The MapReduce Distributed Processing Model
The MapReduce distributed processing model consists of a highly parallel map phase where input data is split into discreet chunks for processing. It is followed by the second and final reduce phase where the output of the map phase is aggregated to produce the desired result. The simple -- and fairly restricted -- nature of this programming model lends itself to very efficient implementations on an extremely large scale across thousands of cheap, commodity nodes.
Apache Hadoop MapReduce is the most popular open-source implementation of the MapReduce model. In particular, when MapReduce is paired with a distributed file system such as Apache Hadoop HDFS, which can provide very high aggregate I/O bandwidth across a large cluster, the economics of the system are extremely compelling –- a key factor in the popularity of Hadoop.
One of the key features in MapReduce is the lack of data motion, i.e., move the computation to the data, rather than moving data to the compute node via the network. Specifically, the MapReduce tasks can be scheduled on the same physical nodes on which data resides in HDFS, which exposes the underlying storage layout across the cluster. This significantly reduces the network I/O patterns and keeps most of the I/O on the local disk or within the same rack, which is a key advantage.
MapReduce on Hadoop Version 1
Apache Hadoop MapReduce is an open-source Apache Software Foundation project, and is an implementation of the MapReduce programming model described above. Version 1 of the Apache Hadoop MapReduce project can be broken down into the following major components:
The end-user MapReduce API for programming the desired MapReduce application.
The MapReduce framework, which is the run-time implementation of various phases such as the map phase, the sort/shuffle/merge aggregation, and the reduce phase.
The MapReduce system, which is the back-end infrastructure required to run the MapReduce application, manage cluster resources, schedule thousands of concurrent jobs, etc.
This separation of elements offered significant benefits, particularly for end-users – they could completely focus on the application via the API, and allow the combination of the MapReduce Framework and the MapReduce System to deal with details such as resource management, fault-tolerance, scheduling, etc.
The version 1 Apache Hadoop MapReduce System was composed of the Job Tracker, which was the master, and the per-node slaves referred to as Task Trackers.

In Hadoop version 1, the Job Tracker is responsible for resource management (managing the worker nodes via the Task Trackers), tracking resource consumption and availability, and also job life-cycle management (scheduling individual tasks of a job, tracking progress, providing fault-tolerance for tasks, etc.).
The Task Tracker has simple responsibilities: executing launch and tear-down tasks on orders from the Job Tracker, and periodically providing task status information to the Job Tracker.
MapReduce works well for many applications, but not all. Other programming models are better suited for applications such as graph processing (Google Pregel, Apache Giraph) and iterative modeling using MPI (Message Parsing Interface). It also became clear that there was room for improvement in scalability, utilization, and user agility.
MapReduce on Hadoop YARN
In Apache Hadoop version 2, cluster resource management has been moved from MapReduce into YARN, thus enabling other application engines to utilize YARN and Hadoop. This also streamlines MapReduce to do what it does best: process data. With YARN, you can now run multiple applications in Hadoop, all sharing a common resource management.

The fundamental idea of YARN is to split up the two major responsibilities of the Job Tracker -- resource management and job scheduling/monitoring -- into separate daemons: a global Resource Manager and a per-application Application Master. The Resource Manager and its per-node slave, the Node Manager, form the new operating system for managing applications in a distributed manner.
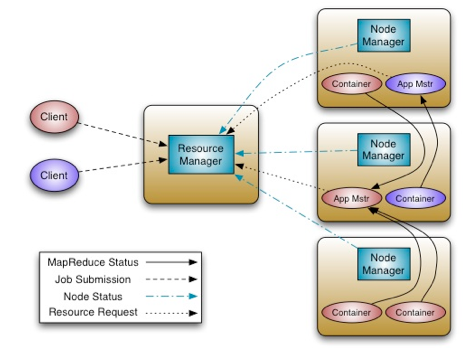
The Resource Manager is the ultimate authority that arbitrates resources among all the applications in the system. The per-application Application Master is a framework-specific entity, and is tasked with negotiating resources from the Resource Manager and working with the Node Managers to execute and monitor the component tasks.
The Resource Manager has a pluggable Scheduler component, which is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is a pure scheduler in the sense that it performs no monitoring or tracking of status for the application, offering no guarantees on restarting failed tasks either due to application or hardware failures. The scheduler performs its scheduling function based on the resource requirements of an application by using the abstract notion of a resource Container, which incorporates resource dimensions such as memory, CPU, disk, network, etc.
The Node Manager is the per-machine slave, and is responsible for launching the applications’ Containers, monitoring their resource usage (CPU, memory, disk, network), and reporting this information to the Resource Manager.
The per-application Application Master has the responsibility of negotiating appropriate resource Containers from the Scheduler, tracking their status, and monitoring their progress. From the system perspective, the Application Master runs as a normal Container.
One of the crucial implementation details for MapReduce within the new YARN system is the reuse of the existing MapReduce framework without any major changes. This step was very important to ensure compatibility with existing MapReduce applications.