Creating a Cloudera Lakehouse Optimizer policy in Lakehouse Optimizer UI
After you complete the prerequisites, you can create the Cloudera Lakehouse Optimizer policies in the Lakehouse Optimizer UI. You can create one or more policies for a table to perform Iceberg table maintenance.
-
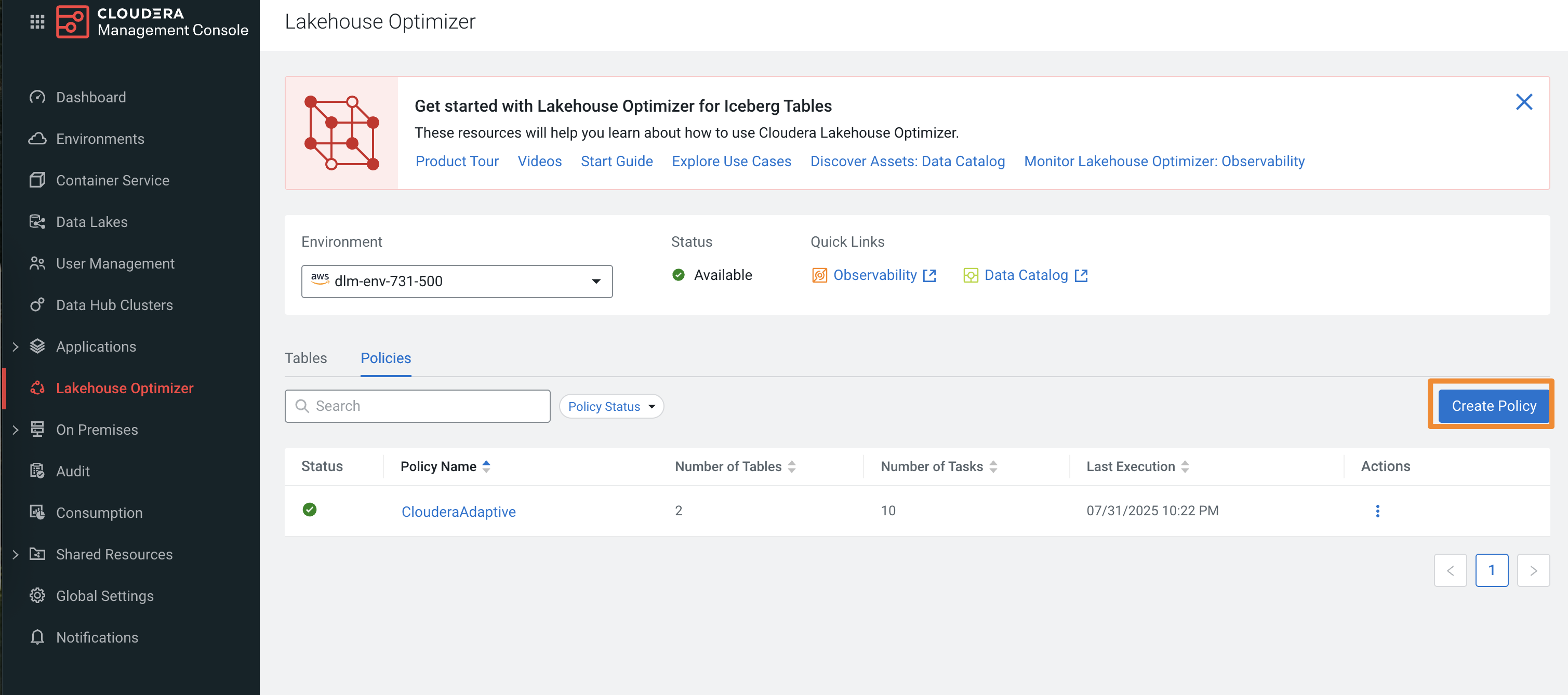
Click Create Policy to open the Create
Policy wizard.
