

Using the Hive Warehouse Connector with Spark
This section provides information about using the Hive Warehouse Connector with Apache Spark.
Significant improvements were introduced for Hive in HDP-3.0, including performance and security improvements, as well as ACID compliance. Spark cannot read from or write to ACID tables, so Hive catalogs and the Hive Warehouse Connector (HWC) have been introduced in order to accommodate these improvements.
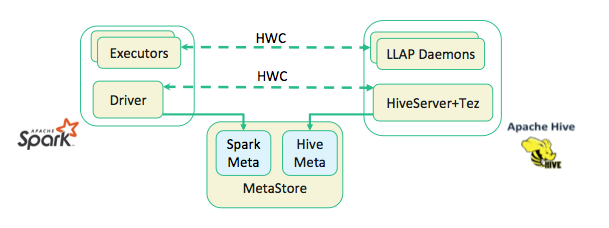
Updates for HDP-3.0:
- Hive uses the "hive" catalog, and Spark uses the "spark" catalog. No extra
configuration steps are required – these catalogs are created automatically when you
install or upgrade to HDP-3.0 (in Ambari the Spark
metastore.catalog.defaultproperty is set tosparkin "Advanced spark2-hive-site-override"). - You can use the Hive Warehouse Connector to read and write Spark DataFrames and Streaming DataFrames to and from Apache Hive using low-latency, analytical processing (LLAP). Apache Ranger and the Hive Warehouse Connector now provide fine-grained row and column access control to Spark data stored in Hive.