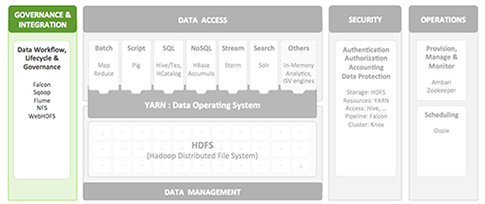
Governance and integration components enable the enterprise to load data and manage it according to policy, controlling the workflow of data and the data lifecycle. Goals of data governance include improving data quality (timeliness of current data, "aging" and "cleansing"of data that is growing stale), the ability to quickly respond to government regulations and improving the mapping and profiling of customer data.
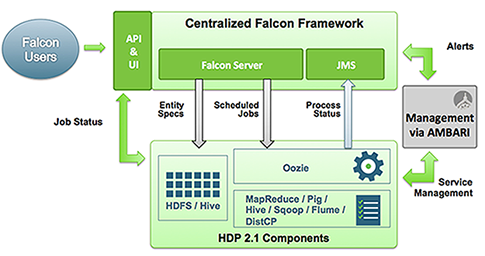
The primary mover of data governance in Hadoop is Apache Falcon. Falcon is a data governance engine that defines data pipelines, monitors those pipelines (in coordination with Ambari), and traces those pipelines for dependencies and audits.
Once Hadoop administrators define their data pipelines, Falcon uses those definition to auto-generate workflows in Apache Oozie, the Hadoop workflow scheduler.
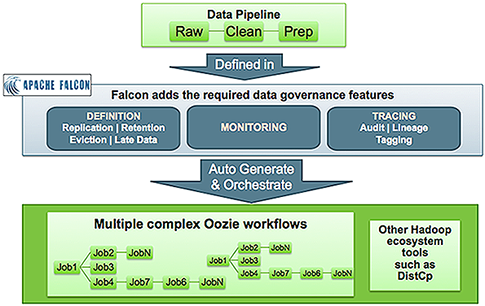
Falcon helps to address data governance challenges that can result when a data processing system employs hundreds to thousands of data sets and process definitions, using high-level, reusable "entities" that can be defined once and reused many times. These entities include data management policies that are manifested as Oozie workflows.
Other applications that are employed to implement Governance and Integration include:
Sqoop: Tool that efficiently transfers bulk data between Hadoop and structured datastores such as relational databases.
Flume: Distributed service that collects, aggregates and moves large amounts of streaming data to the Hadoop Distributed File System (HDFS).
WebHDFS: Protocol that provides HTTP REST access to HDFS, enabling users to connect to HDFS from outside of a Hadoop cluster.
For a closer look at how data pipelines are defined and processed in Apache Falcon, see the hands-on tutorial in the HDP 2.1 Hortonworks Sandbox.