General known issues with Cloudera Data Engineering
Learn about the general known issues with the Cloudera Data Engineering service on cloud, the impact or changes to the functionality, and the workaround.
- DEX-22149: Diagnostics bundle
cloud-diagnostics.jsonmissing requiredlb_infoincloud_resource_status - On AWS public cloud, the diagnostics bundles are created and downloaded successfully,
but the
cloud-diagnostics.jsonin the bundle omits thelb_infofield undercloud_resource_status.
- DEX-22137: Cloudera Data Engineering Event logs contain
the warning "
The addition of the file system policy to prevent anonymous access has failed." during VC creation - During Virtual Cluster creation, occasionally, Cloudera Data Engineering Event
logs contain the "
The addition of the file system policy to prevent anonymous access has failed." warning. This warning does not stop the Cloudera Data Engineering Service creation or Virtual Cluster creation. It also allows you to create and run jobs. Only the Elastic File System (EFS) will not have a file system policy, which is needed to avoid anonymous access to EFS.
- DEX-22122: The "
K8sUtil not set; cannot wait for instance deployments before job management." error is included in the event log during Service suspend and resume and Cloudera Data Engineering in-place upgrade [quit maintenance] - This is a warning, which does not stop the suspend and resume or the Cloudera Data Engineering in-place upgrade operations.
After the upgrade, during the quit maintenance of the resume operation, the job-management step tries to wait for instance deployments to become ready before unpausing the scheduled jobs, but
K8sUtilis not included in the quit maintenance workflow context.Because of this missing dependency, the control plane logs "
K8sUtil not set; cannot wait for instance deployments before job management.", skips the deployment readiness check, and continues with unpausing the job.
- DEX-21992: Diagnostics Advanced Settings dialog is stuck when invalid input is entered
- On the Cluster Details page, navigate to the tab. On the Advanced Settings tab of the
Generate Diagnostics Bundle dialog, if you enter an invalid value
range (for example, if the
Maximumvalue is lower than theMinimumvalue), after clicking Generate, the Cloudera Data Engineering UI is stuck.
- DEX-21938: The Backup and Restore Content Restore operation failed
to restore an Airflow job due to import failure (
ModuleNotFoundError: No module named 'airflow.providers.amazon') - The following default Airflow packages have been removed from the Cloudera Data Engineering 1.26.1 release due to identified CVE risks:
apache-airflow-providers-google(Related CVE: CVE-2026-27459)apache-airflow-providers-snowflake(Related CVE: CVE-2025-50213)apache-airflow-providers-amazon(Related CVE: CVE-2024-12745)
If your Airflow jobs rely on any of these packages, before backing up and upgrading, you must remove the references to the discontinued Airflow packages.
- DEX-21227: Default Spark job executors are different in 1.25.0 and 1.25.2-H1
- Since Cloudera Data Engineering 1.25.2, the Spark Job default executor range was changed by mistake to 1-1. Due to this, the default executor range is not recorded in the configuration, any Jobs that are backed up from before Cloudera Data Engineering 1.25.2 and restored to 1.25.2 have 1-1 as the executor range too. This issue was fixed in Cloudera Data Engineering 1.26.1, the executor upper bound is back to the maximum quota available, and the default number is backed up in the configuration.
- DEX-14442: Session reflecting incorrect state of command
- When running a statement in Cloudera Data Engineering Sessions, the Session
status shown may be incorrect for about a minute due to Session state synchronization lag
across Cloudera Data Engineering and Livy.
This issue was partially resolved in 1.26.1; the Livy and Cloudera Data Engineering Runtime realtime-synchronization is functional, but the Cloudera Data Engineering UI may still temporarily display a stale Session state.
- DEX-21166: CDE CLI for Windows panics at startup on non-FIPS hosts
- The Cloudera Data Engineering (CDE) CLI binary (cde.exe) version 1.25.2 panics at startup on Windows hosts that do not have FIPS mode enabled at OS level.
- DEX-20825: Updating Virtual Cluster SMTP email alerts configuration does not work
- When updating the Virtual Cluster SMTP email alerts configuration through the User Interface, the Apply Changes button fails to trigger an API call. Consequently, SMTP settings are not saved, and the configuration remains unchanged regardless of the user input.
