As noted in What Is Hadoop, the Apache Hadoop framework enables the distributed processing of large data sets across clusters of commodity computers using a simple programming model. Hadoop is designed to scale up from single servers to thousands of machines, each providing computation and storage. Rather than rely on hardware to deliver high availability, the framework itself is designed to detect and handle failures at the application layer. This enables it to deliver a highly-available service on top of a cluster of computers, any of which might be prone to failure.
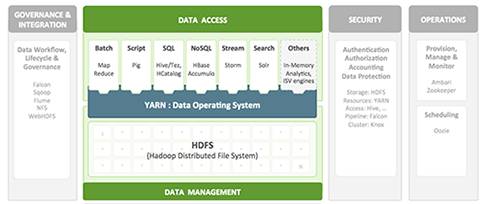
The core components of HDP are YARN and the Hadoop Distributed File System (HDFS).
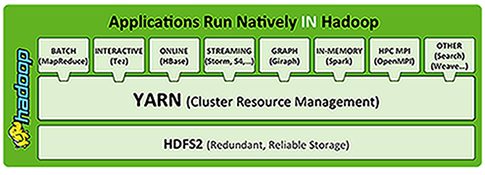
As part of Hadoop 2.0, YARN handles the process resource management functions previously performed by MapReduce.
YARN is designed to be co-deployed with HDFS such that there is a single cluster, providing the ability to move the computation resource to the data, not the other way around. With YARN, the storage system need not be physically separate from the processing system.
YARN provides a broader array of possible interaction patterns for data stored in HFDFS, beyond MapReduce; thus, multiple applications can be run in Hadoop, sharing a common resource management. This frees MapReduce to process data.
HDFS (storage) works closely with MapReduce (data processing) to provide scalable, fault-tolerant, cost-efficient storage for big data. By distributing storage and computation across many servers, the combined storage resource can grow with demand while remaining economical at every size.
HDFS can support file systems with up to 6,000 nodes, handling up to 120 Petabytes of data. It's optimized for streaming reads/writes of very large files. HDFS data redundancy enables it to tolerate disk and node failures. HDFS also automatically manages the addition or removal of nodes. One operator can handle up to 3,000 nodes.
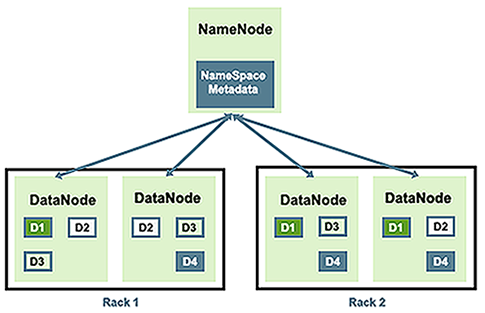
We discuss how HDFS works, and describe a typical HDFS cluster, in A Typical Hadoop Cluster.
MapReduce is a framework for writing applications that process large amounts of structured and unstructured data in parallel, across a cluster of thousands of machines, in a reliable and fault-tolerant manner. The Map function divides the input into ranges by the InputFormat and creates a map task for each range in the input. The JobTracker distributes those tasks to the worker nodes. The output of each map task is partitioned into a group of key-value pairs for each reduce. The Reduce function then collects the various results and combines them to answer the larger problem the master node was trying to solve.
Each reduce pulls the relevant partition from the machines where the maps executed, then writes its output back into HDFS. Thus, the reduce can collect the data from all of the maps for the keys it is responsible for and combine them to solve the problem.
Tez (SQL) leverages the MapReduce paradigm to enable the creation and execution of more complex Directed Acyclic Graphs (DAG) of tasks. Tez eliminates unnecessary tasks, synchronization barriers and reads-from and writes-to HDFS, speeding up data processing across both small-scale/low-latency and large-scale/high-throughput workloads.
Tez also acts as the execution engine for Hive, Pig and others.
Because the MapReduce interface is suitable only for developers, HDP provides higher-level abstractions to accomplish common programming tasks:
Pig (scripting). Platform for analyzing large data sets. It is comprised of a high-level language (Pig Latin) for expressing data analysis programs, and infrastructure for evaluating these programs (a compiler that produces sequences of Map-Reduce programs). Pig was designed for performing a long series of data operations, making it ideal for Extract-transform-load (ETL) data pipelines, research on raw data, and iterative processing of data. Pig Latin is designed to be easy to use, extensible and self-optimizing.
Hive (SQL). Provides data warehouse infrastructure, enabling data summarization, ad-hoc query and analysis of large data sets. The query language, HiveQL (HQL), is similar to SQL.
HCatalog (SQL). Table and storage management layer that provides users with Pig, MapReduce and Hive with a relational view of data in HDFS. Displays data from RCFile format, text or sequence files in a tabular view; provides REST APIs so that external systems can access these tables' metadata.
HBase (NoSQL). Non-relational database that provides random real-time access to data in very large tables. HBase provides transactional capabilities to Hadoop, allowing users to conduct updates, inserts and deletes. HBase includes support for SQL through Phoenix.
Accumulo (NoSQL). Provides cell-level access control for data storage and retrieval.
Storm (data streaming). Distributed real-time computation system for processing fast, large streams of data. Storm topologies can be written in any programming language, to create low-latency dashboards, security alerts and other operational enhancements to Hadoop.