The MapReduce examples are located in
hadoop-[VERSION]/share/hadoop/mapreduce. Depending on where you
installed Hadoop, this path may vary. For the purposes of this example let’s
define:
export YARN_EXAMPLES=$YARN_HOME/share/hadoop/mapreduce
$YARN_HOME should be defined as part of your installation. Also,
the following examples have a version tag, in this case “2.1.0-beta.” Your
installation may have a different version tag.
The following sections provide some examples of Hadoop YARN programs and benchmarks.
Listing Available Examples
Using our $YARN_HOME environment variable, we can get a list of
the available examples by running:
yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.1.0-beta.jar
This command returns a list of the available examples:
An example program must be given as the first argument. Valid program names are: aggregatewordcount: An Aggregate-based map/reduce program that counts the words in the input files. aggregatewordhist: An Aggregate-based map/reduce program that computes the histogram of the words in the input files. bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi. dbcount: An example job that counts the pageview counts from a database. distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi. grep: A map/reduce program that counts the matches of a regex in the input. join: A job that effects a join over sorted, equally partitioned datasets. multifilewc: A job that counts words from several files. pentomino: A map/reduce tile-laying program that finds solutions to pentomino problems. pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method. randomtextwriter: A map/reduce program that writes 10GB of random textual data per node. randomwriter: A map/reduce program that writes 10GB of random data per node. secondarysort: An example defining a secondary sort to the reduce. sort: A map/reduce program that sorts the data written by the random writer. sudoku: A sudoku solver. teragen: Generate data for the terasort. terasort: Run the terasort. teravalidate: Check the results of the terasort. wordcount: A map/reduce program that counts the words in the input files. wordmean: A map/reduce program that counts the average length of the words in the input files. wordmedian: A map/reduce program that counts the median length of the words in the input files. wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
To illustrate several features of Hadoop YARN, we will show you how to run the
pi and terasort examples, as well as the
TestDFSIO benchmark.
Running the pi Example
To run the pi example with 16 maps and 100000 samples, run the following command:
yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.1.0-beta.jar pi 16 100000
This command should return the following result (after the Hadoop messages):
13/10/14 20:10:01 INFO mapreduce.Job: map 0% reduce 0%
13/10/14 20:10:08 INFO mapreduce.Job: map 25% reduce 0%
13/10/14 20:10:16 INFO mapreduce.Job: map 56% reduce 0%
13/10/14 20:10:17 INFO mapreduce.Job: map 100% reduce 0%
13/10/14 20:10:17 INFO mapreduce.Job: map 100% reduce 100%
13/10/14 20:10:17 INFO mapreduce.Job: Job job_1381790835497_0003 completed successfully
13/10/14 20:10:17 INFO mapreduce.Job: Counters: 44
File System Counters
FILE: Number of bytes read=358
FILE: Number of bytes written=1365080
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=4214
HDFS: Number of bytes written=215
HDFS: Number of read operations=67
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=16
Launched reduce tasks=1
Data-local map tasks=14
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=174725
Total time spent by all reduces in occupied slots
(ms)=7294
Map-Reduce Framework
Map input records=16
Map output records=32
Map output bytes=288
Map output materialized bytes=448
Input split bytes=2326
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=448
Reduce input records=32
Reduce output records=0
Spilled Records=64
Shuffled Maps =16
Failed Shuffles=0
Merged Map outputs=16
GC time elapsed (ms)=195
CPU time spent (ms)=7740
Physical memory (bytes) snapshot=6143696896
Virtual memory (bytes) snapshot=23140454400
Total committed heap usage (bytes)=4240769024
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1888
File Output Format Counters
Bytes Written=97
Job Finished in 20.854 seconds
Estimated value of Pi is 3.14127500000000000000
Note that the MapReduce progress is shown -- as is the case with MapReduce V1 -- but the application statistics are different. Most of the statistics are self-explanatory. The one important item to note is that the YARN “Map-Reduce Framework” is used to run the program. The use of this framework, which is designed to be compatible with Hadoop V1, will be discussed further in subsequent sections.
