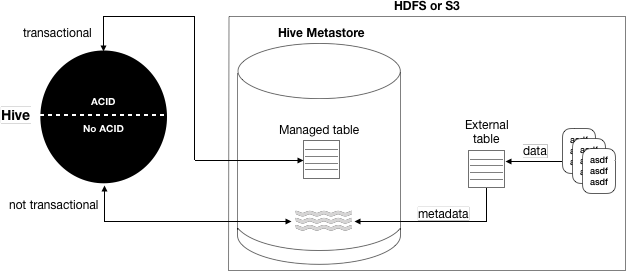
You use an external table, which is a table that Hive does not manage, to import data
from a file on a file system, into Hive. In contrast to the Hive managed table, an external
table keeps its data outside the Hive metastore. Hive metastore stores only the schema
metadata of the external table. Hive does not manage, or restrict access, to the actual
external data.
In this task, you need access to HDFS to put a comma-separated values (CSV) file on
HDFS. If you do not use Ranger and an ACL is not in place that allows you to access
HDFS, you need to log in to a node on your cluster as the hdfs user. Alternatively,
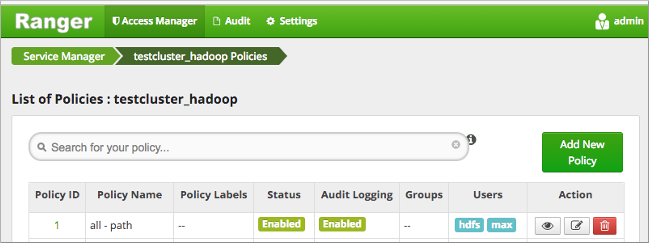
when using Ranger, you need to be authorized by a policy, such as the default HDFS
all-path policy (shown below) to access HDFS.
In this task, you create an external table from CSV (comma-separated values) data
stored on the file system, depicted in the diagram below. Next, you want Hive to
manage and store the actual data in the metastore. You create a managed table.
You insert
the external table data into the managed table.
This task demonstrates the following Hive principles:
Specifying a database location in the CREATE DATABASE command, for example CREATE
DATABASE <managed table db name> LOCATION '<path>' works
for managed tables only. To specify the location of an external table, you
need to include the specification in the table creation statement as
follows:
CREATEEXTERNALTABLE my_external_table (a string, b string)
ROWFORMAT SERDE 'com.mytables.MySerDe'WITH SERDEPROPERTIES ( "input.regex" = "*.csv")
LOCATION '/user/data';
The LOCATION clause in the CREATE TABLE specifies the location of external (not
managed) table data.
A major difference between an external and a managed (internal) table: the
persistence of table data on the files system after a DROP
TABLE statement.
External table drop: Hive drops only the metadata, consisting mainly of
the schema.
Managed table drop: Hive deletes the data and the metadata stored in the
Hive warehouse.
After dropping an external table, the data is not gone. To retrieve it, you issue another CREATE EXTERNAL TABLE statement to load the data from the file system.
Create a text file named students.csv that contains the
following lines.
As root, move the file to /home/hdfs on a node in your
cluster. As hdfs, create a directory on HDFS in the user
directory called andrena that allows access by all, and put
students.csv in the directory.
On the command-line of a node on your cluster, enter the following
commands:
Having authorization to HDFS through a Ranger policy, use the command
line or Ambari to create the directory and put the
students.csv file in the directory.
Start the Hive
shell.
For example, substitute the URI of your HiveServer: beeline -u
jdbc:hive2://myhiveserver.com:10000 -n hive -p
Create an external table schema definition that specifies the text format,
loads data from students.csv located in
/user/andrena.
Move the external table data to the managed table.
INSERT OVERWRITE TABLE Names SELECT * FROM names_text;
Verify that the data now resides in the managed table also, drop the external
table metadata, and verify that the data still resides in the managed table.