Example: Connect a Spark session to Hive Metastore in a Data Lake
After the Admin sets up the correct permissions, you can access the Data Lake from your project, as this example shows.
Make sure you have access to a Data Lake containing your data.
Setting up the project looks like this:
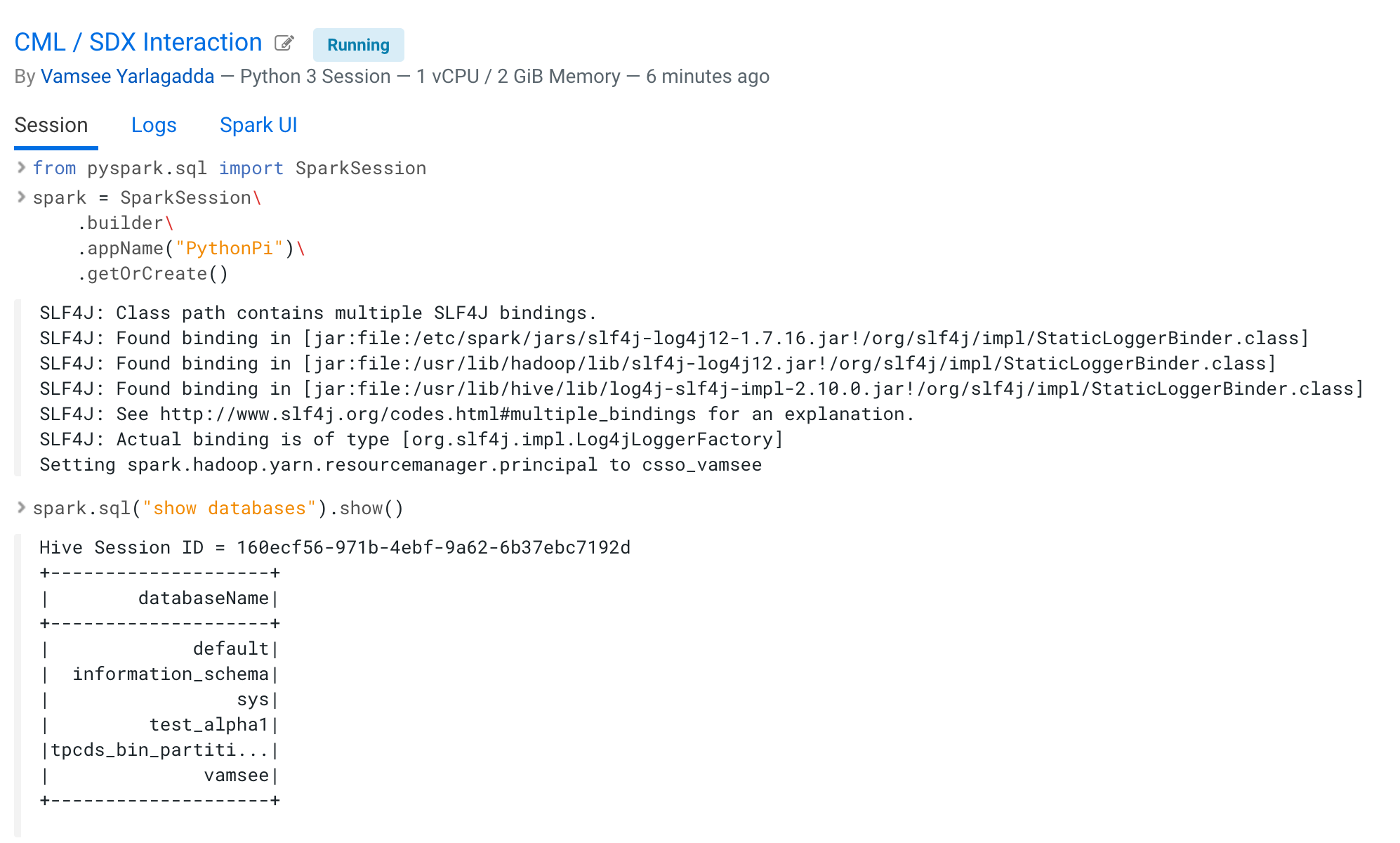
Now you can run Spark SQL commands. For example, you can:
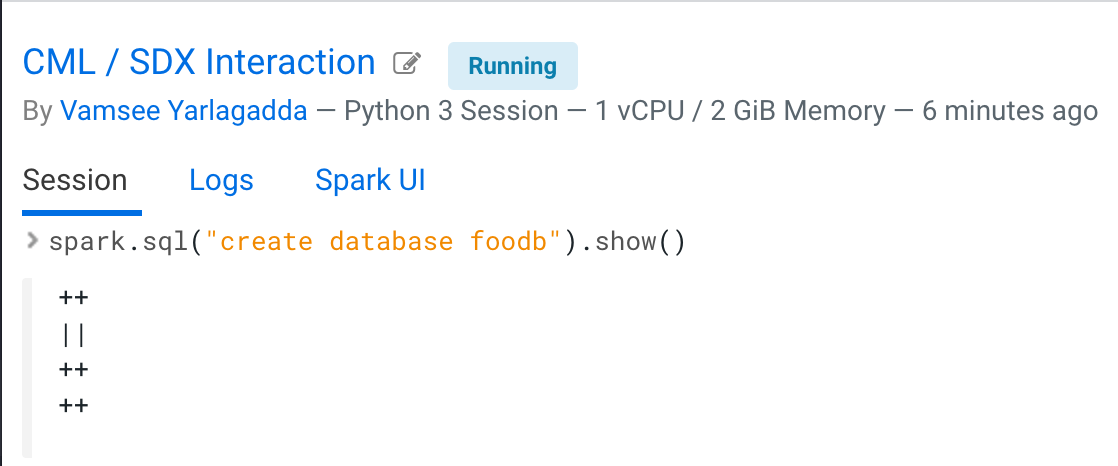
- Create a database foodb.