- OBS-10957: Enable or disable PeerAuthentication in the monitoring namespace based on the Liftie override
- A platform change in DSP 1.30.1 introduced Istio sidecar injection into the Kubernetes
monitoring namespace. This conflicts with the strict mTLS policy of Cloudera Data Engineering and breaks the Prometheus metrics collection on Cloudera Data Engineering Services created on DSP 1.30.1 or higher versions. In
these versions, monitoring pods receive Envoy sidecars that enforce strict mTLS, causing
HTTP 503 errors on all Prometheus communication paths.
Symptoms:
- CPU and memory counts are missing from the Cloudera Data Engineering Service Details page.
- Empty charts are displayed on the Cloudera Data Engineering Monitoring page.
- Service-level and Virtual Cluster-level Grafana dashboards display no data.
- Virtual Cluster resource usage cards on the Administration page are blank.
- The
/metricsendpoint returns errors.
- Use the following procedure to change mTLS mode from
STRICTtoPERMISSIVEin the monitoring namespace. This allows Istio to use metrics merging, which bypasses TLS.- Obtain the Kubeconfig file from the Cloudera Data Engineering Service and
save it. For example,
~/.kube/config - Create a dedicated directory and navigate to it by running the following
command:
mkdir ~/istio-config && cd ~/istio-config - Create the
peerauthentication.yamlfile by running the following command:cat <<EOF > peerauthentication.yaml apiVersion: security.istio.io/v1 kind: PeerAuthentication metadata: annotations: meta.helm.sh/release-name: monitoring meta.helm.sh/release-namespace: monitoring labels: app.kubernetes.io/managed-by: Helm name: monitoring-peer-authentication namespace: monitoring spec: mtls: mode: PERMISSIVE EOF - Apply the configuration by running the following command from the
~/istio-configdirectory.Results:
For newly created resources, the following message is displayed:
peerauthentication.security.istio.io/monitoring-peer-authentication createdFor already existing resources, the following message is displayed:
peerauthentication.security.istio.io/monitoring-peer-authentication configured - Confirm that the resource is active and set to
PERMISSIVEmode by running the following command:kubectl get peerauthentication -n monitoring --kubeconfig [***PATH_TO_KUBECONFIG***]For example:

- Obtain the Kubeconfig file from the Cloudera Data Engineering Service and
save it. For example,
- DEX-20303: Airflow job runs fail with "context canceled" error
- Airflow jobs are cancelled by a client-side timeout if a Cloudera Data Engineering Airflow management task does not complete in time. The
timeout is the result of a computational cost overhead during job setup. When this failure
occurs, the logs contain the following error line:
Error: context canceled.
- ENGESC-32900: 401 AuthN error for Virtual Cluster suspend
- Cloudera Data Engineering Virtual Cluster suspend operations are failing with
the
401 AuthNauthentication error. This issue arises when a Virtual Cluster suspend operation is attempted after a Virtual Cluster resume operation that was initiated by an IDP user who has already been deleted. The issue arises because of the absence of a context restore during the Virtual Cluster suspend process.
- DEX-20264: New Virtual Cluster creation failure in the dex-app pod during database initialization
- If the dex-app server pod is evicted during database initialization, the system recreates the pod and attempts to run the initialization script again. Because the database schema can only be initialized once, this causes the Virtual Cluster creation to fail.
- DEX-20008: Cadence installation fails when the PostgreSQL database is used with Graviton workloads
- The AWS with Graviton and PostgreSQL combination fails, due to a cadence installation issue. The root cause is identified to be an architecture mismatch of the Postgres image and node.
- DEX-19992: Global 3-hour timeout exhausted during database phase due to Kubernetes multi-version hop (1.31 -> 1.32 -> 1.33) and transient component retries
- During the in-place upgrades, where there are multiple version upgrades involved for Kubernetes, the timeout is not sufficient and as a result the upgrade fails.
