Hive Server 2 entities created in Atlas
Each Hive Server 2 entity in Atlas includes detailed metadata collected from Hive.
The following diagrams show a summary of the entities created in Atlas for Hive operations and assets. The supertypes that contribute attributes to the entity types are shaded.
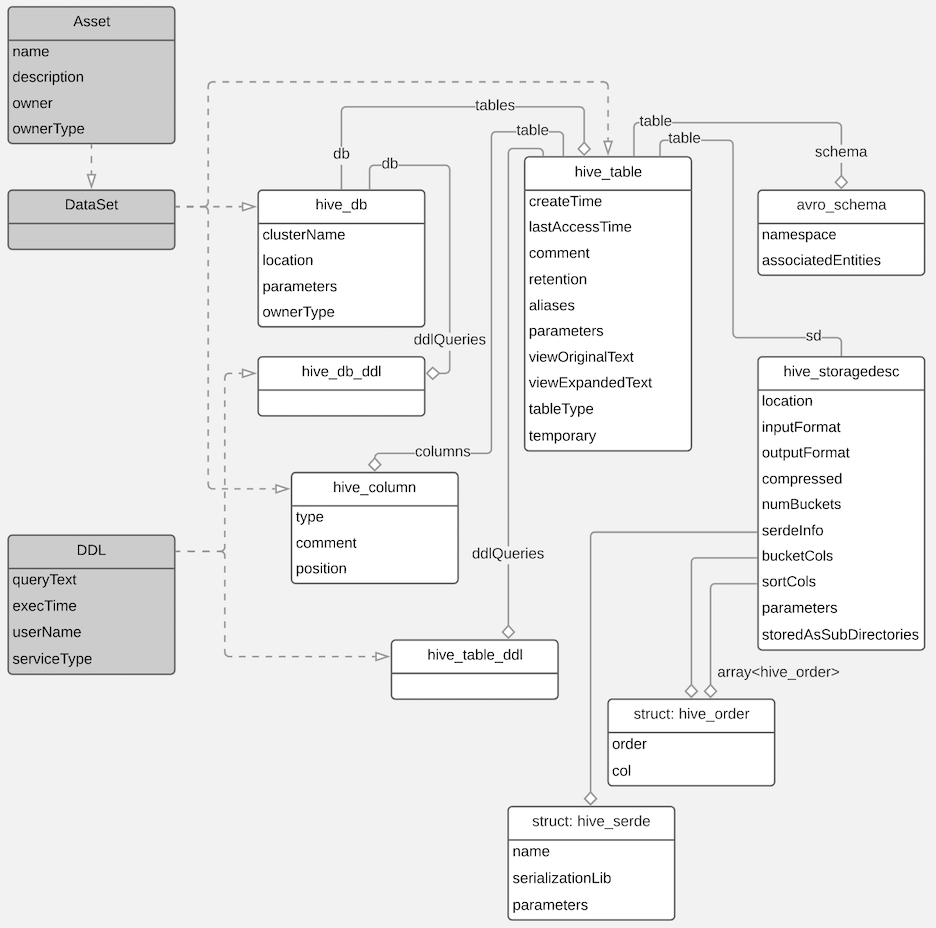
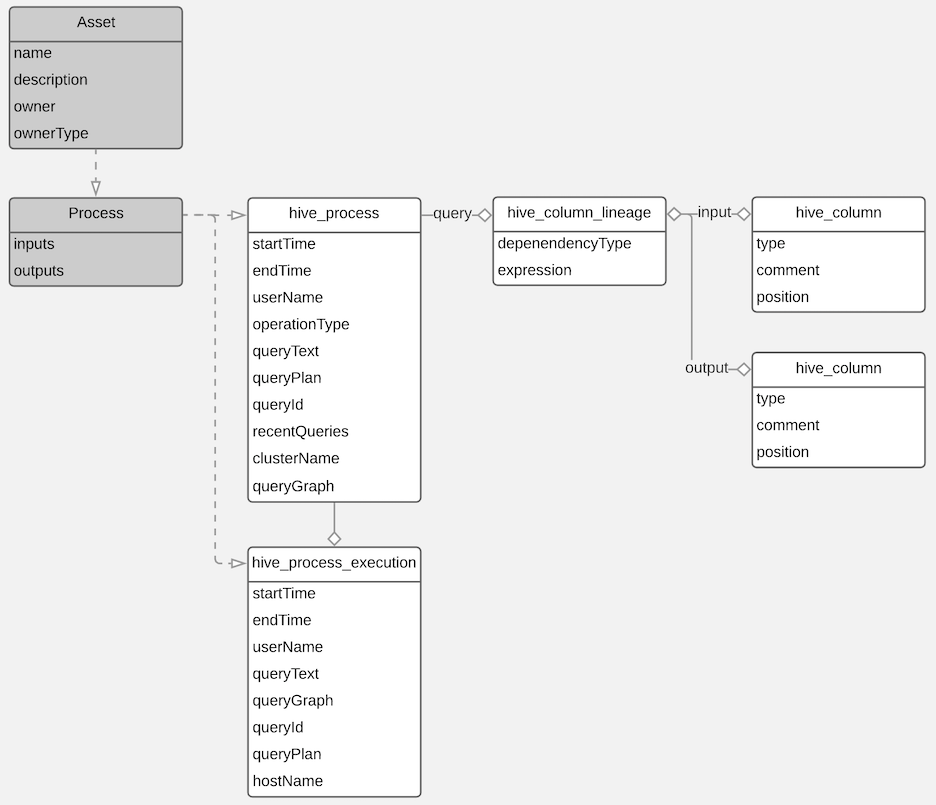
The metadata collected for each entity type is as follows:
Hive Process
| Identifier | Example content |
|---|---|
| typeName | hive_process |
| guid | System generated ID. This value is used to identify the entity in the Atlas Dashboard URL. |
| qualifiedName |
The generated ID is distinct from the GUID. |
| name | Text of the query. |
| inputs | List of the input tables or views, including each entity’s type name and the qualified name. |
| outputs | List of the output objects, including each entity’s type name and the qualified name. |
| recentQueries | Last query executed (duplicated in
process_execution). |
| operationType | One of the operations that triggers metadata collection. |
| queryPlan | Reserved for future use. |
Hive Process Execution
| Identifier | Example Content |
|---|---|
| typeName | hive_process_execution |
| guid | System generated ID. This value is used to identify the entity in the Atlas Dashboard URL. |
| qualifiedName | <database>.<target
table>@<clustername>:<ID from process qualified
name>:<ID from the process execution name>:<generated
ID for this process execution> |
| name | Text of the query with a system-generated ID added to the end. |
| queryText | Text of the query. |
| queryPlan | Reserved for future use. |
| queryId | impala_<date as
yyyymmddhhmmss>_<generated id> |
| startTime | Query start time. |
| endTime | Query end time. |
| userName | The user who ran the query. |
| Relationship: Process | One process to one or more process
executions. hive_process_process_execution |
Hive Database
| Identifier | Example Content |
|---|---|
| typeName | hive_db |
| guid | System generated ID. This value is used to identify the entity in the Atlas Dashboard URL. |
| qualifiedName | <database>@<clustername> |
| name | Database name as reported from Hive. |
| clusterName | Cluster name. |
| location | The file system path where the backing files for the database are stored. This could be an HDFS path, an AWS S3 object, or an Azure data storage location. |
| owner | The user who initially created the database. |
| ownerType | The principal type of the database owner. Could be USER, ROLE, or GROUP. |
| parameters | Additional key-value pair metadata that comes from Hive such as table size, number of rows, and number of storage files. |
| Relationship: Table | One database to many tables.
hive_table_db |
| Relationship: Database DDL | One database to many database DDL entities.