- List databases and tables.

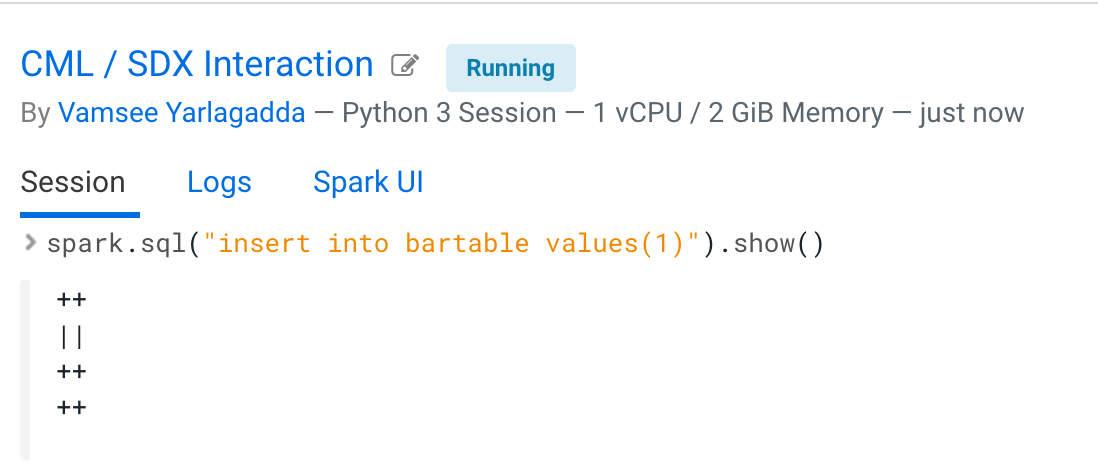
- Create a table bartable.

- Insert data into the table.
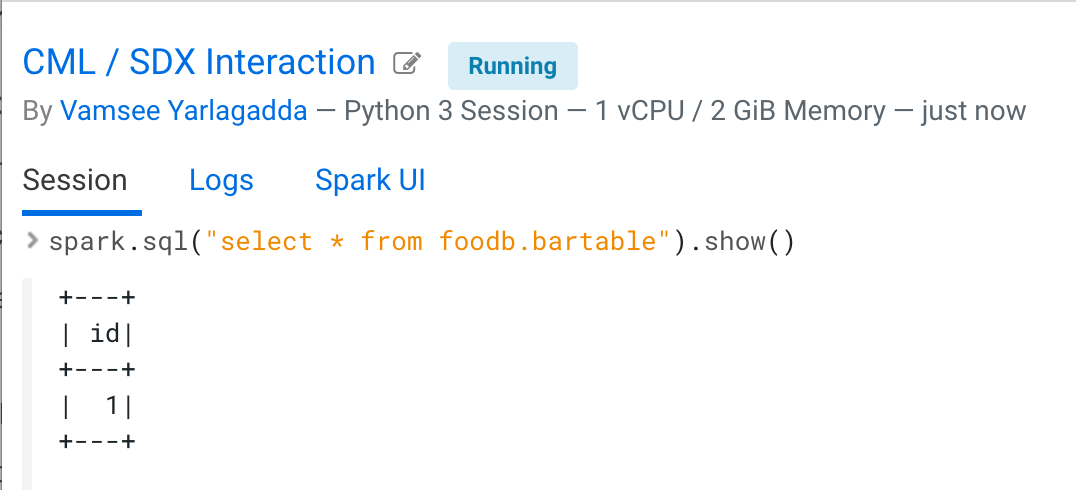
- Query the data from the table.