Apache Kafka Overview
Part of the Hadoop ecosystem, Apache Kafka is a distributed commit log service that functions much like a publish/subscribe messaging system, but with better throughput, built-in partitioning, replication, and fault tolerance. Increasingly popular for log collection and stream processing, it is often (but not exclusively) used in tandem with Apache Hadoop, Apache Storm, and Spark Streaming.
A log can be considered as a simple storage abstraction. Because newer entries are appended to the log over time, from left to right, the log entry number is a convenient proxy for a timestamp. Conceptually, a log can be thought of as a time-sorted file or table.
Kafka integrates this unique abstraction with traditional publish/subscribe messaging concepts (such as producers, consumers, and brokers), parallelism, and enterprise features for improved performance and fault tolerance. The result is an architecture that, at a high level, looks like the following figure. (A topic is a category of messages that share similar characteristics.)
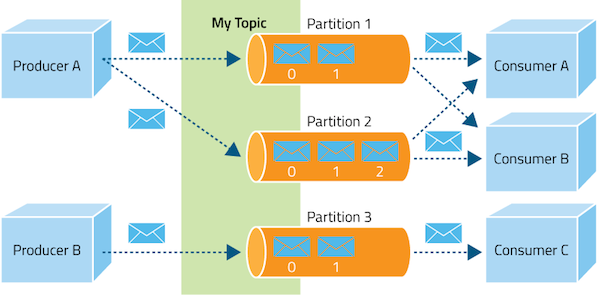
Kafka provides the following:
- Persistent messaging with O(1) disk structures that provide constant time performance, even with terabytes of stored messages.
- High throughput, supporting hundreds of thousands of messages per second, even with modest hardware.
- Explicit support for partitioning messages over Kafka servers and distributing consumption over a cluster of consumer machines while maintaining per-partition ordering semantics.
- Support for parallel data load into Hadoop.
