

Key components of Hive warehouse processing
A brief introduction to these software and systems, which affect performance, helps you understand the scope of the tuning task: HiveServer, admission control, batch processing using Apache Tez, interactive processing using Apache Tez and LLAP daemons, and YARN.
HiveServer
HiveServer provides Hive service to multiple clients that simultaneously execute queries against Hive using an open Apache Hive API driver, such as JDBC. For optimal performance, you should use HiveServer to connect your client application and the Hive enterprise data warehouse (EDW). Using Ambari, you can install, configure, and monitor the Hive service and HiveServer.
An embedded metastore, which is different from MetastoreDB, runs in HiveServer and performs the following tasks:
- Gets statistics and schema from MetastoreDB
- Compiles queries
- Generates query execution plans
- Submits query execution plans
- Returns query results to the client
Admission control
HiveServer coordinates admission control. Admission control is critical to Hive performance tuning. Admission control manages queries in a manner similar to how connection pooling manages network connections in RDBMS databases. When using the Hive LLAP on the Tez engine, you can configure admission control.
- Enables optimal Hive performance when multiple user sessions generate asynchronous threads simultaneously
- Scales concurrent queries to suit system resources and demand
- Postpones processing or cancels other queries if necessary
Batch processing using Apache Tez
Each queue must have the capacity to support one complete Tez application, as defined by its Application Master (AM) (tez.am.resource.memory.mb property). Consequently, the number of Apache Tez AMs limits the maximum number of queries a cluster can run concurrently. A Hive-based analytic application relies on YARN containers as execution resources. The Hive configuration defines containers. The number and longevity of containers that reside in your environment depend on whether you want to run with batch workloads or enable Hive LLAP in HDP.
Hive on Tez is an advancement over earlier application frameworks for Hadoop data processing, such as using Hive on MapReduce, which is not supported in HDP 3.0 and later. The Tez framework is suitable for high-performance batch workloads.
After query compilation, HiveServer generates a Tez graph that is submitted to YARN. A Tez AM monitors the query as it runs.
Interactive processing using Apache Tez and LLAP daemons
The way interactive and batch workloads operate with YARN and queues differs. Hive LLAP manages resources globally, rather than managing resources of each Tez session independently. LLAP does not rely on YARN: LLAP has its own resource scheduling and pre-emption built in. Consequently, you need only a single queue to manage all LLAP resources. Each LLAP daemon runs as a single YARN container.
The following diagram shows the architecture of Hive LLAP:
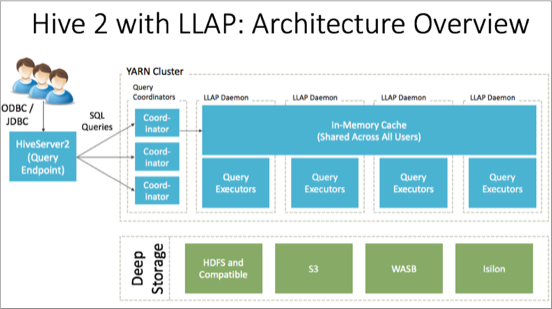
- Query coordinators
- Components that coordinate the execution of a single, persistent LLAP daemon, typically one per node. This is the main differentiating component of the architecture, which enables faster query runtimes than earlier execution engines.
- Query executors
- Threads running inside the LLAP daemon.
- In-memory cache
- A cache inside the LLAP daemon that is shared across all users.
YARN
LLAP depends on YARN queues. HiveServer and YARN work together to intelligently queue incoming queries of a Hive data set. The queuing process tends to minimize the latency of returned results. The LLAP daemons manage resources across YARN nodes. When you set up LLAP, you enable interactive queries, enable YARN pre-emption, and choose a YARN queue for LLAP processing.