-
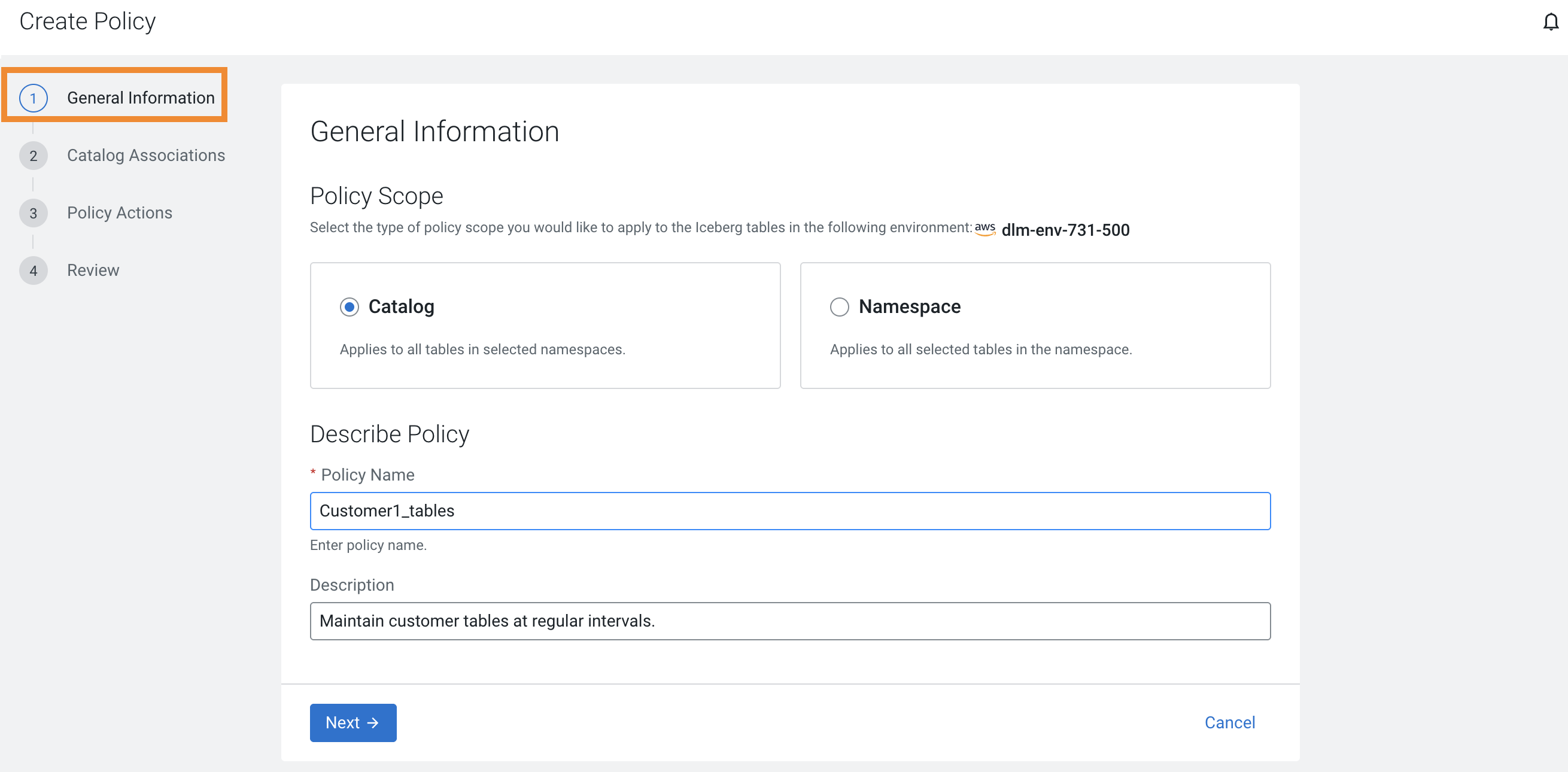
Enter the following details on the General Information
tab:
Option Description Catalog Choose the option to apply this policy to all the tables in all the selected namespaces. Namespace Choose the option to apply this policy to all the selected tables in the specified namespace. Policy Name Enter a unique policy name so that you can identify it later when required. Enter an underscore instead of spaces in the policy name. Description Optional. Enter a brief description that describes the table maintenance goal, and any other information that might help you and other users. The following image shows the General Information tab:
-
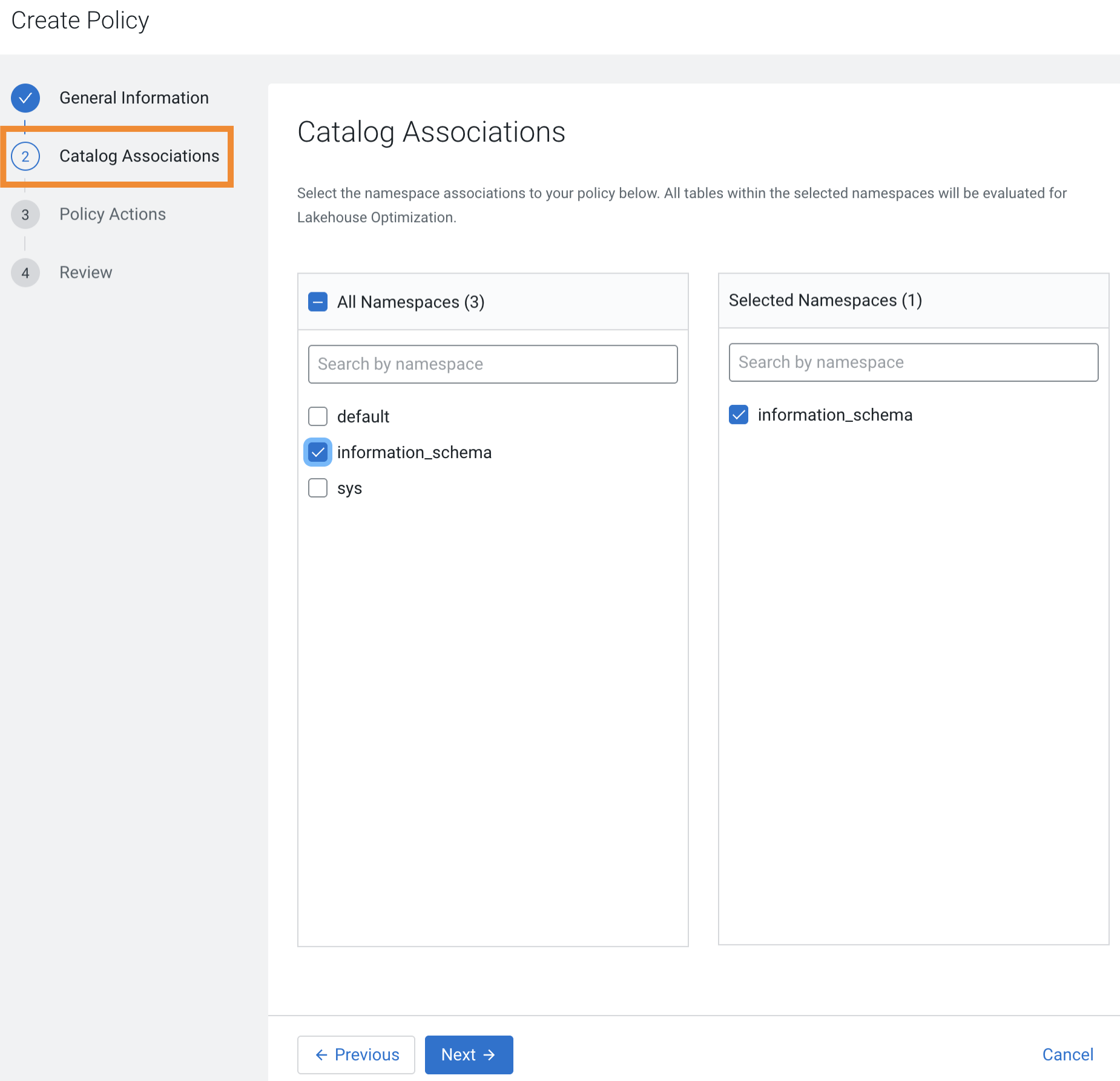
Enter the details in the next tab; the tab details appear depending on whether
you chose Catalog or Namespace on
the General Information tab:
Choice chosen on the General Information tab Options to select or choose Catalog Choose one or more namespaces to associate with the policy on the Catalog Associations tab. Namespace Choose