- DEX-19728: Upgrade fails with "pod not found" for dex-base-management-api during dex-app component upgrade
- During a Cloudera Data Engineering in-place upgrade, the orchestrator
port-forwards to dex-base-management-api to upgrade virtual clusters. If a previous
rolling-update pod is stuck in a failed state with
OutOfcpuerror, the pod selection functionGetPodNameByLabelselects the failed pod over the healthy running pod, because it returns the first alphabetical match with no phase filter. Every retry results in the same failed pod, causing the upgrade to fail with theMaintenance_ClusterUpgradeFailederror. The failed pod exists because Yunikorn races ahead of the Cluster Autoscaler, it assigns the pod to a near-full node before the new node of the Cluster Autoscaler is Kubernetes-Ready. Then, the pod fails with theOutOfcpuerror, and Kubernetes does not reschedule it as pending, leaving the failed object in the API until the failed nodes are collected and cleaned up, possibly hours later.
- DEX-19706: Scala or PySpark Spark-SQL queries trigger out of memory for the driver, causing session termination
- A Cloudera Data Engineering 1.25.2 Spark session can take slightly more memory on a Graviton instance as a result of moving from the Cloudera Data Hub-731.400 to the Cloudera Data Hub-731.600 release line.
- DEX-19334: Error terminating "efs-init-job" pod during VC deletion
- The
efs-init-jobpod may fail to terminate properly during Virtual Cluster (VC) deletion, resulting in the pod remaining in aTerminatingstate. The root cause is that theddprocess enters an irrecoverable hung state (Dstate) .
- DEX-15929: Airflow pyenv certificates in PEM format are not converted to Base64 in the Cloudera Data Engineering UI
- The Cloudera Data Engineering API for Airflow Operators and Libraries currently expects Base64-encoded certificates, but the Cloudera Data Engineering UI sends PEM certificates without conversion.
- DEX-18310: Azure Cloudera Data Engineering service
stability or scaling issues in 1.25.0 (
cde-fluentd OOMKilled) - Memory leak issue in
cde-fluentdin Azure.
- ENGESC-31314: Cloudera Data Engineering Spark UI is not available for finished jobs
- By default, the priority class for the
cde-fluentddaemonset is not set, so it uses the default priority class. As a result, if thecde-fluentddaemonset restarts for any reason, it can never preempt other pods and it cannot start running on every node. This issue is present on all cloud platforms.
- DEX-18727: Spark SQL functions do not work in Spark Connect sessions
- Spark Connect functions require the
SPARK_CONNECT_MODE_ENABLEDenvironment variable to be set totrue. Otherwise, Spark tries to use the normal Spark context functions, which do not work in Spark Connect.
- DEX-18832: Update CDP CLI with the latest DEX changes
- With Data Lake 7.3.1 and higher, while using the CDP CLI to create a virtual cluster,
the following error is
displayed:
An error occurred: can't find runtime catalog ID with CDE 1.25.0, Datalake 7.3.2, Spark 3.5.1 and given osnames (Status Code: 500; Error Code: UNKNOWN; Service: de; Operation: createVc; Request ID: 1a8b575d-cfa9-4fb7-a65b-6be6ebf97a0c;)
- DEX-18481: Retry of Cloudera Data Engineering service restore via script is failing with cluster with same ID already exists error
- If a service is deleted and later restored with the same ID, and during this process the environment is down or deleted, you will see a “cluster with same ID already exists” error. This error occurs even if the service is not displayed on the Cloudera Data Engineering UI.
- DEX-18456: Airflow jobs fail during node upgrade
- If you have Azure Node Image Auto Upgrade enabled, during the upgrade, Cloudera Data Engineering Airflow jobs can fail, due to node failures. The root cause is that the node image is upgraded automatically and causes all running Airflow schedule pods to terminate and Airflow jobs to fail.
- DEX-18440: Cloudera Data Engineering Jobs are not reflecting in the spark-history Server
- In Cloudera Data Engineering services running in AWS with Spark version higher
than or equal to 3.5.1 with virtual clusters having the following versions: Cloudera Data Engineering 1.22.0, 1.23.0, 1.24.1 and 1.25.0, and running behind
the Non Transparent Proxies (NTP), the Spark history server is not able to discover the
correct AWS S3 bucket region, due to a change in Hadoop AWS builds. The affected runtimes
are Cloudera Data Engineering running with 7.2.18 and 7.3.1 runtimes. In such a
case, the following error is displayed in SHS pod logs and the Spark UI does not display
for the finished
jobs.
