Steps for migrating Impala workloads to Cloudera Data Warehouse Data Service on premises
After you upgrade from CDH to Cloudera Base on premises you can retain your compute workload on Cloudera Base on premises and continue to use Impala as your query engine. To get to the latest Impala version with the full feature set, the ideal choice available to you is to move your compute workload from Cloudera Base on premises to Cloudera Data Warehouse on premises
Before you begin, acquire basic information about the Cloudera platform and the interfaces.
Activate the Cloudera environment in Cloudera Data Warehouse
Before you can create a Database Catalog to use with a Virtual Warehouse, you must activate a Cloudera environment in Cloudera Data Warehouse. Activating an environment causes Cloudera to connect to the Kubernetes cluster, which provides the computing resources for the Database Catalog. In addition, activating an environment enables the Cloudera Data Warehouse service to use the existing data lake that was set up for the environment, including all data, metadata, and security.
To activate an environment, see Activating OpenShift and Embedded Container Service environments. Also, review the sizing information to plan resources for your environment. For more information about accessing and using the sizing spreadsheet, see Cloudera Data Services on premises sizing spreadsheet..
Setup and size an Impala Virtual Warehouse
After activating the environment, you must create and configure an Impala Virtual Warehouse. Learn about the configurations and options that Cloudera Data Warehouse (CDW) provides to size the Virtual Warehouse.
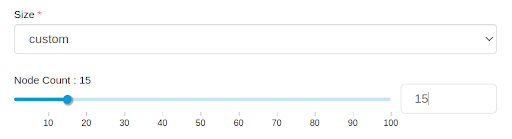
Size
The size of a Virtual Warehouse controls the Executor group
size as shown in the
following diagram. This controls the number of Impala executor pods that a single query runs on.
Select a size that is appropriate for the amount of data to be scanned or aggregrated and the
amount of data cache that is needed overall. By default, each executor pod and coordinator pod
caches 300 GB data and scratches 300 GB data.

Concurrency-based auto-scaling

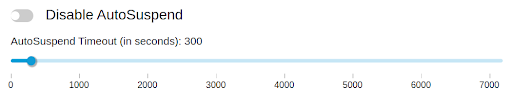
Auto-suspend a Virtual Warehouse
Wait time
Import custom configurations
You must import custom configurations that you used for optimizing performance, mitigating the pressure on the network, avoiding resource usage spikes and out-of-memory conditions, to keep long-running queries or idle sessions from tying up cluster resources, and so on.
default_file_formatanddefault_transactional_typeCONVERT_LEGACY_HIVE_PARQUET_UTC_TIMESTAMPSandUSE_LOCAL_TZ_FOR_UNIX_TIMESTAMP_CONVERSIONS(especially for older datasets to avoid Hive vs Impala timestamp issues)- Runtime filters for performance:
RUNTIME_BLOOM_FILTER_SIZE,RUNTIME_FILTER_MAX_SIZE,RUNTIME_FILTER_MIN_SIZE,RUNTIME_FILTER_MODE, andRUNTIME_FILTER_WAIT_TIME_MS PARQUET_FALLBACK_SCHEMA_RESOLUTION(to handle any column order changes)TIMEZONE(because CDW uses the UTC timezoone)COMPRESSION_CODEC(based on your need; LZ4 is recommended)SCHEDULE_RANDOM_REPLICAandREPLICA_PREFERENCE(to avoid hotspotting)EXEC_TIME_LIMIT_S,IDLE_SESSION_TIMEOUT, andQUERY_TIMEOUT_SDISABLE_CODEGEN_ROWS_THRESHOLD,EXEC_SINGLE_NODE_ROWS_THRESHOLD, andBROADCAST_BYTES_LIMITSCRATCH_LIMITif set to higher on CDP Private Cloud Base needs to be limited to a value between 300 and 600 GB- Enable
ALLOW_ERASURE_CODED_FILESand disableDECIMAL_V2only if needed MEM_LIMIT(automatically selected between a range of 2 G to 50 G)- You can set
MEM_LIMITin the default query options, if needed - Administrators can tweak the Impala's admission control configurations to set a reasonable range for minimum and maximum query memory limit
- You can set
-
Select the Impala Virtualk Warehouse that you want to modify and click
 > Edit > CONFIGURATIONS > Impala Coordinator and select flagfile from the drop-down
list.
