Using the Falcon Web UI to Define Data Pipelines
The Falcon web UI enables you to define and deploy data pipelines. Using the web UI ensures that the XML definition file that you use to deploy the data pipeline to the Falcon server is well-formed.
![[Important]](../common/images/admon/important.png) | Important |
|---|---|
This section is intended as a quick start for the new Falcon web UI. The content will be updated on a regular cadence over the new few months. |
Prerequisite Setup Steps:
Before you define a data pipeline, a system administrator must:
Make sure that you have the following components installed on your cluster:
HDP
Falcon
Oozie client and server
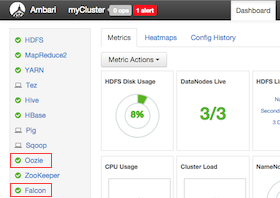
Make sure that the Falcon and Oozie services are running. For example, if you are using Ambari, confirm that the Falcon and Oozie services have green check marks adjacent to them on the Ambari dashboard:
Create the directory structure on HDFS for the staging, temp, and working folders where the cluster entity stores the dataset. These folders must be owned by the falcon user.
For example:
sudo su falcon hadoop fs mkdir -p /apps/falcon/primary_Cluster/staging hadoop fs mkdir -p /apps/falcon/primary_Cluster/working hadoop fs mkdir -p /apps/falcon/tmp
These commands create the following directories that are owned by the falcon user:
/apps/falcon/primary_Cluster/staging
/apps/falcon/primary_Cluster/working
/apps/falcon/tmp
Important Permissions on the cluster staging directory must be set to 777 (read/write/execute for owner/group/others). Only Oozie job definitions are written to the staging directory so setting permissions to 777 does not create any vulnerability.
Run:
hadoop fs -chmod -R 777 <your_staging_directory_path>Launch the Falcon web UI. If you are using Ambari:
On the Services tab, select Falcon in the services list.
At the top of the Falcon service page, click Quick Links, and then click Falcon Web UI.