters
Ambari provides the ability to configure the High Availability (HA) features available in Druid and other HDP Stack Services.
Configuring Druid Clusters for High Availability
HA by its nature requires a multinode structure with somewhat more sophisticated configuration than a cluster without HA. Do not use local storage in an HA environment.
Configure a Cluster with an HDFS Filesystem
Prerequisites
| MySQL or Postgres must be installed as the metadata storage layer. Configure your metadata storage for HA mode to avoid outages that impact cluster operations. See your database documentation. Derby does not support a multinode cluster with HA. |
| At least three ZooKeeper nodes must be dedicated to HA mode. |
Steps
Enable Namenode HA using the wizard as described in Configuring NameNode High Availability
Install the Druid Overlord, Coordinator, Broker, Realtime, and Historical processes on multiple nodes that are distributed among different hardware servers.
Within each Overlord and Coordinator domain, ZooKeeper determines which node is the Active node. The other nodes supporting each process are in Standby state until an Active node stops running and the Standby nodes receive the failover.
Multiple Historical and Realtime nodes also serve to support a failover mechanism. But for Broker and Realtime processes, there are no designated Active and Standby nodes.
Muliple instances of Druid Broker processes is required for HA. Recommendations: Use an external, virtual IP address or load balancer to direct user queries to multiple Druid Broker instances. A Druid Router can also serve as a mechanism to route queries to multiple broker nodes.
Ensure that the replication factor for each datasource is set greater than
1in the Coordinator process rules. If no datasource rule configurations were changed, no action is required because the default value is2.
Leveraging Druid to Accelerate Hive SQL Queries
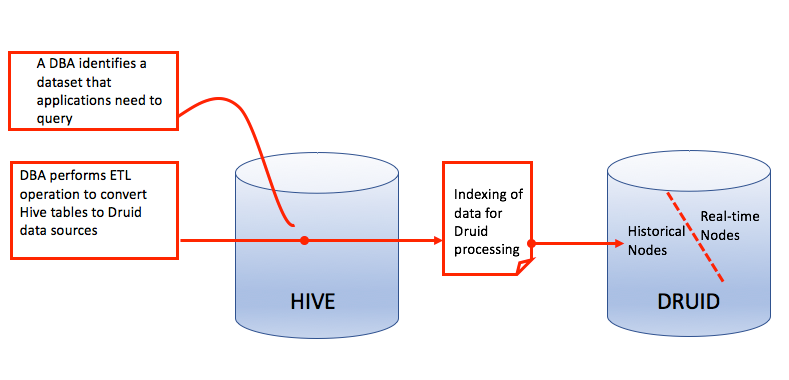
HDP integration of Hive with Druid places a SQL layer on Druid so that applications can efficiently perform analytic queries on both real-time and historical data. After Druid ingests data from a Hive enterprise data warehouse (EDW), the interactive and sub-second query capabilities of Druid can be used to accelerate queries on historical data from the EDW. Hive integration with Druid enables applications such as Tableau to scale while queries run concurrently on both real-time and historical data.
The following figure is an overview of how Hive historical data can be brought into a Druid environment. Queries analyzing Hive-sourced data are run directly on the historical nodes of Druid after indexing between the two databases completes.
| Important |
|---|---|
If Kerberos is enabled on your cluster, then the only way to query Druid datasources that are imported from Hive is to use Hive LLAP daemons. Ensure that the Hive property is set as hive.llap.execution.mode=all. |
How Druid Indexes Hive-Sourced Data
Before you can create Druid datasources using Hive data as your source, you must understand how data of a Hive external table map is mapped to the column orientation and segment files of Druid.
Each Druid segment consists of the following objects to facilitate fast lookup and aggregation:
- Timestamp column
The SQL-based timestamp column is filled in based on how you set the time granularity of imported Hive data and what time range of data is selected in the Hive external table. This column is essential for indexing the data in Druid because Druid itself is a time-series database. The timestamp column must be named
__time.- Dimension columns
The dimension columns are used to set string attributes for search and filter operations. To index a Hive-sourced column as a Druid dimension column, you must cast the column as a string type.
- Metric columns
Metric columns are used to index metrics that are supposed to be used as aggregates or measures. To index a Hive-sourced column as a Druid metric column, you must cast the column as a Hive numeric data type.
The following figure represents an example of how Druid data can be categorized in the three column types.

Transforming Hive Data to Druid Datasources
About this Task
A DBA runs a Hive SQL command invoking the Druid storage handler, specifies the Druid segment granularity, and maps selected Hive columns to Druid column types.
Steps
Put all the Hive data to undergo ETL in an external table.
Run a CREATE TABLE AS SELECT statement to create a new Druid datasource. The following is an example of a statement pushing Hive data to Druid.