Exception in thread "main" org.apache.hadoop.fs.s3a.AWSApiCallTimeoutException: getFileStatus on s3a://qe-s3-bucket-longrunning/cluster-logs/dex/cluster-zff7f26d/6fwjjzgs/eventlog: software.amazon.awssdk.core.exception.ApiCallTimeoutException: Client execution did not complete before the specified timeout configuration: 60000 millis at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:222) at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:154) at org.apache.hadoop.fs.s3a.S3AFileSystem.s3GetFileStatus(S3AFileSystem.java:402 - The workaround is to set the correct bucket region in the
Spark history configuration using the
spark.hadoop.fs.s3a.endpoint.regionparameter.Prerequisite:
kubectlaccess to the Cloudera Data Engineering cluster.Steps:
- Determine the log bucket from the “summary” page of Data Lake. For example,
us-west-2. - Determine the Virtual Cluster (VC) namespace of the affected VC, which is the same
as its VC-ID. For example:
dex-app-gk9kpt24. Export it in its current shell session.export DEX_APP_NS=dex-app-gk9kpt24 - Use the following command to edit the Spark default
configmap.
kubectl edit cm -n $DEX_APP_NS $DEX_APP_NS-spark-defaults - Add the
spark.hadoop.fs.s3a.endpoint.region: us-west-2property as shown below in the screenshot and save the file.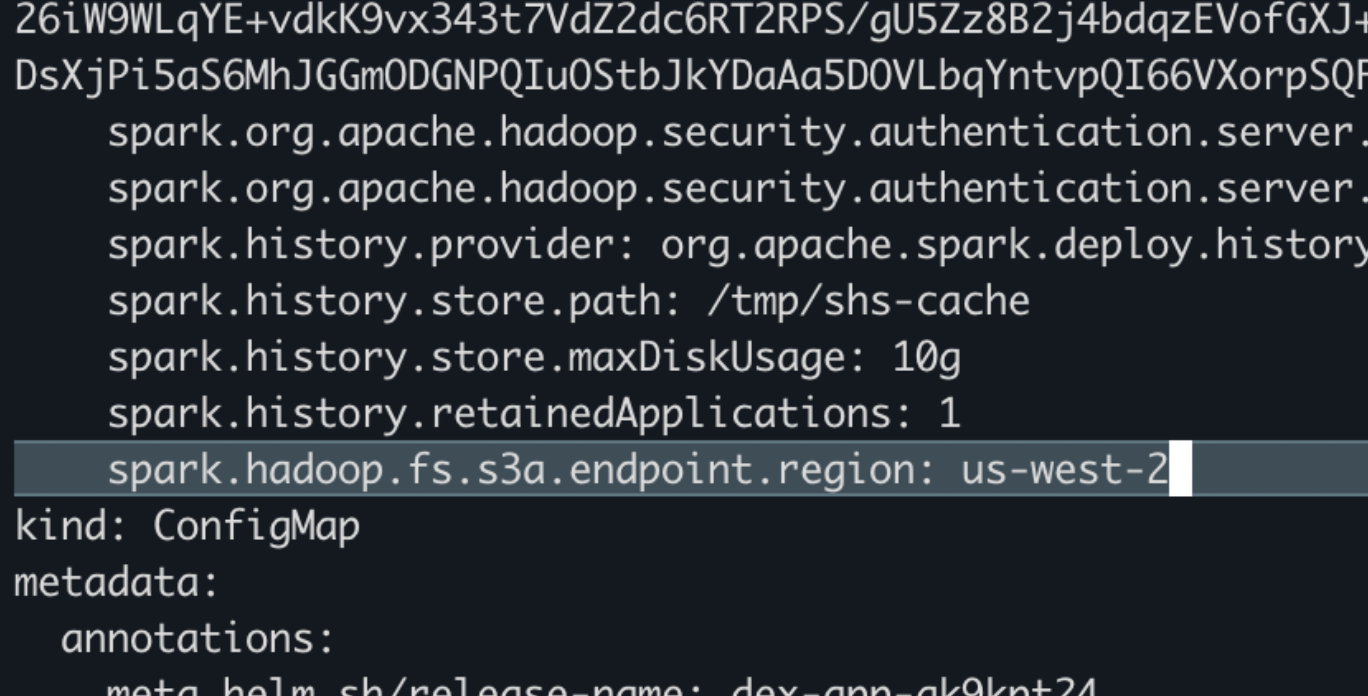
- Use the following command to verify the changes committed in the
configmap.
