

Data lake overview
Cloudbreak allows you to deploy a long-running data lake instance and attach it to multiple ephemeral workload clusters.
 | Note |
|---|---|
This feature is technical preview. |
What is a data lake
A data lake provides a way for you to centrally apply and enforce authentication, authorization, and audit policies across multiple ephemeral workload clusters.
“Attaching” your workload cluster to the data lake instance allows the attached cluster workloads to access data and run in the security context provided by the data lake.
While workloads are temporary, the security policies around your data schema are long-running and shared for all workloads. As your workloads come and go, the data lake instance lives on, providing consistent and available security policy definitions that are available for current and future ephemeral workloads. All information related to schema (Hive), security policies (Ranger), and audit (Ranger) is stored on external locations (external databases and cloud storage). Furthermore, Ambari database is external and can be recovered.
This is illustrated in the following diagram:
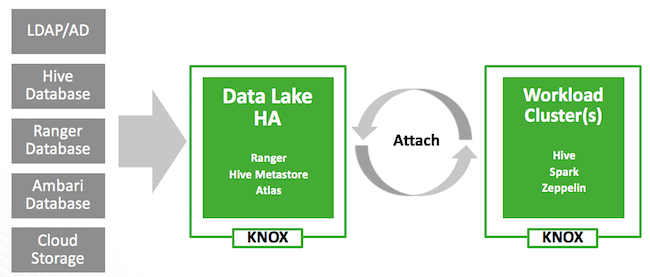
Once you’ve created a data lake instance, you have an option to attach it to one or more ephemeral clusters. This allows you to apply the authentication, authorization, and audit across multiple workload clusters.
Basic terminology
The following table explains basic data lake terminology:
| Term | Description |
|---|---|
| Data lake | Runs Ranger, which is used for configuring authorization policies and is used for audit capture. Runs Hive Metastore, which is used for data schema. |
| Workload clusters | The clusters that get attached to the data lake to run workloads. This is where you run workloads such as Hive via JDBC. |
Components
The following table explains the components of a data lake:
| Component | Technology | Description |
|---|---|---|
| Schema | Apache Hive | Provides Hive schema (tables, views, and so on). If you have two or more workloads accessing the same Hive data, you need to share schema across these workloads. |
| Policy | Apache Ranger | Defines security policies around Hive schema. If you have two or more users accessing the same data, you need security policies to be consistently available and enforced. |
| Audit | Apache Ranger | Audits user access and captures data access activity for the workloads. |
| Governance | Apache Atlas | Provides metadata management and governance capabilities. |
| Directory | LDAP/AD | Provides an authentication source for users and a definition of groups for authorization. |
| Gateway | Apache Knox | Supports a single workload endpoint that can be protected with SSL and enabled for authentication to access to resources. |
| Note |
|---|---|
Apache Atlas is not available as part of the HA blueprint but is available as part of a separate blueprint. |
Data lake high availability
If you select to use the HA blueprint, your data lake services will run in HA mode. Data lake HA blueprint deploys a three-node cluster by default:
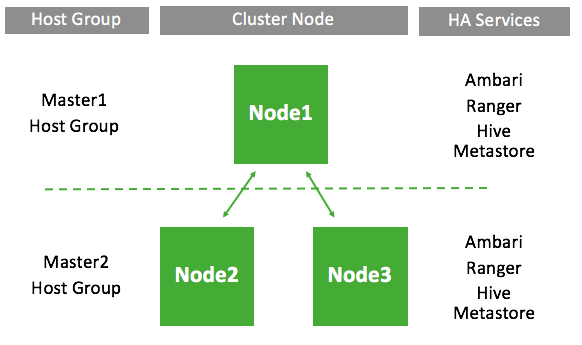
The exact number of nodes can be modified, but odd node number is HA best practice:e exact number of nodes can be modified, but odd node number is HA best practice. Since in a high availability data lake Ambari database must in all cases be external, it is available even if the Ambari server host goes down.
Cloudbreak monitors high availability data lakes, ensuring that when host-level failures occur, they are quickly resolved by deleting and replacing failed nodes of the high availability data lake (“HA data lake”). Once a failure is reported, it is repaired automatically (if enable auto recovery is selected), or options are available for you to repair the failure manually (if enable auto recovery is not selected).
When a data lake is launched, one of the hosts is selected as the primary gateway host, whereas the remaining hosts are considered secondary gateway (also known as “core”) hosts. The primary gateway host serves as the Ambari server node (with Ambari agents are connecting to that host only) and the Knox gateway node.
Two recovery scenarios are possible:
-
If one of the secondary gateway hosts goes down, a downscale and upscale flow happens to replace the missing node.
-
If the primary gateway host goes down, Cloudbreak first chooses a different node to be the primary gateway and launches Ambari server on that node. The new primary gateway node connects to the external Ambari database and Ambari agents automatically rejoin the new Ambari server. Next, the downscale and upscale flow happens to replace the missing node, and the newly added node becomes a secondary gateway node.
Since Cloudbreak assigns aliases to all nodes (Based on the "Custom domain" and "Custom hostname" parameters), the new nodes are assigned the same aliases as the failed nodes.
Once the repair is complete, all workload clusters attached to the HA data lake are updated so that they can communicate with the newly added nodes of the HA data lake.