> Edit > CONFIGURATIONS > Impala Coordinator and select flagfile from the drop-down
list.
-
Update the configurations in the default_query_options
field as shown in the following image:
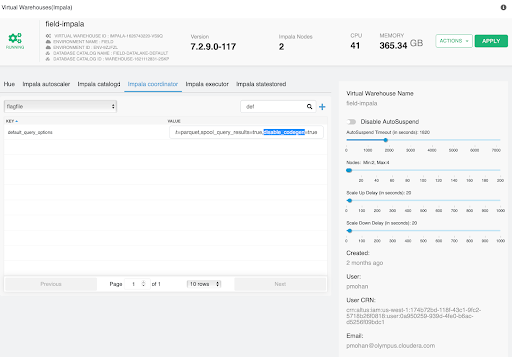 Similarly, make the required changes for the Impala executor (.
Similarly, make the required changes for the Impala executor (.
Create Virtual Warehouses to implement admission control
There is only one queue in Cloudera Data Warehouse's Virtual Warehouses that is used to run all queries in a first-in-first-out (FIFO) order. If you have multiple queues on the base cluster that you are migrating to Cloudera Data Warehouse Impala, then you must create a Virtual Warehouse for each queue or a request pool, so that you can isolate the compute environments for each of those user groups.
Modify client connections (JDBC and ODBC)
Impala in Cloudera Data Warehouse provides a JDBC/ODBC endpoint that can be used to configure all BI tools and applications for each Virtual Warehouse. In Cloudera Data Warehouse, different user groups will likely get their own Virtual Warehouse, each of which has its own unique JDBC/ODBC URL. Make sure that you point your BI clients to the corresponding URL.
In the CDH environment, you had access to one monolithic Impala cluster and you used one JDBC/ODBC URL to connect your Impala clients to the cluster. All your client applications used that one URL. In Cloudera Data Warehouse, you must direct your individual client applications to their own Virtual Warehouse JDBC/ODBC URLs. The URL for each Virtual Warehouse is unique. Therefore, you can recreate a Virtual Warehouse with the same name so that the URL remains the same.
- Impala in Cloudera Data Warehouse uses the port 443 and communicates over the http protocol, whereas, Impala on the base cluster uses the binary 21050 protocol.
- Impala in Cloudera Data Warehouse uses LDAP authentication, whereas, Impala
on the base cluster uses Kerberos and Knox. Therefore, you must specify a username and
password.
Kerberos authentication will be available in Cloudera Data Warehouse Data Service on premises in a future release.
- Impala in Cloudera Data Warehouse uses the latest Simba drivers. Download the latest JDBC driver from the Cloudera Downloads page, or alternatively, on the Virtual Warehouses page. Simba drivers are backward-compatible.
- For granting access to the Impala-shell, click > Copy Impala shell command on the Virtual Warehouse tile to copy the command line for invocating the
impala-shell. This command line contains all the required parameters, including the
default user ID for the Virtual Warehouse (this is the Virtual Warehouse's admin user) as
required for LDAP, and the network address of the Impala coordinator.The Impala-shell command line in Cloudera Data Warehouse contains the following parameters that are not present in the Impala-shell command line on the base cluster:
--protocol='hs2-http': The HiveServer2 protocol that impala-shell uses to speak to the Impala daemon--ssl: Used to enable TLS/SSL for the Impala-shell. This parameter is always present in the command line.- Uses the 443 port by changing the endpoint to the Virtual Warehouse's
coordinator endpoint inside the Virtual Warehouse's coordinator pod. For example:
coordinator-default-impala.dw-demo.ylcu-atmi.cloudera.site:443 -l: Used to specify LDAP user name and password for LDAP-based authentication instead of Kerberos. LDAP authentication uses the LDAP server defined on the Authentication page of the Cloudera Management Consoleon premises.
Following is a sample Impala shell command:impala-shell --protocol='hs2-http' --strict_hs2_protocol --ssl -i coordinator-default-impala.dw-demo.ylcu-atmi.cloudera.site:443' -u [***USERNAME***] -l