or Add Another Namespace to associate with the policy. You can choose the tables in the namespace to associate with the policy. The following image shows the Catalog Associations tab and the tab details:
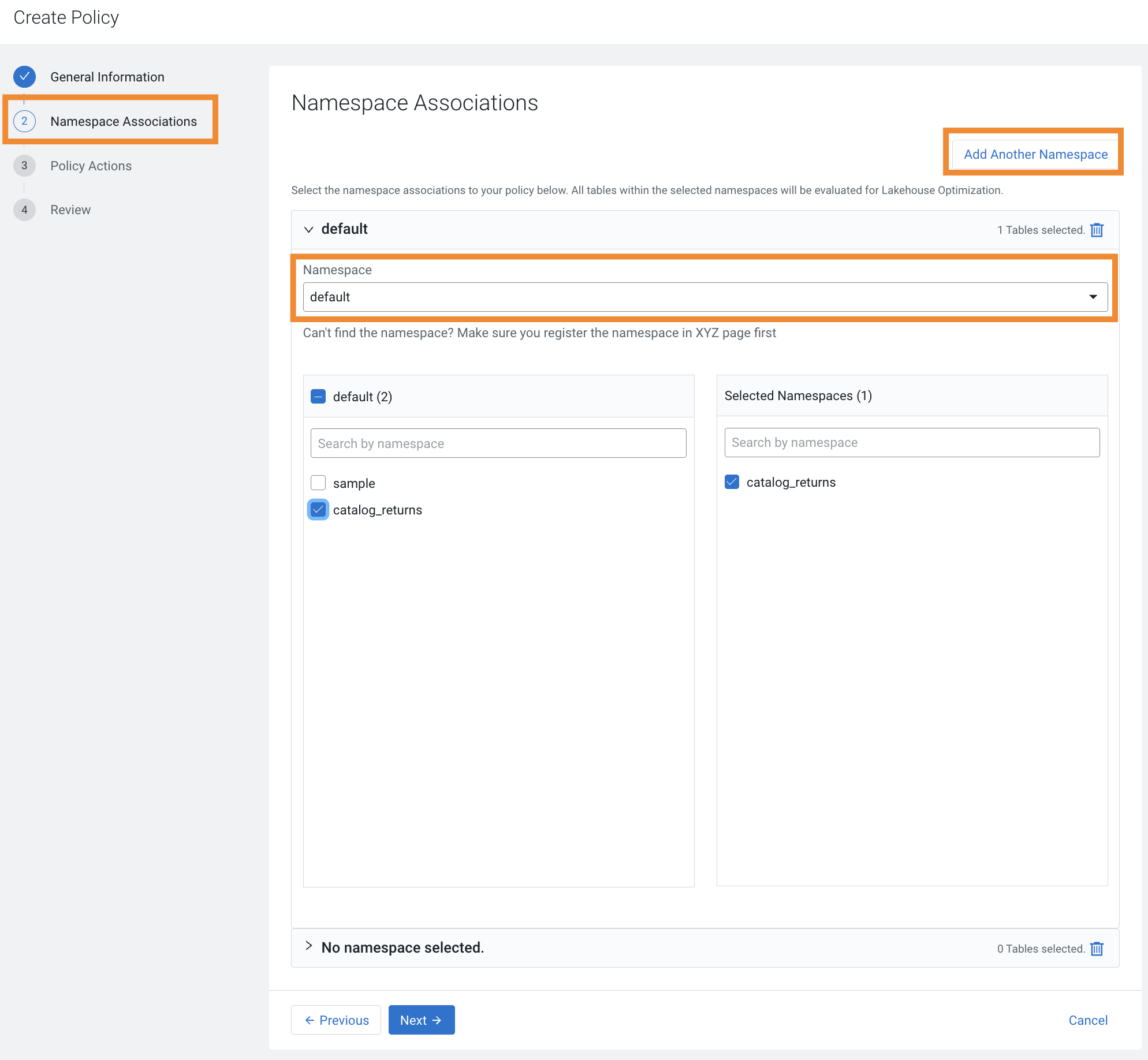
The following image shows the Namespace Associations tab and the tab details:
-
Enter the following details on the Policy Actions
tab:
Option Description Select Policy Choose ClouderaAdaptive. This is the default policy that you use as a template to create the new policy. Table Maintenance Schedule Choose Event Based to trigger the policy evaluation when the HMS events, such as insert, delete, and update operations complete. Choose Schedule Based to trigger the policy evaluation at regular intervals. You can choose the following options to run the policy: You can choose the following options to run the policy:- Select
Frequency as Daily,
Weekly on <current week day>,
Monthly on the first current <week
day>, Yearly on <today’s
date>, Every weekday (Monday to
Friday), or Custom CRON
scheduler.
