
Chapter 7. Maximizing Storage Resources
ORC File Format
The Optimized Row Columnar (ORC) file format provides the following advantages over many other file formats:
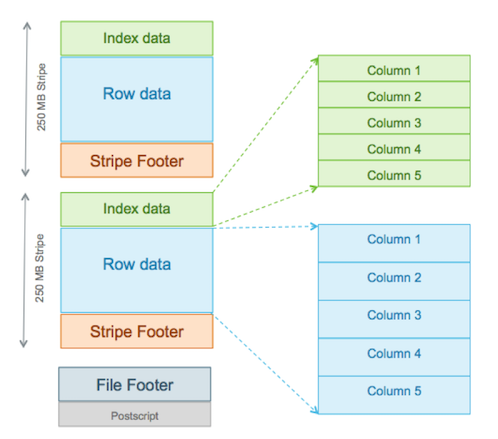
Efficient compression: Stored as columns and compressed, which leads to smaller disk reads. The columnar format is also ideal for vectorization optimizations in Tez.
Fast reads: ORC has a built-in index, min/max values, and other aggregates that cause entire stripes to be skipped during reads. In addition, predicate pushdown pushes filters into reads so that minimal rows are read. And Bloom filters further reduce the number of rows that are returned.
Proven in large-scale deployments: Facebook uses the ORC file format for a 300+ PB deployment.
Specifying the Storage Format as ORC
In addition, to specifying the storage format, you can also specify a compression algorithm for the table:
CREATE TABLE addresses (
name string,
street string,
city string,
state string,
zip int
) STORED AS orc tblproperties ("orc.compress"="Zlib");![[Note]](../common/images/admon/note.png) | Note |
|---|---|
Setting the compression algorithm is usually not required because your Hive settings include a default algorithm. |
Switching the Storage Format to ORC
You can read a table and create a copy in ORC with the following command:
CREATE TABLE a_orc STORED AS ORC AS SELECT * FROM A;
Ingestion as ORC
A common practice is to land data in HDFS as text, create a Hive external table over it, and then store the data as ORC inside Hive where it becomes a Hive-managed table.
Advanced Settings
ORC has properties that usually do not need to be modified. However, for special cases you can modify the properties listed in the following table when advised to by Hortonworks Support.
Table 7.1. ORC Properties
Key | Default Setting | Notes |
|---|---|---|
orc.compress | ZLIB | Compression type (NONE, ZLIB, SNAPPY). |
orc.compress.size | 262,144 | Number of bytes in each compression block. |
orc.stripe.size | 268,435,456 | Number of bytes in each stripe. |
orc.row.index.stride | 10,000 | Number of rows between index entries (>= 1,000). |
orc.create.index | true | Sets whether to create row indexes. |
orc.bloom.filter.columns | -- | Comma-separated list of column names for which a Bloom filter must be created. |
orc.bloom.filter.fpp | 0.05 | False positive probability for a Bloom filter. Must be greater than 0.0 and less than 1.0. |
Designing Data Storage with Partitions and Buckets
Partitioned Tables
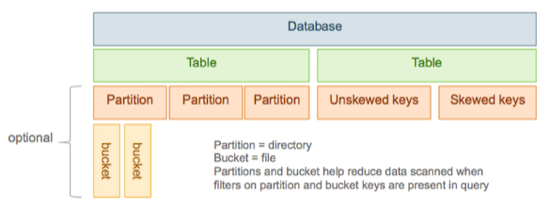
In Hive, tables are often partitioned. Partitions map to physical directories on the filesystem. Frequently, tables are partitioned by date-time as incoming data is loaded into Hive each day. Large deployments can have tens of thousands of partitions.
Using partitions can significantly improve performance if a query has a filter on the partitioned columns, which can prune partition scanning to one or a few partitions that match the filter criteria. Partition pruning occurs directly when a partition key is present in the WHERE clause. Pruning occurs indirectly when the partition key is discovered during query processing. For example, after joining with a dimension table, the partition key might come from the dimension table.
Partitioned columns are not written into the main table because they are the same for the entire partition, so they are "virtual columns." However, to SQL queries, there is no difference:
CREATE TABLE sale(id in, amount decimal) PARTITIONED BY (xdate string, state string);
To insert data into this table, the partition key can be specified for fast loading:
INSERT INTO sale (xdate='2016-03-08', state='CA') SELECT * FROM staging_table WHERE xdate='2016-03-08' AND state='CA';
Without the partition key, the data can be loaded using dynamic partitions, but that makes it slower:
hive-site.xml settings for loading 1 to 9 partitions:
SET hive.exec.dynamic.partition.mode=nonstrict; SET hive.exec.dynamic.partition=true;
For bulk-loading data into partitioned ORC tables, invoke a specific property that is designed specifically for this purpose. Enabling the property optimizes the performance of data loading into 10 or more partitions.
hive-site.xml setting for loading 10 or more partitions:
hive.optimize.sort.dynamic.partition=true
Examples of HiveQL query on partitioned data
INSERT INTO sale (xdate, state) SELECT * FROM staging_table;
The virtual columns that are used as partitioning keys must be last. Otherwise, you must re-order the columns using a SELECT statement similar to the following:
INSERT INTO sale (xdate, state='CA') SELECT id, amount, other_columns..., xdate FROM staging_table WHERE state='CA';
![[Tip]](../common/images/admon/tip.png) | Tip |
|---|---|
Follow these best practices when you partition tables and query partitioned tables:
|
Bucketed Tables
Tables or partitions can be further divided into buckets, which are stored as files in the directory for the table or the directories of partitions if the table is partitioned. Bucketing can optimize Hive's scanning of a data set that is the target of repeated queries.
When buckets are used with Hive tables and partitions, a common challenge is to maintain query performance while workload or data scales up or down. For example, you could have an environment where picking 16 buckets to support 1000 users operates smoothly, but a spike in the number of users to 100,000 for a day or two could create problems if the buckets and partitions are not promptly tuned. Tuning the buckets is complicated by the fact that after you have constructed a table with buckets, the entire table containing the bucketed data must be reloaded to reduce, add, or eliminate buckets.
With Tez, you only need to deal with the buckets of the biggest table. If workload demands change rapidly, the buckets of the smaller tables dynamically change to complete table JOINs.
hive-site.xml setting for enabling table buckets:
SET hive.tez.bucket.pruning=true
Bulk-loading tables that are both partitioned and bucketed:
When you load data into tables that are both partitioned and bucketed, set the following property to optimize the process:
SET hive.optimize.sort.dynamic.partition=true
Example of using HiveQL with bucketed data:
If you have 20 buckets on user_id data, the following query returns only the data associated with user_id = 1:
select * from tab where user_id = 1;
To best leverage the dynamic capability of table buckets on Tez:
Use a single key for the buckets of the largest table.
Usually, you need to bucket the main table by the biggest dimension table. For example, the sales table might be bucketed by customer and not by merchandise item or store. However, in this scenario, the sales table is sorted by item and store.
Normally, do not bucket and sort on the same column.
| Tip |
|---|---|
A table that has more bucket files than the number of rows is an indication that you should reconsider how the table is bucketed. |
Supported Filesystems
While a Hive EDW can run on one of a variety of storage layers, HDFS and Amazon S3 are the most prevalently used and known filesystems for data analytics that run in the Hadoop stack. By far, the most common filesystem used for a public cloud infrastructure is Amazon S3.
A Hive EDW can store data on other filesystems, including WASB and ADLS.
Depending on your environment, you can tune the filesystem to optimize Hive performance by configuring compression format, stripe size, partitions, and buckets. Also, you can create Bloom filters for columns frequently used in point lookups.