
Security
Enterprise-level security generally requires four layers of security: authentication, authorization, accounting and data protection.
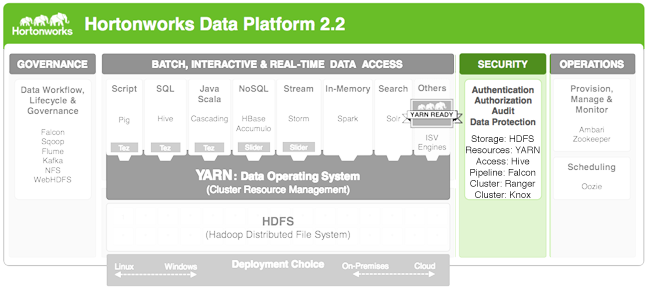
HDP and other members of the Apache open source community address security concerns as follows:
Authentication. Verifying the identity of a system or user accessing the cluster. Hadoop provides both simple authentication and Kerberos (fully secure) authentication while relying on widely-accepted corporate user stores (such as LDAP or Active Directory), so a single source can be used for credentialling across the data processing network.
Authorization. Specifying access privileges for a user or system is accomplished through Knox Gateway, which includes support for the lookup of enterprise group permissions plus the introduction of service-level access control.
Accounting. For security compliance of forensics, HDFS and MapReduce provide base audit support; Hive metastore provides an audit trail showing who interacts with Hive and when such interactions occur; Oozie, the workflow engine, provides a similar audit trail for services.
Data protection. In order to protect data in motion, ensuring privacy and confidentiality, HDP provides encryption capability for various channels through Remote Procedure Call (RPC), HTTP, HDBC/ODBC and Data Transfer Protocol (DTP). HDFS supports encryption at the operating system level.
Other Apache projects in a Hadoop distribution include their own access control features. For example, HDFS has file permissions for fine-grained authorization; MapReduce includes resource-level access control via ACL; HBase provides authorization with ACL on tables and column families; Accumulo extends this further for cell-level access control. Apache Hive provides coarse-grained access control on tables.
Applications that are deployed with HDFS, Knox and Kerberos to implement security include:
Hive (access). Provides data warehouse infrastructure, enabling data summarization, ad- hoc query and analysis of large data sets. The query language, HiveQL (HQL), is similar to SQL.
Falcon (pipeline). Server that simplifies the development and management of data processing pipelines by supplying simplified data replication handling, data lifecycle management, data lineage and traceability and process coordination and scheduling. Falcon enables the separation of business logic from application logic via the use of high- level data abstractions such as Clusters, Feeds and Processes. It utilizes existing services like Oozie to coordinate and schedule data workflows.