hive_db_ddl_queries |
Hive Table
| Identifier | Example Content |
|---|---|
| typeName | hive_table |
| guid | System generated ID. This value is used to identify the entity in the Atlas Dashboard URL. |
| qualifiedName | <database>.<tablename>@<clustername> |
| name | Table name. |
| columns | List of the columns defined in the table. The Atlas Dashboard shows these as links to the column entity details. |
| owner | The user who created the table. |
| parameters |
Table details from Hive Server 2 such as:
|
| retention | Provided by HS2. Integer value |
| sd |
The location of the table data, the storage description.
|
| tableType | How the table was created: one of EXTERNAL_TABLE, VIRTUAL_VIEW, or MANAGED_TABLE. |
| Relationship: Database | One database to many tables.
hive_table_db |
| Relationship: Columns | One table to one or more columns.
hive_table_columns |
| Relationship: Partition Key Column | One table to one or more columns that are
partition keys. hive_table_partitionkeys |
| Relationship: Storage Description | One table to one storage description.
hive_table_storagedesc |
| Relationship: DDL | One table to many DDL entities.
hive_table_ddl_queries |
Hive Column
| Identifier | Example Content |
|---|---|
| typeName | hive_column |
| comment | Metadata from Hive from the column description. |
| name | Column name as reported by HMS. |
| owner | Table owner name as reported by HMS. |
| position | This column’s position in the list of columns in a zero-based index. |
| qualifiedName | <database>.<table>.<column>@<clustername> |
| table | Table name. Also modeled as relationship. |
| type | Column data type as reported by HMS. |
| Relationship: table | One table to one or more columns.
hive_table_columns |
| Relationship: inputToProcesses | The hive_column_lineage entities that include
this column in the input to a transformation. The relationship
type is dataset_process_inputs. |
| Relationship: outputFromProcesses | The hive_column_lineage entities that include
this column in the output to a transformation. The relationship
type is process_dataset_outputs. |
| Relationship: Table | One table to one or more columns.
hive_table_columns |
| Relationship: Partition Key Column | One table to one or more columns that are
partition keys. hive_table_partitionkeys |
Hive Column Lineage
| Identifier | Example Content |
|---|---|
| typeName | hive_column_lineage |
| dependencyType | The type of relationship between the input and output columns; one of SIMPLE, EXPRESSION, or SCRIPT. |
| name | <database>.<table>@<clustername>:<generated
ID>:<output_column> |
| inputs |
List of 0 or more |
| outputs | This is a legacy model component: the more current model uses a relationship attribute. |
| qualifiedName | Same as name. |
| query | Name of the hive_process entity that
produced this lineage. This is a legacy model component: the
more current model uses a relationship attribute. |
| Relationship: Process | Name of the hive_process entity that
produced this lineage. hive_process_column_lineage |
| Relationship: inputToProcesses | List of 0 or more hive_column entities
that contributed to the output columns. |
| Relationship: outputFromProcesses | List of 0 or more hive_column entities
that were produced in the process. |
Hive Storage Description
| Identifier | Example Content |
|---|---|
| typeName | hive_storagedesc |
| compressed | Metadata from Hive indicating whether the table is stored compressed. |
| inputFormat | Metadata from Hive indicating the storage input format. |
| outputFormat | Metadata from Hive indicating the storage output format. |
| parameters | Additional metadata from Hive in the form of key-value pairs. |
| qualifiedName | <database>.<table>@<clustername>_storage |
| serdeInfo | Metadata from Hive indicating the serialization/deserialization implementation used to write/read table data. |
| sortCols | Metadata from Hive listing the column or columns used to sort the table data. |
| storedAsSubDirectories | Metadata from Hive indicating whether a skewed table uses the list bucketing feature, which creates subdirectories for skewed values. |
| numBuckets | Metadata from Hive indicating the number of buckets for bucketed tables. Non-bucketed tables are indicated by -1. |
| table | The table that this storage description holds data for. Also represented as a relationship. |
| Relationship: table | The table that this storage description holds data for. |