
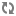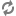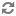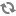
Step 1: Storage Group Classification
The HDFS Balancer first invokes the
getLiveDatanodeStorageReport rpc to the Namenode to the
storage report for all the storages in all Datanodes. The storage report contains
storage utilization information such as capacity, dfs used space, remaining space,
and so forth, for each storage in each datanode.
A Datanode can contain multiple storages and the storages can have different
storage types. A storage group Gi,T is defined to be the group of
all the storages with the same storage type T in Datanode
i. For example, Gi,DISK is the storage
group of all the DISK storages in Datanode i. For each storage type T in each
datanode i, HDFS Balancer computes Storage Group Utilization (%)
Ui,T = 100% (storage group used space)/(storage group capacity),
and Average Utilization (%)
Uavg,T = 100% * (sum of all used spaces)/(sum of all capacities).
Let △ be the threshold parameter (default is 10%) and GI,T be the storage group with storage type T in datanode I.
Over-Utilized: {Gi,T : Uavg,T + Δ < Ui,T},
Average + Threshold --------------------------------------------------------------------------------
Above-Average: {Gi,T : Uavg,T < Ui,T <= Uavg,T + Δ},
Average -------------------------------------------------------------------------------------------------
Below-Average: {Gi,T : Uavg,T - Δ <= Ui,T <= Uavg,T},
Average - Threshold ---------------------------------------------------------------------------------
Under-Utilized: {Gi,T : Ui,T < Uavg,T - Δ }.
Roughly speaking, a storage group is over-utilized (under-utilized) if its utilization is larger (smaller) than the average plus (minus) threshold. A storage group is above-average (below-average) if its utilization is larger (smaller) than average but within the threshold.
If there are no over-utilized storages and no under-utilized storages, the cluster is said to be balanced. The HDFS Balancer terminates with a SUCCESS state. Otherwise, it continues with the following steps.