kubectl get cm -n $DEX_APP_NS $DEX_APP_NS-spark-defaults -o yaml - Restart the Spark History Server (SHS) pod for the changes to take effect.
- Get the pod
name:
kubectl get pods -n $DEX_APP_NS - Delete the
pod:
kubectl delete pod -n $DEX_APP_NS dex-app-gk9kpt24-shs-7b7cfd94dd-8mdqh
- Get the pod
name:
After this procedure, the Spark UI displays all previous and new job runs.
- Determine the log bucket from the “summary” page of Data Lake. For example,
- DEX-18305: Cannot create VC with latest 1.25.0 Control Plane on Cloudera Data Engineering Service 1.24.1-h1-b14 without specifying sparkVersion in the request
- In Cloudera Data Engineering versions lower than 1.25.0, the
createInstanceAPI and the corresponding CDP CLI to create virtual clusters work when you do not specify a Spark version. In such a case, by default, a Spark version is selected.In Cloudera Data Engineering 1.25.0, the
createInstanceAPI operates as follows:- If you specify the Spark version, the
createInstanceAPI and the CDP CLI work. - If you do not specify the Spark version, the
createInstanceAPI and the CDP CLI give an error.
- If you specify the Spark version, the
- DEX-18203: Suspending multiple VCs simultaneously is leading to race condition
- Suspending multiple Virtual Clusters (VCs) simultaneously can cause inconsistent state to the service.
- DEX-17369: Cloudera Data Engineering Service's Resource Edit is Failing with status 500: [error validating instance group update request]
- You cannot edit the Auto-scaling Range for Spot and On-demand instances in both Core and All-Purpose tiers, after the Cloudera Data Engineering service is created. The Cloudera Data Engineering service edit operation fails if you try to edit these parameters after the service creation.
- DEX-16495: Write Spark DF/Stream to Hive using Hive Streaming fails with "org.apache.hive.streaming.InvalidTable"
- In Spark 3.3.0, there is an issue with writing Spark Dataframe to Hive using Hive Streaming, that is DATAFRAME_TO_STREAM. The failure is related to compatibility issues between Spark 3.3.0 runtime components and Hive client libraries.
- DEX-16492: Write Spark DF/Stream to Hive using Hive Streaming fails with "org.apache.hadoop.fs.s3a.impl.InstantiationIOException"
- This issue affects both AWS and Azure. During the release of Spark 3.5.1, supported by
the 7.2.18 runtime, the RAZ library has gone through backward incompatible changes and it
requires in core-site.xml to remove two parameters and to add two new parameters. This has
been achieved by unsetting and setting the required parameters through the runtime API
server.
It has been observed that a few integration parameters, like Hive Warehouse Connector (HWC) parameters, do not accept these passed-in parameters and read only parameters defined in core-site.xml. As a result, a manual workaround is needed for the affected customers to fix the core-site.xml by removing the required parameters and adding the new parameters for the affected Virtual Clusters (VCs).
- DEX-16426: Error fetching data from Hive Managed Table in JDBC_CLUSTER mode
- If you use Spark Hive Warehouse Connector and Spark version 3.5.1, there is an issue
related to fetching data from Hive managed tables in JDBC_CLUSTER read mode, which results
in a syntax error.