You can generate a CRON expression using the https://www.freeformatter.com/cron-expression-generator-quartz.html page.
For example, the 0 */30 * ? * * expression schedules the policy to run every 30 minutes; the 0 0 */4 ? * * expression schedules the policy to run for every 4 hours; the 0 0 0 * * ? expression schedules the policy to run every day at midnight.
- Choose the Time Zone.
- Select the Hour.
- Select the Minutes.
Automated Actions Select and configure at least one of the maintenance tasks. Choose Expire Snapshot, and configure the following options to ensure compact metadata and optimal query performance. This action allows you to time travel to a previous version of the table, and allows you to control the snapshot retention settings for time travel queries and rollback. - Enter the Expire Older Than value in milliseconds. Cloudera Lakehouse Optimizer expires the snapshot older than the set value. The default value is 432000000 ms (7200 minutes).
- Enter the Retain Last value to specify the number of snapshots to retain. Cloudera Lakehouse Optimizer deletes the older snapshots when the set value is reached. The default value is 5. For example, by default the first snapshot gets deleted automatically after the sixth snapshot is created.
- Optional. Enter the snapshot ID in the Expire Snapshot with ID field. Cloudera Lakehouse Optimizer expires the specified snapshot. There is no default value.
- Toggle Clean Expired File to remove the expired snapshots permanently. The default value is true.
Choose Compaction settings, and configure the following options to improve query performance. This action compacts small files into larger ones, thereby optimizing storage and improving read performance. - Enter the Target File Size in bytes. Cloudera Lakehouse Optimizer merges the small files into a larger file of the specified size. The default value is 536870912 bytes. Improves the query performance because of larger optimally sized files.
- Enter the Max Concurrent Rewrite File Groups value to specify the maximum number of file groups to be simultaneously rewritten. The default value is 5. Improves the compaction performance and rewrite operations.
- Enter the Minimum Input Files value to specify the minimum number of files in a file group. Any file group exceeding the set number of files is rewritten into a larger data file regardless of other criteria. The default value is 5. Optimizes data management and improves query performance.
- Enter the Partial Progress Max Commits value to specify the maximum number of commits that are allowed during the rewrite operation. This ensures that the changes are committed and the snapshots are created even while the rewrite operation is in progress. The default value is 10. Ensures that the longer rewrite operation is chunked, and the commits are performed as the operation proceeds.
- Enter the Delete File Threshold value to specify the minimum number of delete files that must be associated with a data file, after which those delete files are rewritten into a larger data file. The default value is 2000000. Optimizes the read operations.
- Choose Partial Progress Enabled to ensure that the completed parts of the rewrite operation are committed. The default value is false. Improves performance, fault tolerance, and prevents out of memory (OOM) issues.
- Choose Use Starting Sequence Number to use the sequence number of the snapshot at compaction operation start time instead of the newly produced snapshot. The default value is false. Optimizes the performance.
- Choose Rewrite All to force rewrite all the files overriding other options. The default value is false. Ensures full compaction of the tables.
Choose Rewrite Manifest, and configure the following options to consolidate multiple small manifest files (metadata files) into a larger manifest file, remove the deleted data references, and ensure that the manifest files are efficiently structured which in turn improves the metadata scan performance. - Enter the Target File Size value to specify the target manifest file size in bytes. The default value is 8388608. Improves query performance and optimizes metadata management.
- Choose Use Caching to cache the manifest files in memory. The default value is true. Improves query planning and performance.
Choose Delete Orphan Files, and configure the Remove Orphan Files Older Than value to identify and remove the data files that are no longer referenced by any table metadata. These files are called orphan files, and might exist due to failed writes, manual deletions, or schema changes. Enter the Remove Orphan Files Older Than value to specify the time duration in milliseconds to remove the orphan files that meet the criteria. This action reclaims storage space, maintains data integrity, and ensures the storage footprint of Iceberg tables are as efficient as possible.
Choose Rewrite Position Delete Files, and configure the following options to optimize the size and layout of the positional delete files in the Iceberg tables by compacting small positional delete files into larger ones, and filtering out positional delete records that refer to data files that are no longer available. - Enter the Target File Size value to specify the target positional delete file size in bytes. Cloudera Lakehouse Optimizer merges the small positional delete files into a larger file of the specified size. The default value is 67108864 bytes.
- Enter the Max Concurrent Group Rewrite value to specify the maximum number of file groups to be simultaneously rewritten. The default value is 5. Reduces rewrite operation time.