Using the Web GUI to Monitor Examples
The Hadoop YARN web Graphical User Interface (GUI) has been updated for Hadoop
Version 2. This section shows you how to use the web GUI to monitor and find
information about YARN jobs. In the following examples, we use the
pi application, which can run quickly and be finished before
you have explored the GUI. A longer running application -- such as
terasort -- may be helpful when exploring all the various links
in the GUI.
The following figure shows the main YARN web interface (http://hostname:8088).

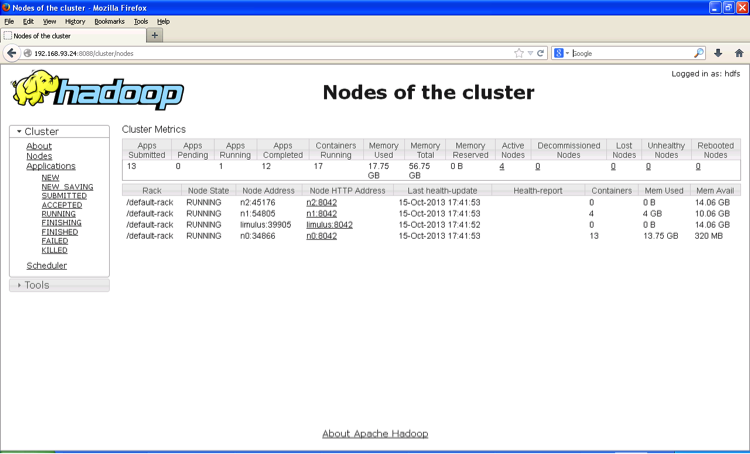
If you look at the Cluster Metrics table, you will see some new information. First, you will notice that rather than Hadoop Version 1 “Map/Reduce Task Capacity,” there is now information on the number of running Containers. If YARN is running a MapReduce job, these Containers will be used for both map and reduce tasks. Unlike Hadoop Version 1, in Hadoop Version 2 the number of mappers and reducers is not fixed. There are also memory metrics and a link to node status. To display a summary of the node activity, click Nodes. The following image shows the node activity while the pi application is running. Note again the number of Containers, which are used by the MapReduce framework as either mappers or reducers.
If you navigate back to the main Running Applications window and click the
application_138… link, the Application status page appears.
This page provides information similar to that on the Running Applications page,
but only for the selected job.
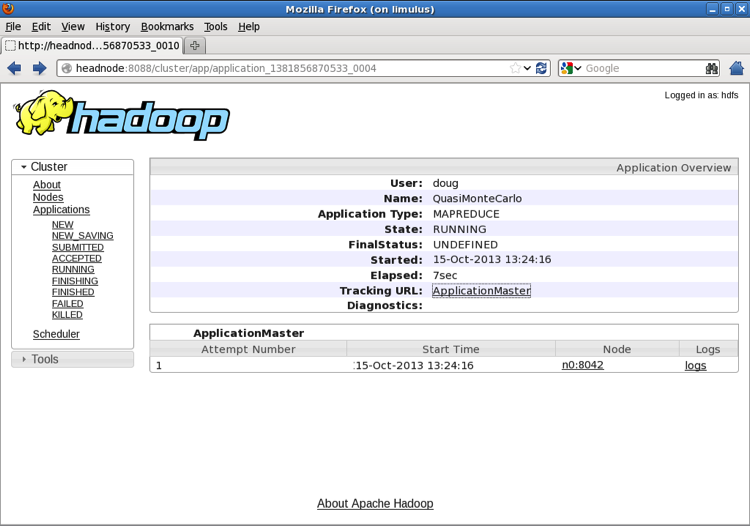
Clicking the ApplicationMaster link on the Application status page opens the MapReduce Application page shown in the following figure. Note that the link to the ApplicationMaster is also on the main Running Applications screen in the last column.

