Creating a new deployment
Follow these instructions if you want to deploy a new cluster to run your flow.

Name your flow and deployment, and assign it to a project
On the Overview page provide deployment and flow names, and assign the deployment to a project. You can also import a previously exported deployment configuration, auto-filling configuration values and speeding up deployment.
-
Select a Target Project for your deployment from the
list of Projects available to you.
- If you do not want to assign the deployment to any of the available
Projects, select
 Unassigned. Unassigned
deployments are accessible to every user with DFFlowUser role in the
environment.
Unassigned. Unassigned
deployments are accessible to every user with DFFlowUser role in the
environment.
- If you do not want to assign the deployment to any of the available
Projects, select
-
Click Next .
Configure NiFi
After selecting the target environment, project, and naming your flow, you need to set Apache NiFi version, possible inbound connections, and custom processors. Depending on the flow definition, you may also need to provide values for a number of configuration parameters. Finally, you need to set the capacity of the NiFi cluster servicing your deployment.
-
Click Next .
Provide parameter values
Depending on the flow you deploy, you may need to specify parameter values like connection strings or credentials, and upload files like truststores or JARs.
-
When you finish setting configuration parameters, click Next .
-
You may edit parameters individually by clicking the edit
 icon next to them
or you may edit entire parameter groups by selecting the Edit
Group option.
icon next to them
or you may edit entire parameter groups by selecting the Edit
Group option.
In either case, you have the option to define a custom parameter value that is specific to this deployment or, if available, select the value from a shared parameter group.
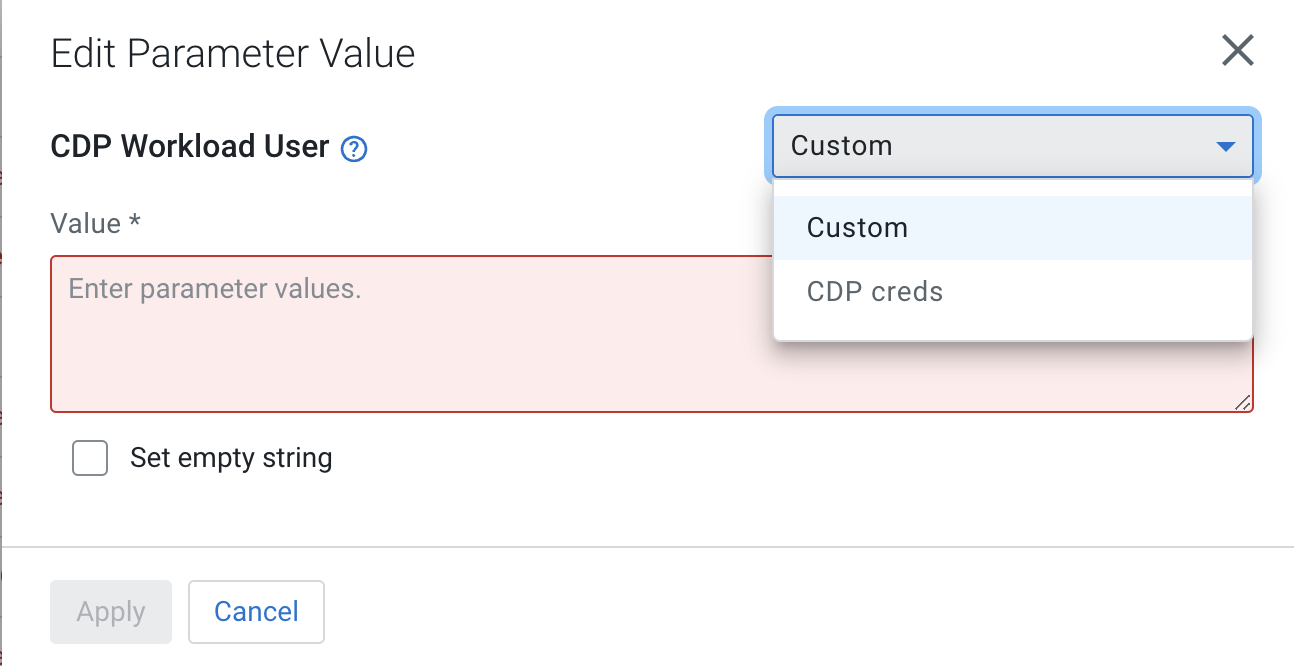
-
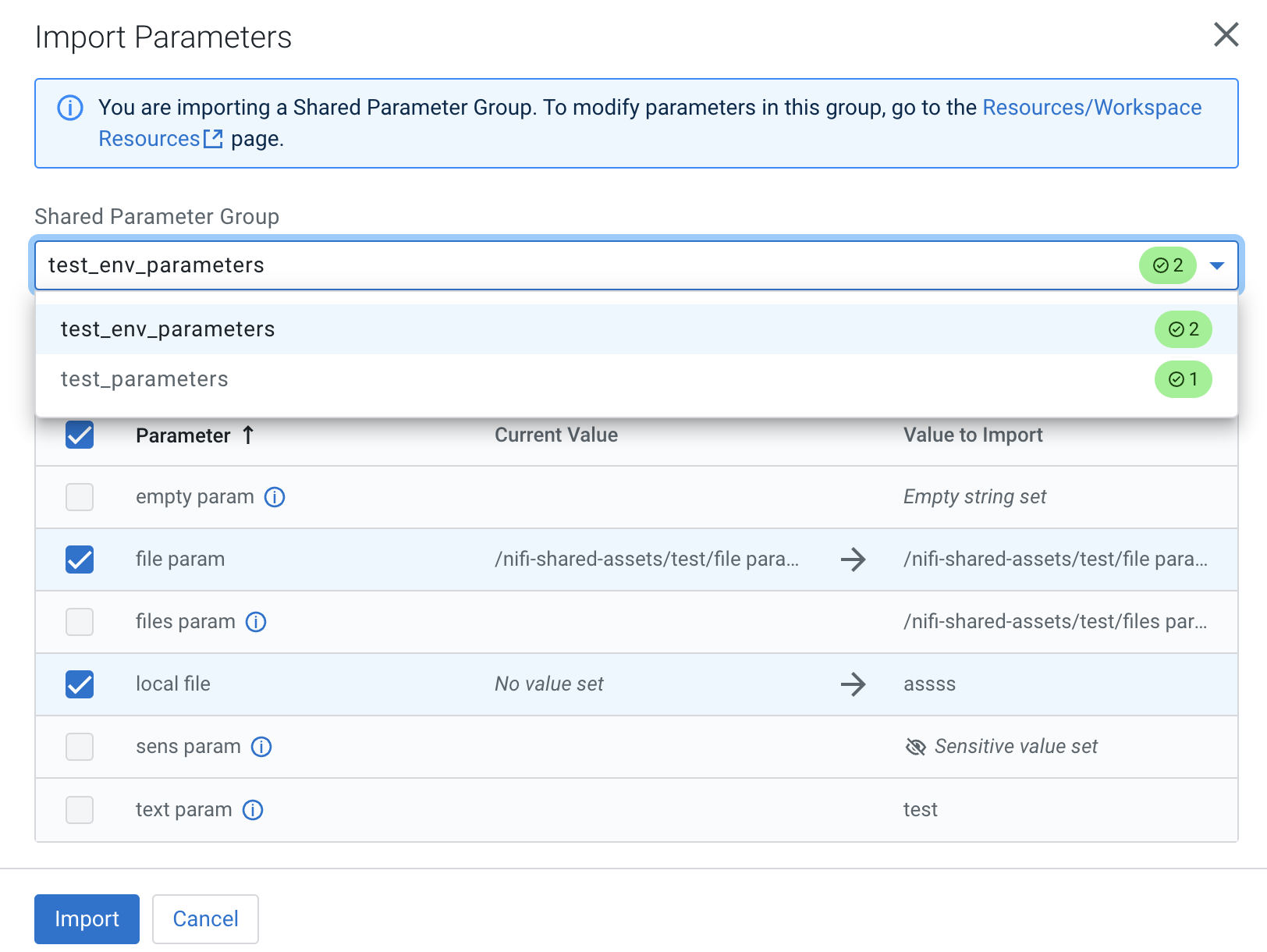
You may import a set of shared parameters from a parameter group to fill in
values and facilitate flow deployment. To do so, select the
 Import Shared Parameters option.
Import Shared Parameters option.
-
Parameters in the shared group that match a deployment parameter are preselected, unless you have already modified that parameter in the deployment wizard. In that case that particular parameter is left unselected to protect any changes you have already made and you need to manually select that parameter.
-
Configure sizing and scaling
Set the size and number of Apache NiFi nodes, auto-scaling, and the type of storage to be used.
-
Click Next .
Set Key performance indicators
Optionally add key performance indicators to help you track the performance of your flow deployment then review your settings and launch the deployment process.
-
Click Next .
Verify your settings and initiate deployment
Review deployment settings, make any necessary changes, and start deployment.
-
Review a summary of the information provided and make
any necessary edits by clicking
 Previous.
Previous.
After you click Deploy, you are redirected to the Alerts tab in the Flow Details where you can track how the deployment progresses.