Example:
CREATE TABLE ssb_druid_hive STORED BY 'org.apache.hadoop.hive. druid.DruidStorageHandler' TBLPROPERTIES ( "druid.segment.granularity" = "MONTH", "druid.query.granularity" = "DAY") AS SELECT cast(d_year || '-' || d_monthnuminyear || '-' || d_daynuminmonth as timestamp) as `__time`, cast(c_city as string) c_city, cast(c_nation as string) c_nation, cast(c_region as string) c_region, cast(d_weeknuminyear as string) d_weeknuminyear, cast(d_year as string) d_year, cast(d_yearmonth as string) d_yearmonth, cast(d_yearmonthnum as string) d_yearmonthnum, cast(lo_discount as string) lo_discount, cast(lo_quantity as string) lo_quantity, cast(p_brand1 as string) p_brand1, cast(p_category as string) p_category, cast(p_mfgr as string) p_mfgr, cast(s_city as string) s_city, cast(s_nation as string) s_nation, cast(s_region as string) s_region, lo_revenue, lo_extendedprice * lo_discount discounted_price, lo_revenue - lo_supplycost net_revenue FROM ssb_10_flat_orc.customer, ssb_10_flat_orc.dates, ssb_10_flat_orc.lineorder, ssb_10_flat_orc.part, ssb_10_flat_orc.supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and lo_custkey = c_custkey;
Explanation of Preceding SQL Statement
The following breakdown of the preceding SQL statement explains the main elements of a statement that can transform Hive data into a time series-based Druid datasource. Values
in italicare only examples, which should be replaced by your data warehouse and analytics parameters as needed.CREATE TABLEssb_druid_hiveCreates the Hive external table and assigns a name to it. You must use a table name that is not already used by another Druid datasource.
STORED BY,'org.apache.hadoop.hive.,druid.DruidStorageHandler'This calls the Druid storage handler so that the Hive data can be transformed to a Druid datasource.
TBLPROPERTIES ("druid.segment.granularity" = "MONTH", "druid.query.granularity" = "DAY")AS SELECT cast(d_year|| '-' ||d_monthnuminyear|| '-' ||d_daynuminmonthas timestamp) as `__time`,Creates the
__timecolumn, which is a required SQL timestamp column for the Druid datasource.cast(c_cityas string) c_city, cast(c_nationas string) c_nation, cast(c_regionas string) c_region, cast(d_weeknuminyearas string) d_weeknuminyear, etc.cast (… as string)statements index columns as dimensions. Dimensions in the Druid datasource are used to search and filter.lo_extendedprice * lo_discount discounted_price, lo_revenue - lo_supplycost net_revenueThese lines preaggregate metrics columns. To index a column as metrics, you need to cast the column to a Hive numeric data type.
FROMetc.ssb_10_flat_orc.customer,ssb_10_flat_orc.dates,The numeric value indicates the data scale. The other information corresponds with the name and other components of the source Hive tables.
Table 7.3. Explanation of Table Properties for Hive to Druid ETL
| Table Property | Required? | Description | Valid Values |
|---|---|---|---|
|
druid.segment.popularity |
No |
Defines how the data is physically partitioned. The values that are permissible here correspond with Druid segment granularity. | "YEAR", "MONTH", "WEEK", "DAY", "HOUR", "MINUTE", "SECOND" |
|
druid.query.granularity | No |
Defines how much granularity to store in a segment. The values that are permissible here correspond with Druid query granularity. | "YEAR", "MONTH", "WEEK", "DAY", "HOUR", "MINUTE", "SECOND" |
Next Steps
If you need Druid to ingest Hive data that follows the same schema as the first data set that you transformed, you can do so with the INSERT INTO statement.
Performance-Related druid.hive.* Properties
The following table lists some of the Druid properties that can be used by Hive. These properties can affect performance of your Druid-Hive integration.
If Hive and Druid are installed with Ambari, the properties are set and tuned for your cluster automatically. However, you may need to fine-tune some properties if you detect performance problems with applications that are running the queries The table below is primarily for HDP administrators who need to troubleshoot and customize a Hive-Druid integration.
Table 7.4. Performance-Related Properties
| Property | Description |
|---|---|
|
hive.druid.indexer.segments.granularity |
Granularity of the segments created by the Druid storage handler. |
|
hive.druid.indexer.partition.size.max |
Maximum number of records per segment partition. |
|
hive.druid.indexer.memory.rownum.max | Maximum number of records in memory while storing data in Druid. |
|
hive.druid.broker.address.default |
Address of the Druid broker node. When Hive queries Druid, this address must be declared. |
|
hive.druid.coordinator.address.default |
Address of the Druid coordinator node. It is used to check the load status of newly created segments. |
|
hive.druid.select.threshold |
When a SELECT query is split, this is the maximum number of rows that Druid attempts to retrieve. |
|
hive.druid.http.numConnection | Number of connections used by the HTTP client. |
|
hive.druid.http.read.timeout |
Read timeout period for the HTTP client in ISO8601 format. For
example, |
|
hive.druid.sleep.time |
Sleep time between retries in ISO8601 format. |
|
hive.druid.basePersistDirectory | Local temporary directory used to persist intermediate indexing state. |
| hive.druid.storage.storageDirectory | Deep storage location of Druid. |
| hive.druid.metadata.base | Default prefix for metadata table names. |
| hive.druid.metadata.db.type | Metadata database type. The only valid values are "mysql" and "postgresql" |
| hive.druid.metadata.uri | URI to connect to the database. |
| hive.druid.working.directory | Default HDFS working directory used to store some intermediate metadata. |
| hive.druid.maxTries | Maximum number of retries to connect to Druid before throwing an exception. |
| hive.druid.bitmap.type | Encoding algorithm use to encode the bitmaps. |
| Tip |
|---|---|
If you installed both Hive and Druid with Ambari, then do not change any of the |