Error message:
[PARSE_SYNTAX_ERROR] Syntax error at or near ‘.’ (line 1, pos 21)
- DEX-17969: Airflow failed to connect to Impala in Cloudera Data Engineering
- Due to a Python thrift-related error, which is a dependency of Impyla, Airflow fails to
connect to Impala in Cloudera Data Engineering. This issue results in a system
error related to the
PY_SSIZE_T_CLEANmacro when using fast binary encoding.
- DEX-17581: Cloudera Data Engineering-1.24.1 is not getting deployed in East US region
- Only applicable to Azure. Cloudera Data Engineering
service creation failed during the database server provisioning step. The issue occurred
because the Azure API, which Cloudera Data Engineering uses to retrieve the
supported database instance types for the specified region (for example,
eastus), returned an empty response. As a result, the database server provisioning could not proceed. The following error message appeared in the Cloudera Data Engineering service logs:unable to get MySQL flexible server DB instance type for cluster, Error: no instance types available for MySQL flexible server DB service tier: GeneralPurpose having vCores 2
- DEX-17565: Links to download
cdeconnectandpyspark tarsfor Spark Connect are giving HTTP 404 error - Links to download
cdeconnectandpyspark tarsfor Spark Connect give an HTTP 404 error.
- DEX-17519: Sessions are not killed as per the ttl configured in Azure and AWS
- Sessions are not killed as per the ttl configured in Azure and in
AWS. The calculation of timeout has gone wrong in the
isTimeoutmethod in the Livy code. This method takes a calculated timeout in milliseconds and converts it into nano seconds. However, the caller is already passing the calculated timeout value in nano seconds. In theisTimeoutmethod, thecalculatedTimeoutvalue is converted again, which provides a different value. Therefore, (toTime - fromTime) will not be greater than the calculated timeout, as the calculated timeout value is higher. For this reason, the sessions are not killed after the timeout is reached.
- DEX-17507: Restore of Scheduled Jobs are failing due to time format
- Restoring the Spark Jobs with the Schedule Configuration fails if the start date or end date uses a time format other than RFC3339Nano. This issue affects only jobs created using non-UI options, such as the API or CLI.
- DEX-17500: [CDP Cli] Spark OsName "chainguard" Not Triggering Error in Cloudera Data Engineering Version 1.23.1 Virtual Cluster
- Cloudera Data Engineering allows the creation of a
Virtual Cluster with the
securityhardenedoption in Cloudera Data Engineering version 1.23.1, without any error message. Technically, it is usingUBI [redhat]underneath, which is correct, but it can lead to confusion, as the property in the Virtual Cluster statessecurityhardened.
- DEX-17458: Cloudera Data Engineering session creation is
failing with
java.util.concurrent.ExecutionException: javax.security.sasl.SaslException - Cloudera Data Engineering sessions created in a Spark
3.3.0 Virtual Cluster fail to create. The following error is listed in the driver logs:
Exception in thread "main" java.util.concurrent.ExecutionException: javax.security.sasl.SaslException: Client closed before SASL negotiation finished
- DEX-16747: Cloudera Data Engineering 1.23.1-b114 - Driver container stderr, and stdout logs are missing for some Spark jobs
- For some job runs, intermittently, the driver
stderrandstdoutlogs are missing.
- DEX-16414: Sessions GET endpoint not returning empty array
- When no sessions are present in a Virtual Cluster, the Sessions page on the Cloudera Data Engineering UI displays 'Loading' state, instead of empty state.
- DEX-15884: Resource file upload did not pick the modified file intermittently
- When you attempt to update a file by uploading a new version with
the exact same filename, the operation appears to succeed, but the content of the file is
not updated. The system continues to serve the previous version of the file. This issue
has been observed to occur intermittently under the following conditions:
- Uploading a file to overwrite an existing file with the same name.
- Deleting the original file first and then uploading a new file with the same name.
- DEX-15714: Proxy settings are not propagating to Cloudera Data Engineering sessions
- Proxy settings from a configured
CDP proxy(configmap:cdp-proxy-config) are not propagated to Cloudera Data Engineering sessions. Proxy settings for Cloudera Data Engineering jobs are propagated throughspark.driver.extraJavaOptionsandspark.executor.extraJavaOptions, as standardJAVA_OPTS. For more information, see Cloudera public proxy documentation.