Details about the MapReduce process can be observed on the MapReduce
Application page. Instead of Containers, the MapReduce application now refers to
Maps and Reduces. Clicking the job_138… link opens the MapReduce
Job page:
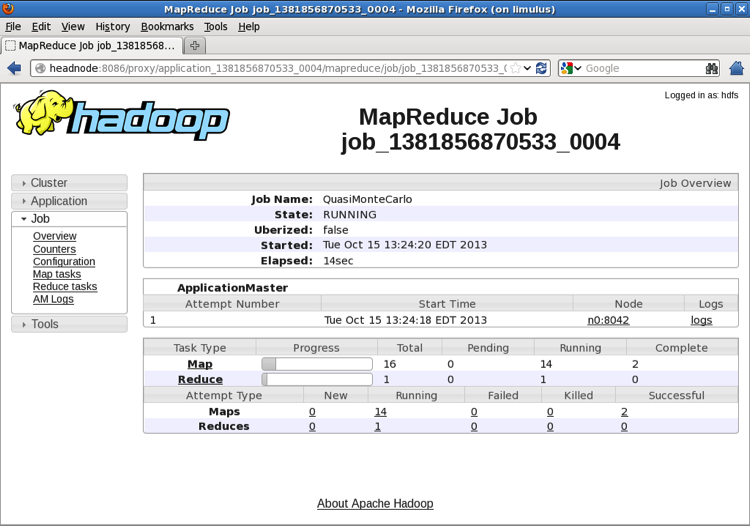
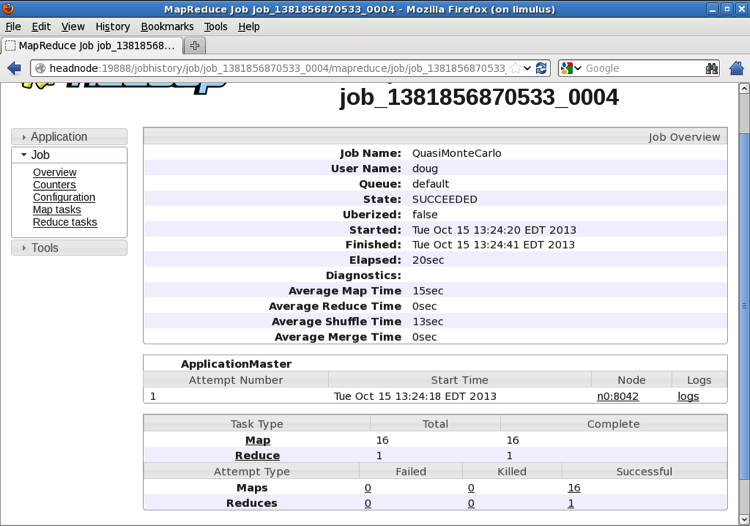
The MapReduce Job page provides more detail about the status of the job. When the job is finished, the page is updated as shown in the following figure:
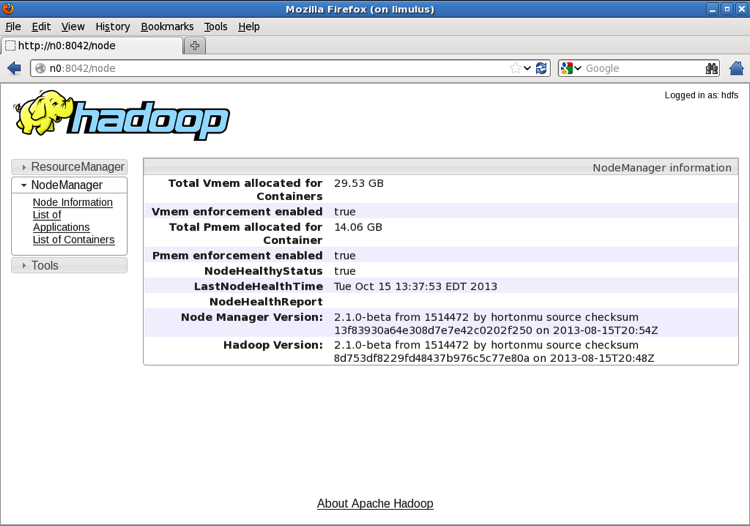
If you click the Node used to run the ApplicationMaster (n0:8042
above), a NodeManager summary page appears, as shown in the following figure.