- Enter the Minimum Input Files value to specify the minimum number of files in a file group. Any file group exceeding this number of files is rewritten in a larger data file regardless of other criteria. The default value is 5. Optimizes data management.
- Enter the Partial Progress Max Commits value to specify the maximum number of commits that are allowed during the rewrite operation. This ensures that the changes are committed and the snapshots are created even while the rewrite operation is in progress. The default value is 10. Ensures that the longer rewrite operation is chunked, and the commits are performed as the operation proceeds.
- Choose Partial Progress Enabled to ensure that the completed parts of the rewrite operation are committed. The default value is true. Improves performance and fault tolerance.
- Choose one of the following
Rewrite Job Older options
to force the rewrite job order based on the chosen
value:
- bytes (asc) rewrites the smallest job groups first.
- bytes (desc) rewrites the largest job groups first.
- files (asc) rewrites the job groups with the least number of files first.
- files (desc) rewrites the job groups with the most files first.
- none rewrites the job groups in the order they were planned.
The default value is none.
The following GIF shows the Policy Actions tab and the tab details: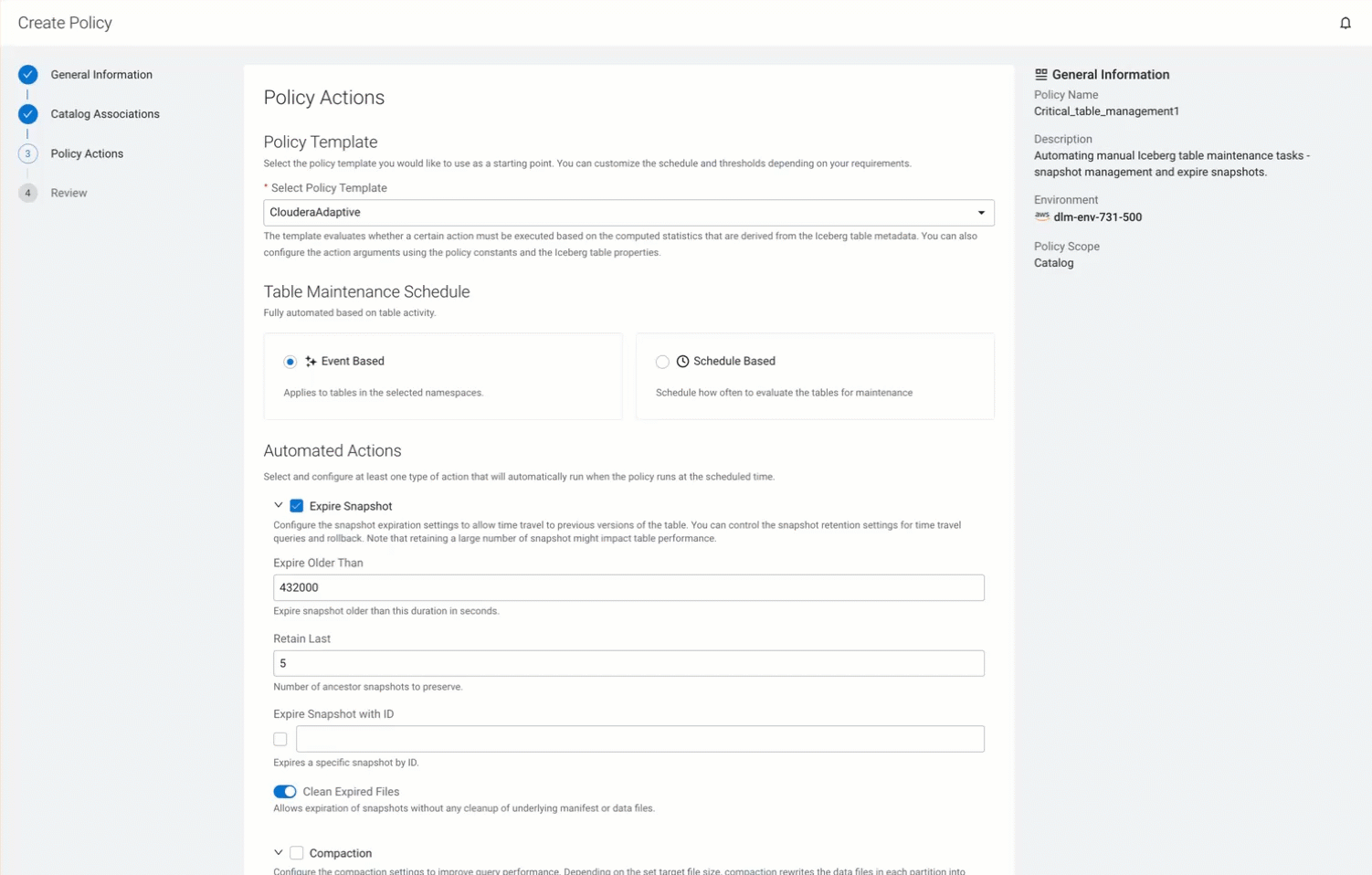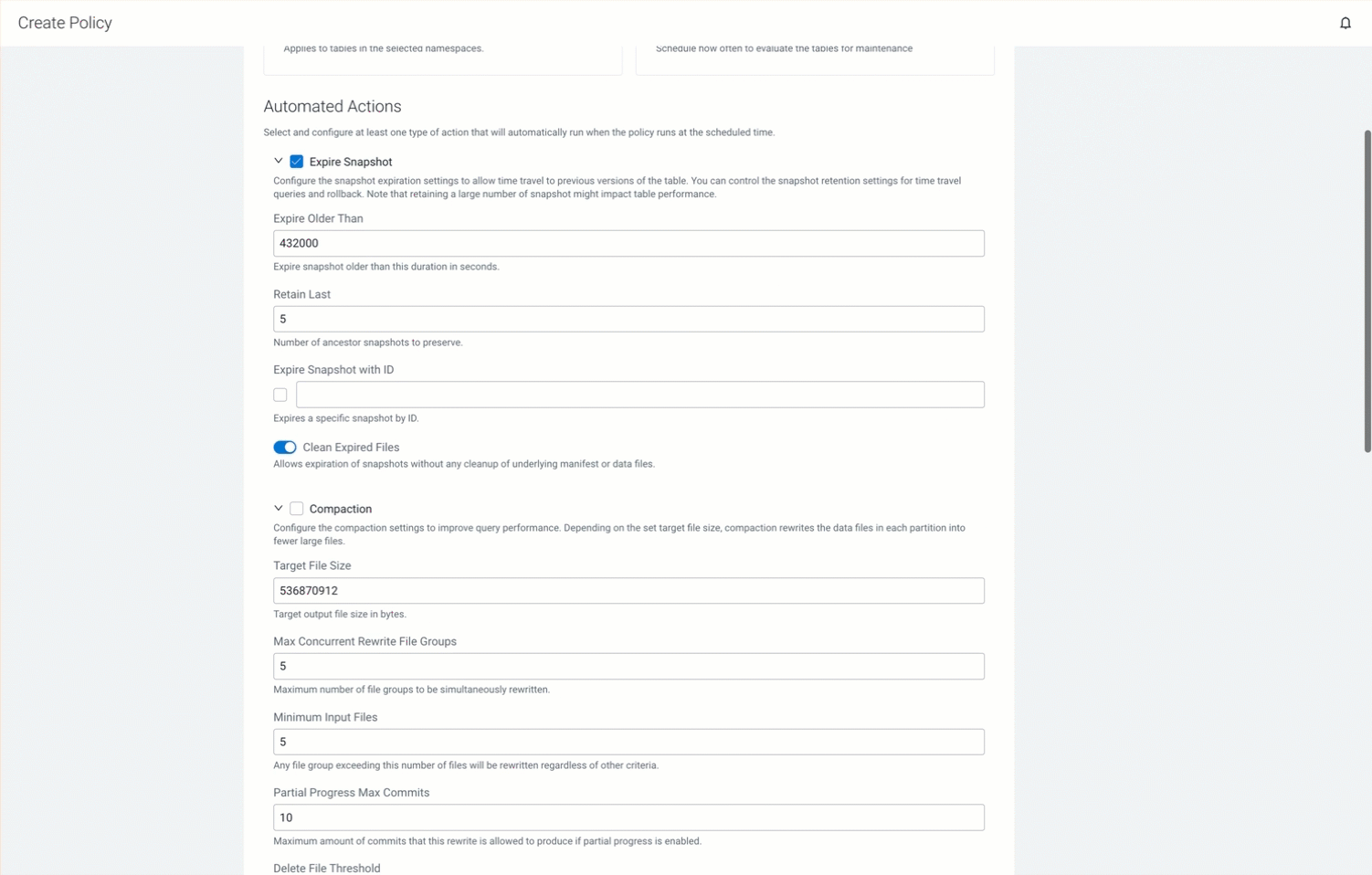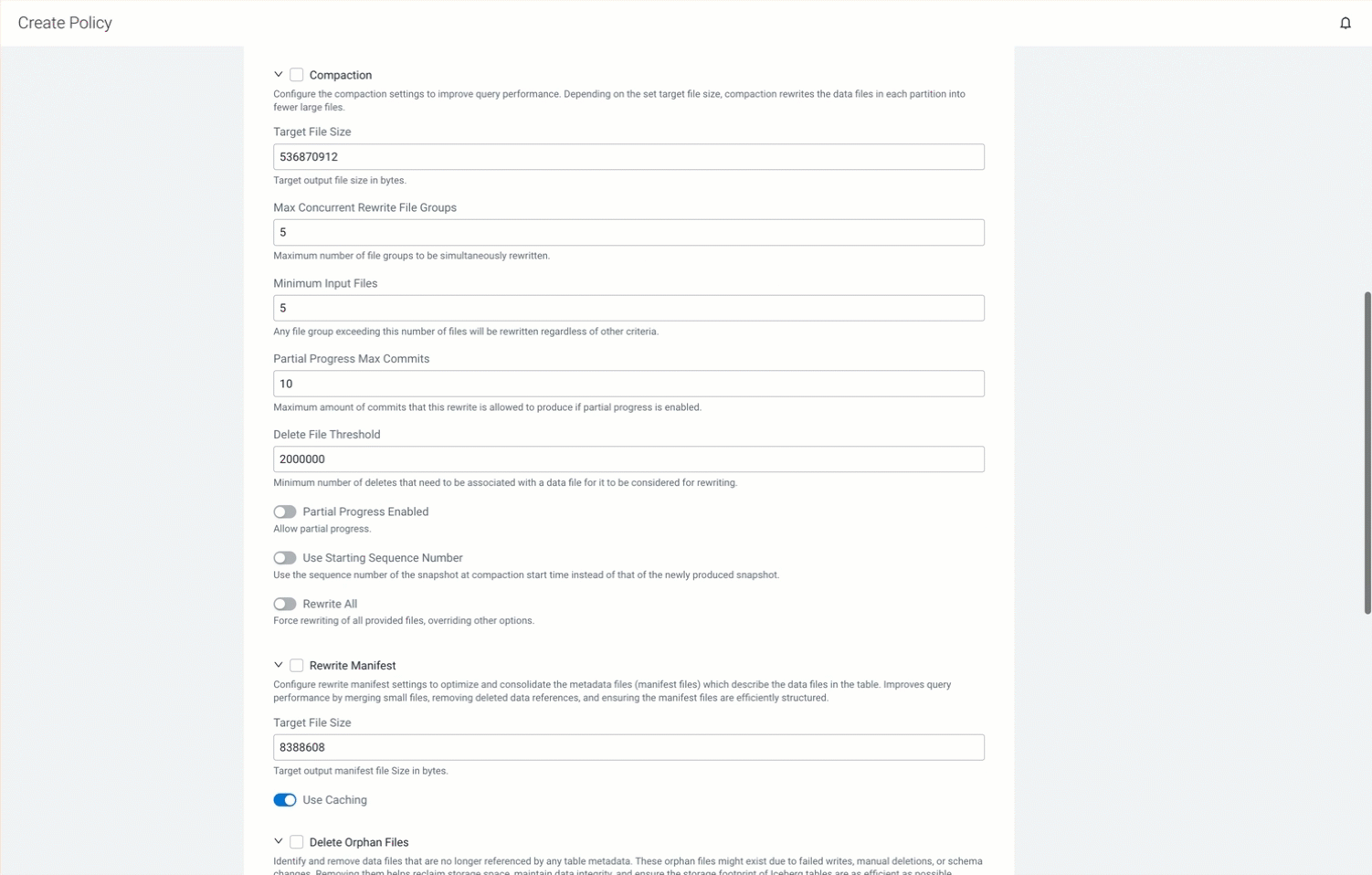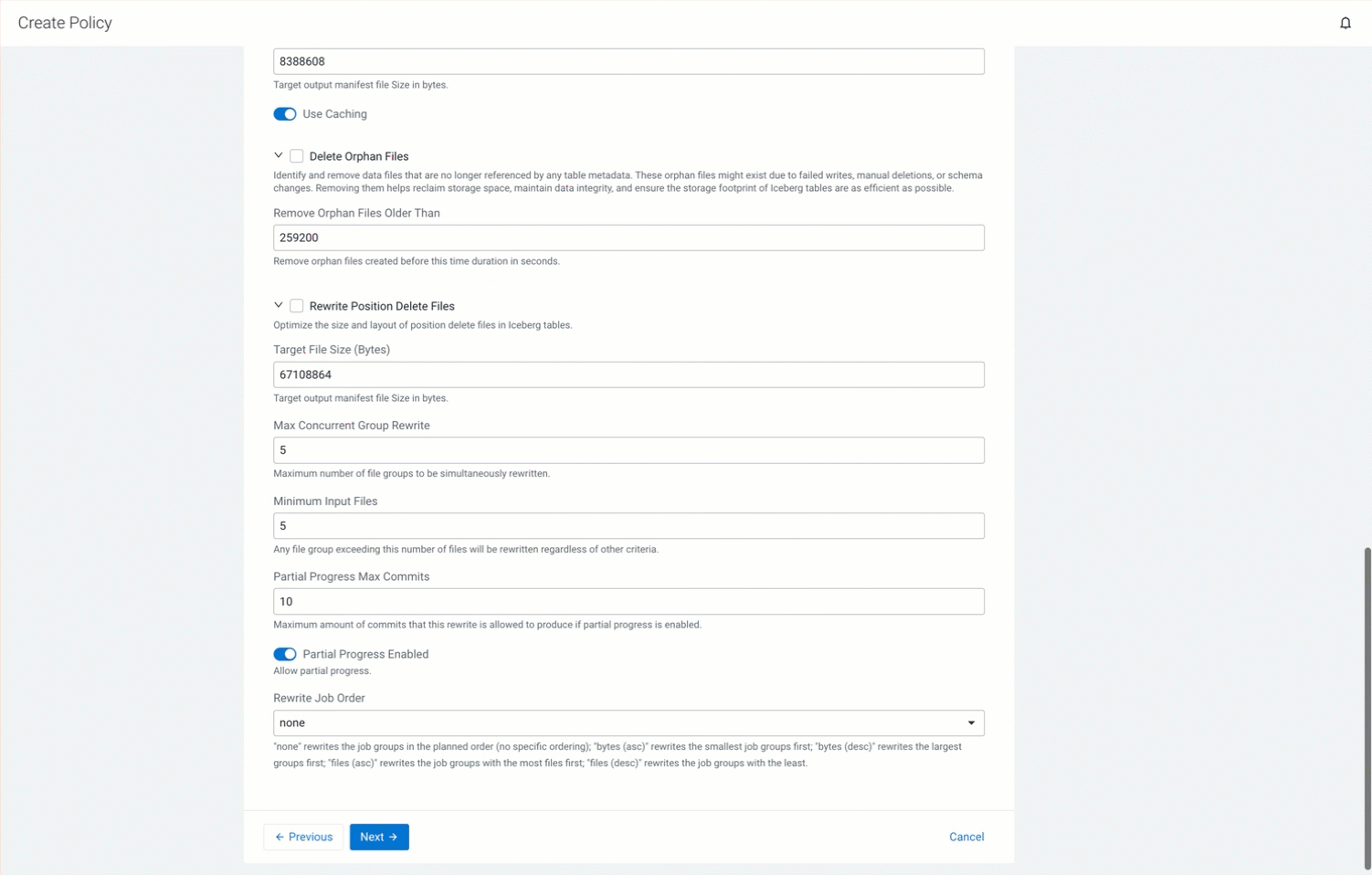
- Select
Frequency as Daily,
Weekly on <current week day>,
Monthly on the first current <week
day>, Yearly on <today’s
date>, Every weekday (Monday to
Friday), or Custom CRON
scheduler.