- DEX-15461: Writing Spark Dataframe to Hive using HWC Fails with
java.util.NoSuchElementException: None.get - This is a known issue while writing data in ORC format. The issue has been fixed internally, but more testing is needed. This issue will be part of the Hive Warehouse Connector and Cloudera Data Engineering certification in the future.
- DEX-14725: virtualenv cannot access pypi mirror
- When a Python virtual environment is created, virtual-env needs to
access the internet to seed packages such as pip, setup-tools, and wheel. If you block the
public internet access (for example, in case of a private network), certain packages fail
to build. Example package:
requests-kerberos
- DEX-14385: Backup fails if there is a Git repository resource
- In the Cloudera Data Engineering 1.20.3 services, if there is a Git repository resource, the cluster backup fails.
- DEX-12616: Node Count shows zero in /metric request
-
Cloudera Data Engineering 1.20.3 introduced compatibility with Kubernetes version 1.27. With this update, the
kube_state_metricsno longer provides label and annotation metrics by default.Earlier, Cloudera Data Engineering used label information to calculate the Node Count for both Core and All-Purpose nodes, which was automatically exposed. However, due to the changes in
kube_state_metrics, this functionality is no longer available by default. As a result, the Node count shows zero in /metrics, charts, and the user interface.
- DEX-11340: Kill all the alive sessions in prepare-for-upgrade phase of stop-gap solution for upgrade
- If Spark sessions are running during the Cloudera Data Engineering upgrade, they are not automatically killed, leaving them in an unknown state during and after the upgrade.
- DEX-14084: No error response for Airflow Python virtual environment at Virtual Cluster level for view only access user
- If a user with a view only role on a Virtual Cluster (VC) tries to create an Airflow Python virtual environment on a VC, the access is blocked with a 403 error. However, the no-access 403 error is not displayed on the UI.
- DEX-11639: "CPU" and "Memory" Should Match Tier 1 and Tier 2 Virtual Clusters AutoScale
- CPU and Memory options in the service or cluster edit page display the values for Core (tier 1) and All-Purpose (tier 2) together. However, they must be separate values for Core and All-Purpose.
- DEX-12482: [Intermittent] Diagnostic Bundle generation taking several hours to generate
- Diagnostics bundles can intermittently take very long to get generated due to low EBS throughput and IOPS of the base node.
- DEX-14253: Cloudera Data Engineering Spark Jobs are getting stuck due to the unavailability of the spot instances
- The unavailability of AWS spot instances may cause Cloudera Data Engineering Spark jobs to get stuck.
- DEX-14192: Some Spark 3.5.1 jobs have slightly higher memory requirements
- Some jobs running on Spark 3.5.1 have slightly higher memory requirements, resulting in the driver pods getting killed with a k8s
OOMKilled.
- DEX-14173: VC Creation is failing with "Helm error: 'timed out waiting for the condition', no events found for chart"
- In case of busy k8s clusters, installing VC/Cloudera Data Engineering may fail
with an error message showing
Helm error: 'timed out waiting for the condition', no events found for chart.
- DEX-13957: Cloudera Data Engineering metrics and graphs show no data
- Cloudera Data Engineering versions 1.20.3 and 1.21 use Kubernetes version 1.27. In Kubernetes version 1.27, by default, the kube_state_metrics does not provide label and annotation metrics. For this reason, the node count shows zero for core and all-purpose nodes in the Cloudera Data Engineering UI and in charts.
- DEX 11498: Spark job failing with error: "Exception in thread "main" org.apache.hadoop.fs.s3a.AWSBadRequestException:"
- When users in Milan and Jakarta region use Hadoop s3a client to access AWS s3 storage, that is using s3a://bucket-name/key to access the file, an error may occur. This is a known issue in Hadoop.
- DEX-10147: Grafana issue for virtual clusters with the same name
- In Cloudera Data Engineering 1.19, when you have two different Cloudera Data Engineering services with the same name under the same environment, and you click the Grafana charts for the second Cloudera Data Engineering service, metrics for the Virtual Cluster in the first Cloudera Data Engineering service will display.
