
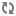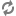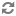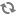
1.2.8.2. Hive LLAP - Overview
Shows the aggregated information across all of the clusters. For example, the total cache memory from all the nodes. This dashboard allows you to see that your cluster is configured and running correctly. For example, you might have configured 10 nodes but only see executors and cache accounted for 8 nodes running.
If you find an issue in this dashboard, open the LLAP Daemon dashboard to see which node is having the problem.
| Row | Metrics |
Description |
|---|---|---|
|
Overview |
Total Executor Threads |
Shows the total number of executors across all nodes. |
|
Total Executor Memory | Shows the total amount of memory for executors across all nodes. | |
| Total Cache Memory | Shows the total amount of memory for cache across all nodes. | |
| Total JVM Memory | Shows the total amount of max Java Virtual Machine (JVM) memory across all nodes. | |
|
Cache Metrics Across all nodes |
Total Cache Usage | Shows the total amount of cache usage (Total, Remaining, and Used) across all nodes. |
| Average Cache Hit Rate | As the data is released from the cache, the curve should increase. For example, the first query should run at 0, the second at 80-90 seconds, and then the third 10% faster. If, instead, it decreases, there might be a problem in the cluster. | |
| Average Cache Read Requests | Shows how many requests are being made for the cache and how many queries you are able to run that make use of the cache. If it says 0, for example, your cache might not be working properly and this grid might reveal a configuration issue. | |
|
Cache Metrics Across all nodes |
Total Cache Usage | Shows the total amount of cache usage (Total, Remaining, and Used) across all nodes. |
| Average Cache Hit Rate | As the data is released from the cache, the curve should increase. For example, the first query should run at 0, the second at 80-90 seconds, and then the third 10% faster. If, instead, it decreases, there might be a problem in the cluster. | |
| Average Cache Read Requests | Shows how many requests are being made for the cache and how many queries you are able to run that make use of the cache. If it says 0, for example, your cache might not be working properly and this grid might reveal a configuration issue. | |
|
Executor Metrics Across All nodes | Total Executor Requests |
Shows the total number of task requests that were handled, succeeded, failed, killed, evicted and rejected across all nodes.
Handled: Total requests across all sub-groups Succeed: Total requests that were processed. For example, if you have 8 core machines, the number of total executor requests would be 8 Failed: Did not complete successfully because, for example, you ran out of memory Rejected: If all task priorities are the same, but there are still not enough slots to fulfill the request, the system will reject some tasks Evicted: Lower priority requests are evicted if the slots are filled by higher priority requests |
| Total Execution Slots |
Shows the total execution slots, the number of free or available slots, and number of slots occupied in the wait queue across all nodes.
Ideally, the threads available (blue) result should be the same as the threads that are occupied in the queue result. | |
| Time to Kill Pre-empted Task (300s interval) | Shows the time that it took to kill a query due to pre-emption in percentile (50th, 90th, 99th) latencies in 300 second intervals. | |
| Max Time To Kill Task (due to preemption) | Shows the maximum time taken to kill a task due to pre-emption. This grid and the one above show you if you are wasting a lot of time killing queries. Time lost while a task is waiting to be killed is time lost in the cluster. If your max time to kill is high, you might want to disable this feature. | |
| Pre-emption Time Lost (300s interval) | Shows the time lost due to pre-emption in percentile (50th, 90th, 99th) latencies in 300 second intervals. | |
| Max Time Lost In Cluster (due to pre-emption) | Shows the maximum time lost due to pre-emption. If your max time to kill is high, you might want to disable this feature. | |
| IO Elevator Metrics Across All Nodes | Column Decoding Time (30s interval) |
Shows the percentile (50th, 90th, 99th) latencies for time it takes to decode the column chunk (convert encoded column chunk to column vector batches for processing) in 30 second intervals.
The cache comes from IO Elevator. It loads data from HDFS to the cache, and then from the cache to the executor. This metric shows how well the threads are performing and is useful to see that the threads are running. |
| Max Column Decoding Time | Shows the maximum time taken to decode column chunk (convert encoded column chunk to column vector batches for processing). | |
| JVM Metrics across all nodes | Average JVM Heap Usage |
Shows the average amount of Java Virtual Machine (JVM) heap memory used across all nodes.
If the heap usage keeps increasing, you might run out of memory and the task failure count would also increase. |
| Average JVM Non-Heap Usage |
Shows the average amount of JVM non-heap memory used across all nodes.
| |
| Max GcTotalExtraSleepTime | Shows the maximum garbage collection extra sleep time in milliseconds across all nodes. Garbage collection extra sleep time measures when the garbage collection monitoring is delayed (for example, the thread does not wake up after 500 milliseconds). | |
| Max GcTimeMillis | Shows the total maximum GC time in milliseconds across all nodes. | |
| Total JVM Threads | Shows the total number of JVM threads that are in a NEW, RUNNABLE, WAITING, TIMED_WAITING, and TERMINATED state across all nodes. | |
| JVM Metrics | Total JVM Heap Used |
Shows the total amount of Java Virtual Machine (JVM) heap memory used in the daemon. If the heap usage keeps increasing, you might run out of memory and the task failure count would also increase. |
| Total JVM Non-Heap Used |
Shows the total amount of JVM non-heap memory used in the LLAP daemon.
If the non-heap memory is over-allocated, you might run out of memory and the task failure count would also increase. | |
| Max GcTotalExtraSleepTime | Shows the maximum garbage collection extra sleep time in milliseconds in the LLAP daemon. Garbage collection extra sleep time measures when the garbage collection monitoring is delayed (for example, the thread does not wake up after 500 milliseconds). | |
| Max GcTimeMillis | Shows the total maximum GC time in milliseconds in the LLAP daemon. | |
| Max JVM Threads Runnable | Shows the maximum number of Java Virtual Machine (JVM) threads that are in RUNNABLE state. | |
| Max JVM Threads Blocked | Shows the maximum number of JVM threads that are in BLOCKED state. If you are seeing spikes in the threads blocked, you might have a problem with your LLAP daemon. | |
| Max JVM Threads Waiting | Shows the maximum number of JVM threads that are in WAITING state. | |
| Max JVM Threads Timed Waiting | Shows the maximum number of JVM threads that are in TIMED_WAITING state. |