-
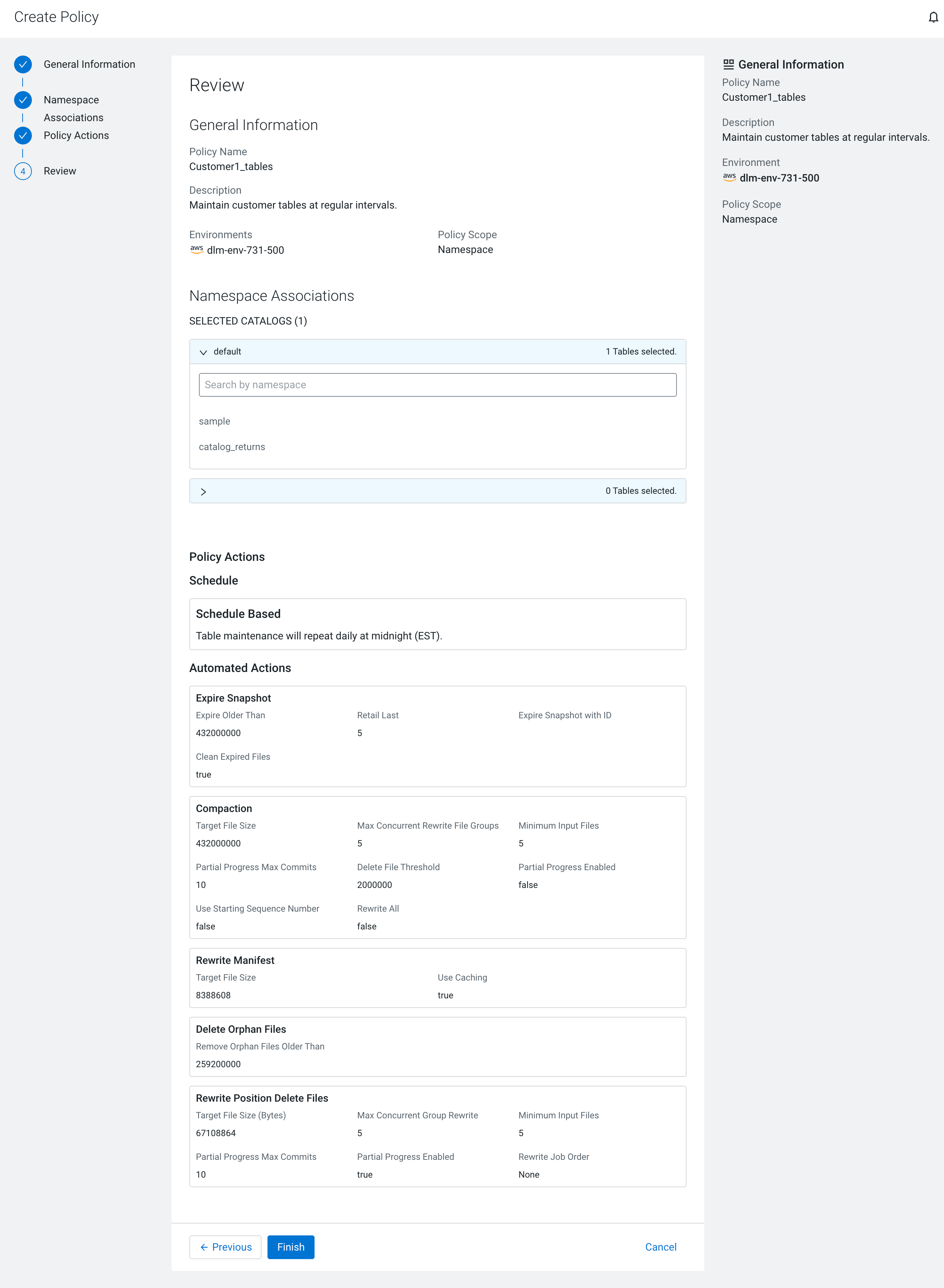
Verify the settings on the Review tab.
The following image shows the Review tab:
- View the policy run details on the tab.
- View the chosen tables’ maintenance details on the tab.
- Verify whether the table maintenance completed successfully on the tab.
- Monitor the policy jobs as Spark jobs on the Cloudera Observability dashboard. For more information, see Monitoring table maintenance tasks on Cloudera Observability dashboard.
- View the various methods that are available to monitor the table maintenance tasks.
Additionally, you can pause and resume table maintenance on the Policies tab to manage policies.