
Use the ORC File Format
The ORC file format provides the following advantages:
Efficient compression: Stored as columns and compressed, which leads to smaller disk reads. The columnar format is also ideal for vectorization optimizations in Tez.
Fast reads: ORC has a built-in index, min/max values, and other aggregates that cause entire stripes to be skipped during reads. In addition, predicate pushdown pushes filters into reads so that minimal rows are read. And Bloom filters further reduce the number of rows that are returned.
Proven in large-scale deployments: Facebook uses the ORC file format for a 300+ PB deployment.
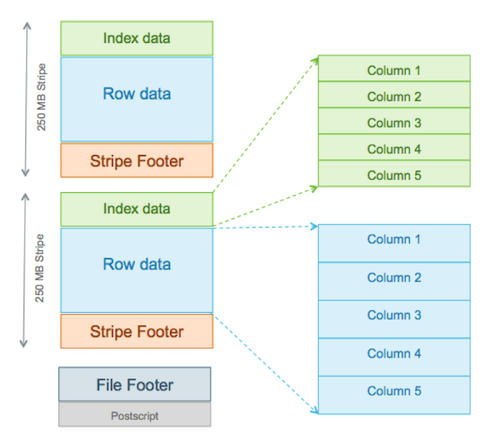
Specifying the Storage Format as ORC
In addition, to specifying the storage format, you can also specify a compression algorithm for the table:
CREATE TABLE addresses (
name string,
street string,
city string,
state string,
zip int
) STORED AS orc tblproperties ("orc.compress"="Zlib");![[Note]](../common/images/admon/note.png) | Note |
|---|---|
Setting the compression algorithm is usually not required because your Hive settings include a default algorithm. |
Switching the Storage Format to ORC
You can read a table and create a copy in ORC with the following command:
CREATE TABLE a_orc STORED AS ORC AS SELECT * FROM A;
Ingestion as ORC
A common practice is to land data in HDFS as text, create a Hive external table over it, and then store the data as ORC inside Hive where it becomes a Hive-managed table.
Advanced Settings
ORC has properties that usually do not need to be modified. However, for special cases you can modify the properties listed in the following table when advised to by Hortonworks Support.
Table 2.1. ORC Properties
Key | Default Setting | Notes |
|---|---|---|
orc.compress | ZLIB | Compression type (NONE, ZLIB, SNAPPY). |
orc.compress.size | 262,144 | Number of bytes in each compression block. |
orc.stripe.size | 268,435,456 | Number of bytes in each stripe. |
orc.row.index.stride | 10,000 | Number of rows between index entries (>= 1,000). |
orc.create.index | true | Sets whether to create row indexes. |
orc.bloom.filter.columns | -- | Comma-separated list of column names for which a Bloom filter must be created. |
orc.bloom.filter.fpp | 0.05 | False positive probability for a Bloom filter. Must be greater than 0.0 and less than 1.0. |