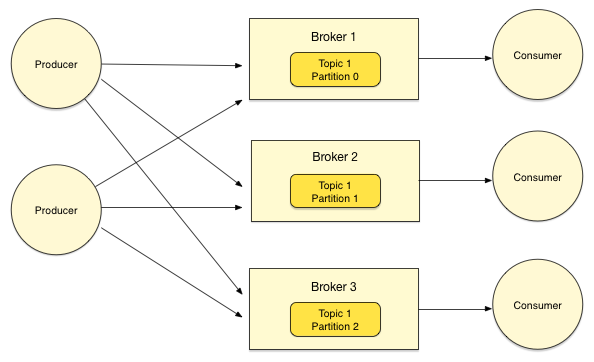
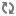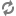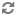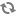Apache Kafka is a distributed, partitioned, replicated message service. Writing Storm applications that either the Kafka Spout or Bolt requires an understanding of the following concepts:
Table 1.4. Basic Kafka Concepts
Kafka Concept | Description |
|---|---|
Topic | A user-defined category to which messages are published. Topics consist of one or more partitions, ordered, immutable sequences of messages to which Kafka appends new messages. Each message in a topic is assigned a unique, sequential ID called an offset. |
Producer | A process that publishes messages to one or more Kafka topics. |
Consumer | A process that consumes messages from one or more Kafka topics. |
Broker | A Kafka server. |
Kafka Cluster | One or more Kafka Brokers. |
Topic
A topic is a user-defined category to which messages are published. Kafka is an ideal companion to Apache Storm, a distributed real-time computation system. Combining both technologies enables stream processing at linear scale and assures that every message is reliably processed in real-time. Apache Storm ships with full support for using Kafka 0.8.1 as a data source with both Storm’s core API as well as the higher-level, micro-batching Trident API. This flexibility allows you to choose the message processing scheme that best fit your specific use case:
At-most-once processing
At-least-once processing
Exactly-once processing
Storm’s Kafka integration also includes support for writing data to Kafka, enabling complex data flows between components in a Hadoop-based architecture.Topics consist of one or more Partitions that are ordered, immutable sequences of messages. Since writes to a Partition are sequential, this design greatly reduces the number of hard disk seeks and the resulting latency.
Broker
Kafka Brokers scale and perform so well in part because Brokers, or Kafka servers, are not responsible for keeping track of what messages have been consumed. The message Consumer is responsible for this. In traditional messaging systems such as JMS, the Broker bears this responsibility, which severely limits the system’s ability to scale as the number of Consumers increase.
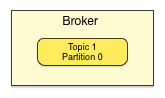
Consumer
Kafka Consumers keep track of which messages have already been consumed, or processed, by keeping track of an offset, a sequential id number that uniquely identifies a message within a partition. Because Kafka retains all messages on disk for a configurable amount of time, Consumers can rewind or skip to any point in a partition simply by supplying an offset value. In the image below, the Consumer has processed 7 messages from the partition.
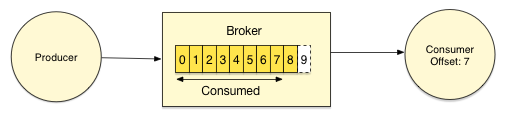
This design eliminates the potential for back-pressure when consumers process messages at different rates.
Kafka Cluster
A Kafka cluster contains one or more Brokers, as well as multiple producers and consumers.