Recommendations for scaling Cloudera Data Engineering deployments
Your business might experience a sudden increase or drop in demand due to which your Cloudera Data Engineering deployment needs to autoscale. You can scale your Cloudera Data Engineering deployment by either adding new instances of a Cloudera Data Engineering service or Virtual Cluster, or by adding additional resources to the existing ones.
You can scale your Cloudera Data Engineering deployment horizontally - new instances of Cloudera Data Engineering service or virtual cluster are provisioned.
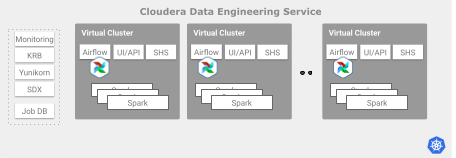
Virtual Clusters provide an isolated autoscaling compute capacity to run Spark and Airflow jobs. You can use Virtual Clusters to isolate individual teams or lines of business by using user-based Access Control Lists (ACLs).
Guidelines for scaling Virtual Clusters
-
Each Virtual Cluster requires infrastructure capacity to run various services such as Airflow, API server, and Spark-History-Server (SHS).
Recommendation: Do not scale horizontally beyond
50Virtual Clusters within the same Cloudera Data Engineering service. -
Virtual Clusters can actively run hundreds of parallel jobs. In certain scenarios, it might be required to simultaneously submit multiple jobs as per the schedule or due to a burst in demand. In these scenarios, the API server enforces guardrails and limits the number of simultaneous Spark job submissions to
60. Once the jobs move from submission to running state, you can submit more jobs.Recommendation: Distribute simultaneous submission of jobs over time or horizontally scale across multiple Virtual Clusters.
Limit on resource files in job runs
Job submission rate guardrails
When jobs are submitted to the Cloudera Data Engineering API server of a particular Virtual
Cluster, it takes time and resources, known as preparing and
starting states, before they begin running. This process is called the job
submission intake process. To ensure proper resourcing and handling of incoming jobs, guardrails
have been set up. By default, the guardrail, or limit is set to 60 simultaneous
job submissions. Simultaneous incoming Spark job submissions that exceed 60
return a 429 error message to the client. The example error message is: Failed to
submit. Too many requests.
Recommendation:
- Incorporate Cloudera Data Engineering Clients error handling for this error. The CDE CLI exit code is 77. The CDE CLI receives an HTTP 429 response code for the request to the Runtime API Server's REST API. For more information on exit codes, see Cloudera Data Engineering CLI exit codes.
- If necessary, you can decrease the default job submission limit value of
60simultaneous jobs during the Virtual Cluster creation by adjusting thelimiting.simultaneousJobSubmissionsconfiguration. - Cloudera discourages you from increasing the
job submission limit value beyond the default
60simultaneous jobs.
Fine-tuning gang scheduling behavior for Apache Spark jobs
By default, Cloudera Data Engineering configures gang scheduling for Spark jobs. However, if the Cloudera Data Engineering service lacks sufficient resources to run the Spark driver and minimum executors for a job, the job remains in the pending state and fails. To prevent the job from failing if resources are insufficient, fine tune the gang scheduling behavior for Spark jobs.
- Perform the steps in Managing Virtual Cluster-level Spark configurations
[Technical Preview] and in the Spark Configurations
textbox add the following
configuration:
spark.kubernetes.driver.annotation.yunikorn.apache.org/schedulingPolicyParameters=placeholderTimeoutInSeconds=60 gangSchedulingStyle=Hard - Click Apply Changes to add the Yunikorn annotation to all Spark drivers.