- DEX-9112: VC deployment frequently fails when deployed through the CDP CLI
- In Cloudera Data Engineering 1.19, when a Virtual Cluster is deployed using the CDP CLI, it fails frequently as the pods fail to start. However, creating a Virtual cluster using the UI is successful.
- DEX-9879: Infinite while loops not working in Cloudera Data Engineering Sessions
- If an infinite while loop is submitted as a statement, the session will be stuck
infinitely. This means that new sessions can't be sent and the Session stays in a busy
state. Sample input:
while(True) { print("hello") }
- DEX-9898: CDE CLI input reads break after interacting with a Session
- After interacting with a Session through the
sessions interactcommand, input to the CDE CLI on the terminal breaks. In this example below, ^M displays instead of proceeding:> cde session interact --name sparkid-test-6 WARN: Plaintext or insecure TLS connection requested, take care before continuing. Continue? yes/no [no]: yes^M
- DEX-9881: Multi-line command error for Spark-Scala Session types in the CDE CLI
- In Cloudera Data Engineering 1.19, Multi-line input into a Scala session on
the CDE CLI will not work as expected, in some cases. The CLI interaction will throw an
error before reading the complete input. Sample
input:
scala> type |
- DEX-9756: Unable to run large raw Scala jobs
- Scala code with more than 2000 lines could result in an error.
- DEX-8679: Job fails with permission denied on a RAZ environment
- When running a job that has access to files is longer than the delegation token renewal
time on a RAZ-enabled Cloudera environment, the job will
fail with the following
error:
Failed to acquire a SAS token for get-status on /.../words.txt due to org.apache.hadoop.security.AccessControlException: Permission denied.
- DEX-3706: The Cloudera Data Engineering home page not displaying for some users
- The Cloudera Data Engineering home page will not display Virtual Clusters or a Quick Action bar if the user is part of hundreds of user groups or subgrooups.
- DEX-8283: False Positive Status is appearing for the Raw Scala Syntax issue
- Raw Scala jobs that fail due to syntax errors are reported as succeeded by Cloudera Data Engineering as displayed in this
example:
spark.range(3)..show()
- DEX-8281: Raw Scala Scripts fail due to the use of the case class
- Implicit conversions which involve implicit Encoders for case classes, that are usually
supported by importing spark.implicits._, don't work in Raw Scala jobs in Cloudera Data Engineering. These include converting Scala objects, including RDD
Dataset DataFrame, and Columns. For example, the following operations will fail on Cloudera Data Engineering:
import org.apache.spark.sql.Encoders import spark.implicits._ case class Case(foo:String, bar:String) // 1: an attempt to obtain schema via the implicit encoder for case class fails val encoderSchema = Encoders.product[Case].schema encoderSchema.printTreeString() // 2: an attempt to convert RDD[Case] to DataFrame fails val caseDF = sc .parallelize(1 to 3) .map(i => Case(f"$i", "bar")) .toDF // 3: an attempt to convert DataFrame to Dataset[Case] fails val caseDS = spark .read .json(List("""{"foo":"1","bar":"2"}""").toDS) .as[Case]
- DEX-7051
EnvironmentPrivilegedUserrole cannot be used with Cloudera Data Engineering - The role
EnvironmentPrivilegedUsercannot currently be used by a user if a user wants to access Cloudera Data Engineering. If a user has this role, then this user will not be able to interact with Cloudera Data Engineering as an "access denied" would occur. - Strict DAG declaration in Airflow 2.2.5
- Cloudera Data Engineering 1.16 introduces Airflow 2.2.5
which is now stricter about DAG declaration than the previously supported Airflow version
in Cloudera Data Engineering. In Airflow 2.2.5, DAG timezone should be a
pendulum.tz.Timezone, notdatetime.timezone.utc. - COMPX-6949: Stuck jobs prevent cluster scale down
-
Because of hanging jobs, the cluster is unable to scale down even when there are no ongoing activities. This may happen when some unexpected node removal occurs, causing some pods to be stuck in Pending state. These pending pods prevent the cluster from downscaling.