Creating virtual clusters
In Cloudera Data Engineering, a virtual cluster is an individual auto-scaling cluster with defined CPU and memory ranges. Jobs are associated with virtual clusters, and virtual clusters are associated with an environment. You can create as many virtual clusters as you need. See Recommendations for scaling Cloudera Data Engineering ceployments linked below.
To create a virtual cluster, you must have an environment with Cloudera Data Engineering enabled.
-
In the Virtual Clusters column, click
 at the top right to create a
new virtual cluster.
If the environment has no virtual clusters associated with it, the page displays a Create DE Cluster button that launches the same wizard.
at the top right to create a
new virtual cluster.
If the environment has no virtual clusters associated with it, the page displays a Create DE Cluster button that launches the same wizard.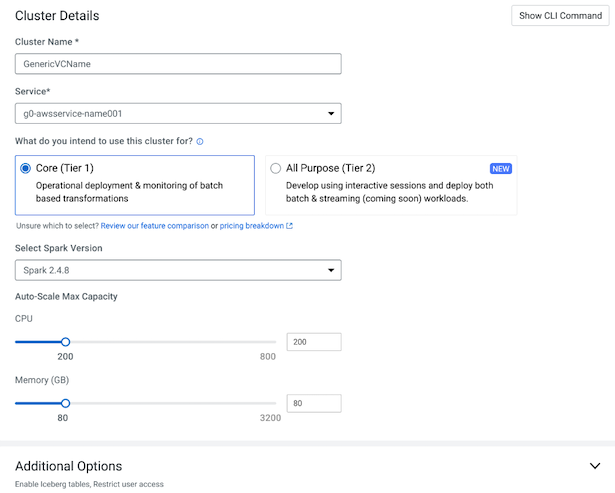
-
Select the Spark Version to use in the virtual cluster. You
cannot use Spark 2 and Spark 3 in the same virtual cluster, but you can have separate
Spark 2 and Spark 3 virtual clusters within the same Cloudera Data Engineering
service. While you can have virtual clusters with different Spark 3.x versions, a single
virtual cluster can only use one Spark version.
On the Cloudera Data Engineering UI, you can view the supported Apache Airflow runtime component version and Spark runtime component version on the VC creation and details pages.
The following screenshot illustrates creating a new Virtual Cluster, where you can select the required runtime component versions from a drop-down menu on the UI.
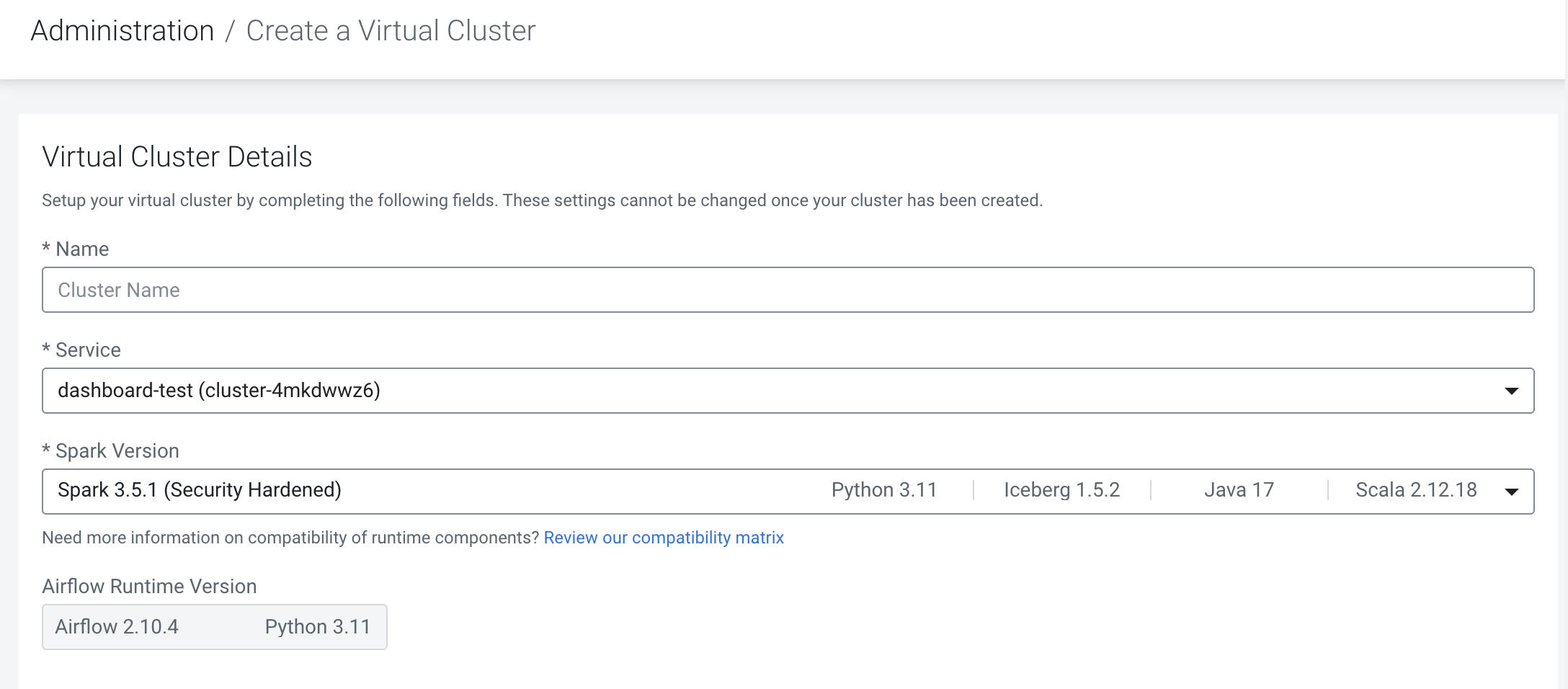
For more information, see Compatibility for Cloudera Data Engineering and Runtime components.