

Apache Hive 3 architectural overview
Understanding Apache Hive 3 major design changes, such as default ACID transaction processing and support for only the thin hive client, can help you use new features to address the growing needs of enterprise data warehouse systems.
Execution engine changes
Apache Tez replaces MapReduce as the default Hive execution engine. MapReduce is no longer supported, and Tez stability is proven. With expressions of directed acyclic graphs (DAGs) and data transfer primitives, execution of Hive queries under Tez improves performance. SQL queries you submit to Hive are executed as follows:
- Hive compiles the query.
- Tez executes the query.
- YARN allocates resources for applications across the cluster and enables authorization for Hive jobs in YARN queues.
- Hive updates the data in HDFS or the Hive warehouse, depending on the table type.
- Hive returns query results over a JDBC connection.
A simplified view of this process is shown in the following figure:
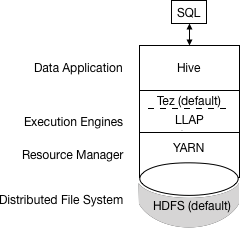
If a legacy script or application specifies MapReduce for execution, an exception occurs. Most user-defined functions (UDFs) require no change to execute on Tez instead of MapReduce.
Design changes that affect security
The following Hive 3 architectural changes provide improved security:
- Tightly controlled file system and computer memory resources, replacing flexible boundaries: Definitive boundaries increase predictability. Greater file system control improves security.
- Optimized workloads in shared files and YARN containers
By default, the HDP 3.0 Ambari installation adds Apache Ranger security services. The major authorization model in Hive is Ranger. This model permits only Hive to access HDFS. Hive enforces access controls specified in Ranger. This model offers stronger security than other security schemes and more flexibility in managing policies.
If you do not enable the Ranger security service, or other security, by default Hive uses storage-based authorization (SBA) based on user impersonation.
HDFS permission changes
- Increased flexibility when giving multiple groups and users specific permissions
- Convenient application of permissions to a directory tree rather than by individual files
Transaction processing changes
You can deploy new Hive application types by taking advantage of the following improvements in transaction processing:
- Mature versions of ACID transaction processing and LLAP:
ACID tables are the default table type in HDP 3.0.
ACID enabled by default causes no performance or operational overload.
- Simplified application development, operations with stronger transactional guarantees, and
simpler semantics for SQL commands
You do not need to bucket ACID tables in HDP 3.0, so maintenance is easier.
- Materialized view rewrites
- Automatic query cache
- Advanced optimizations
Hive client changes
Hive 3 supports only the thin client Beeline for running queries and Hive administrative commands from the command line. Beeline uses a JDBC connection to HiveServer to execute all commands. Parsing, compiling, and executing operations occur in HiveServer. Beeline supports the same command-line options as the Hive CLI with one exception: Hive Metastore configuration changes.
hive
keyword, command option, and command. For example, hive -e set. Using Beeline
instead of the thick client Hive CLI, which is no longer supported, has several advantages,
including the following:- Instead of maintaining the entire Hive code base, you now maintain only the JDBC client.
- Startup overhead is lower using Beeline because the entire Hive code base is not involved.
- Session state, internal data structures, passwords, and so on reside on the client instead of the server.
- The small number of daemons required to execute queries simplifies monitoring and debugging.
HiveServer enforces whitelist and blacklist settings that you can change using SET commands. Using the blacklist, you can restrict memory configuration to prevent HiveServer instability. You can configure multiple HiveServer instances with different whitelists and blacklists to establish different levels of stability.
The change in Hive client requires you to use the grunt command line to work with Apache Pig.
Apache Hive Metastore changes
Hive now uses a remote metastore instead of a metastore embedded in the same JVM instance as
the Hive service; consequently, Ambari no longer starts the metastore using
hive.metastore.uris=' '. The Hive metastore resides on a node in a cluster
managed by Ambari as part of the HDP stack. A standalone server outside the cluster is not
supported. You no longer set key=value commands on the command line to
configure Hive Metastore. You configure properties in hive-site.xml. The
Hive catalog resides in Hive Metastore, which is RDBMS-based as it was in earlier releases.
Using this architecture, Hive can take advantage of RDBMS resources in a cloud deployments.
Spark catalog changes
Spark and Hive now use independent catalogs for accessing SparkSQL or Hive tables on the same or different platforms. A table created by Spark resides in the Spark catalog. A table created by Hive resides in the Hive catalog. Although independent, these tables interoperate.
You can access ACID and external tables from Spark using the HiveWarehouseConnector.
Query execution of batch and interactive workloads
The following diagram shows the HDP 3.0 query execution architecture for batch and interactive workloads:
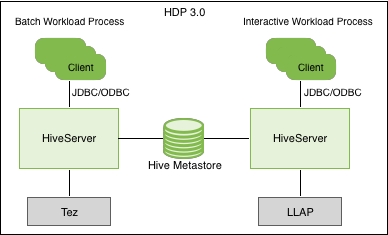
You can connect to Hive using a JDBC command-line tool, such as Beeline, or using an JDBC/ODBC driver with a BI tool, such as Tableau. Download the JDBC driver hive-jdbc from the https://www.cloudera.com/downloads/hdp.html. Clients communicate with an instance of the same HiveServer version. You configure the settings file for each instance to perform either batch or interactive processing.