Again, the NodeManager only tracks Containers. The actual tasks that the
Containers run is determined by the ApplicationMaster.
If you navigate back to the MapReduce Job page, you can access log files for the ApplicationMaster by clicking the logs link:

If you navigate back to the main Cluster page and select Applications > Finished, and then select the completed job, a summary page is displayed:

There are a few things to take note of based on our movement through the preceding GUI. First, because YARN manages applications, all input from YARN refers to an “application.” YARN has no data about the actual application. Data from the MapReduce job is provided by the MapReduce Framework. Thus there are two clearly different data streams that are combined in the web GUI: YARN applications and Framework jobs. If the Framework does not provide job information, certain parts of the web GUI will have nothing to display.
Another interesting aspect to note is the dynamic nature of the mapper and reducer tasks. These are executed as YARN Containers, and their numbers will change as the application runs. This feature provides much better cluster utilization, because mappers and reducers are dynamic rather than fixed resources.
Finally, there are other links in the preceding GUI that can be explored. With the MapReduce framework, it is possible to drill down to the individual map and reduce tasks. If log aggregation is enabled, the individual logs for each map and reduce task can be viewed.
Running the Terasort Test
To run the terasort benchmark, three separate steps are required. In general the rows are 100 bytes long, thus the total amount of data written is 100 times the number of rows (i.e. to write 100 GB of data, use 1000000000 rows). You will also need to specify input and output directories in HDFS.
Run
teragento generate rows of random data to sort.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.1.0-beta.jar teragen <number of 100-byte rows> <output dir>
Run
terasortto sort the database.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.1.0-beta.jar terasort <input dir> <output dir>
Run
teravalidateto validate the sorted Teragen.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.1.0-beta.jar teravalidate <terasort output dir> <teravalidate output dir>
Run the TestDFSIO Benchmark
YARN also includes a HDFS benchmark application named TestDFSIO.
As with terasort, it requires several steps. Here we will write and
read ten 1 GB files.
Run
TestDFSIOin write mode and create data.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.1.0-beta-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 1000
Example results are as follows (date and time removed):
fs.TestDFSIO: ----- TestDFSIO ----- : write fs.TestDFSIO: Date & time: Wed Oct 16 10:58:20 EDT 2013 fs.TestDFSIO: Number of files: 10 fs.TestDFSIO: Total MBytes processed: 10000.0 fs.TestDFSIO: Throughput mb/sec: 10.124306231915458 fs.TestDFSIO: Average IO rate mb/sec: 10.125661849975586 fs.TestDFSIO: IO rate std deviation: 0.11729341192174683 fs.TestDFSIO: Test exec time sec: 120.45 fs.TestDFSIO:
Run
TestDFSIOin read mode.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.1.0-beta-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 1000
Example results are as follows (date and time removed):
fs.TestDFSIO: ----- TestDFSIO ----- : read fs.TestDFSIO: Date & time: Wed Oct 16 11:09:00 EDT 2013 fs.TestDFSIO: Number of files: 10 fs.TestDFSIO: Total MBytes processed: 10000.0 fs.TestDFSIO: Throughput mb/sec: 40.946519750553804 fs.TestDFSIO: Average IO rate mb/sec: 45.240928649902344 fs.TestDFSIO: IO rate std deviation: 18.27387874605978 fs.TestDFSIO: Test exec time sec: 47.937 fs.TestDFSIO:
Clean up the
TestDFSIOdata.yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.1.0-beta-tests.jar TestDFSIO -clean