

Running Spark in Docker Containers on YARN
Apache Spark applications usually have a complex set of required software dependencies. Spark applications may require specific versions of these dependencies (such as Pyspark and R) on the Spark executor hosts, sometimes with conflicting versions. Installing these dependencies creates package isolation and organizational challenges, which have typically been managed by specialized operations teams. Virtualization solutions such as Virtualenv or Conda can be complex and inefficient due to per-application dependency downloads.
Docker support in Apache Hadoop 3 enables you to containerize dependencies along with an application in a Docker image, which makes it much easier to deploy and manage Spark applications on YARN.
To enable Docker support in YARN, refer to the following documentation:
"Configure YARN for running Docker containers" in the HDP Managing Data Operating System guide.
"Launching Applications Using Docker Containers" in the Apache Hadoop 3.1.0 YARN documentation.
Links to these documents are available at the bottom of this topic.
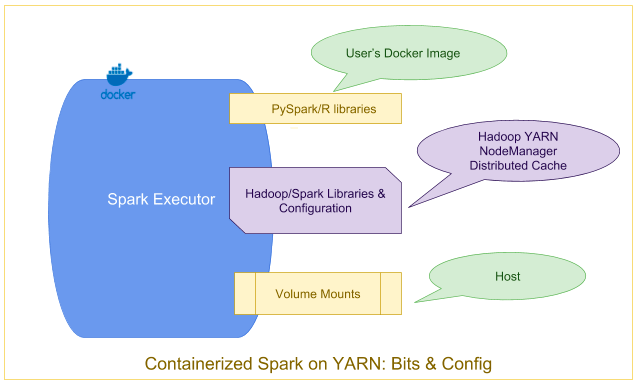
Containerized Spark: Bits and Configuration
The base Spark and Hadoop libraries and related configurations installed on the gateway hosts are distributed automatically to all of the Spark hosts in the cluster using the Hadoop distributed cache, and are mounted into the Docker containers automatically by YARN.
In addition, any binaries (–files, –jars, etc.) explicitly included by the user when the application is submitted are also made available via the distributed cache.
Spark Configuration
YARN Client Mode
In YARN client mode, the driver runs in the submission client’s JVM on the gateway machine. Spark client mode is typically used through Spark-shell.
The YARN application is submitted as part of the SparkContext initialization at the driver. In YARN Client mode the ApplicationMaster is a proxy for forwarding YARN allocation requests, container status, etc., from and to the driver.
In this mode, the Spark driver runs on the gateway hosts as a java process, and not in a YARN container. Hence, specifying any driver-specific YARN configuration to use Docker or Docker images will not take effect. Only Spark executors will run in Docker containers.

During submission, deploy mode is specified as client using
–deploy-mode=client with the following executor container
environment variables:
Settings for Executors
spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker
spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<spark executor’s docker-image>
spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=<any volume mounts needed by the spark application>YARN Cluster Mode
In the "classic" distributed application YARN cluster mode, a user submits a Spark job to be executed, which is scheduled and executed by YARN. The ApplicationMaster hosts the Spark driver, which is launched on the cluster in a Docker container.
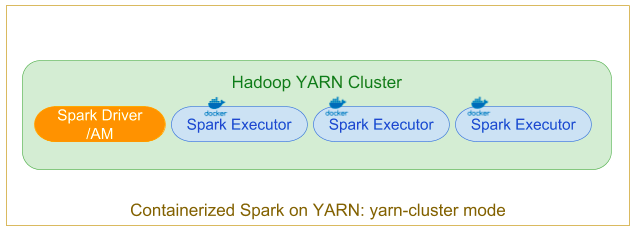
During submission, deploy mode is specified as cluster using
–deploy-mode=cluster. Along with the executor’s Docker container
configurations, the driver/app master’s Docker configurations can be set through
environment variables during submission. Note that the driver’s Docker image can be
customized with settings that are different than the executor’s image.
Additional Settings for Driver
spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_TYPE=docker
spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<docker-image>
spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:roIn the remainder of this topic, we will use YARN client mode.
Spark-R Example
In this example, Spark-R is used (in YARN client mode) with a Docker image that includes the R binary and the necessary R packages (rather than installing these on the host).
Spark-R Shell
/usr/hdp/current/spark2-client/bin/sparkR --master yarn
--conf spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker
--conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=spark-r-demo
--conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:ro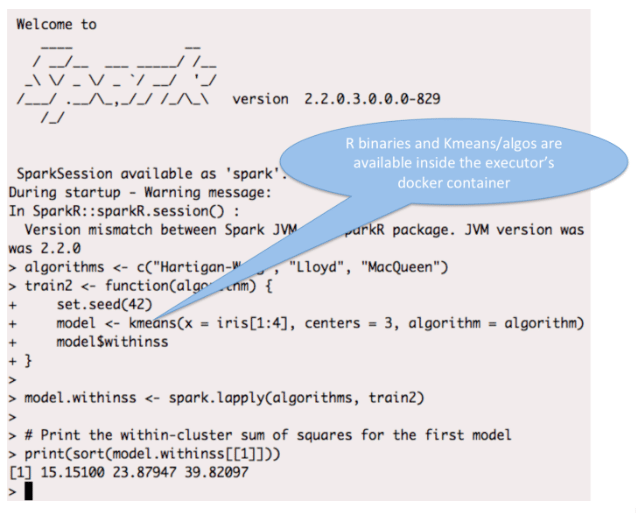
Dockerfile

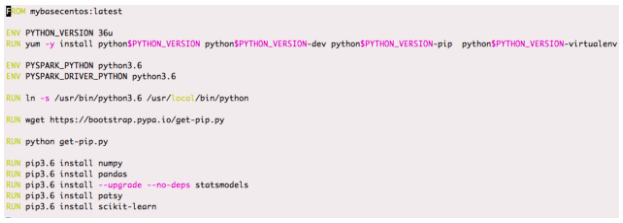
PySpark Example
This example shows how to use PySpark (in YARN client mode) with Python3 (which is part of the Docker image and is not installed on the executor host) to run OLS linear regression for each group using statsmodels with all the dependencies isolated through the Docker image.
The Python version can be customized using the PYSPARK_DRIVER_PYTHON
and PYSPARK_PYTHON environment variables on the Spark driver and
executor respectively.
PYSPARK_DRIVER_PYTHON=python3.6 PYSPARK_PYTHON=python3.6 pyspark --master yarn --conf
spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker --conf spark.executorEnv.
YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=pandas-demo --conf spark.executorEnv.
YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:ro
Dockerfile
Running Containerized Spark Jobs Using Zeppelin
To run containerized Spark using Apache Zeppelin, configure the Docker image, the runtime volume mounts, and the network as shown below in the Zeppelin Interpreter settings (under User (e.g.: admin) > Interpreter) in the Zeppelin UI.
Configuring the Livy Interpreter
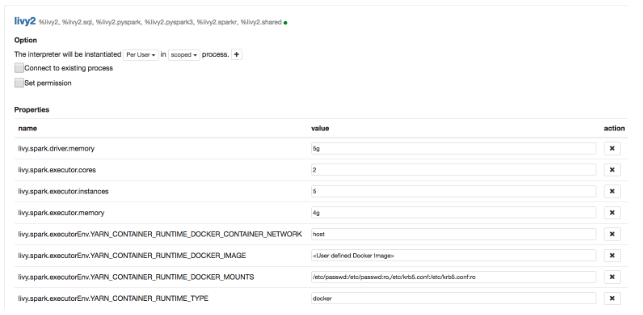
You can also configure Docker images, volume, etc. for other Zeppelin interpreters.
You must restart the interpreter(s) in order for these new settings to take effect. You can then submit Spark applications as before in Zeppelin to launch them using Docker containers.