Admission Control and Query Queuing
Admission control is an Impala feature that imposes limits on concurrent SQL queries, to avoid resource usage spikes and out-of-memory conditions on busy CDH clusters. Enable this feature if your cluster is underutilized at some times and overutilized at others. Overutilization is indicated by performance bottlenecks and queries being cancelled due to out-of-memory conditions, when those same queries are successful and perform well during times with less concurrent load. Admission control works as a safeguard to avoid out-of-memory conditions during heavy concurrent usage.
 Important
Important
Important
ImportantUse the COMPUTE STATS statement for large tables involved in join queries, and follow other steps from Tuning Impala for Performance to tune your queries. Although COMPUTE STATS is an important statement to help optimize query performance, it is especially important when admission control is enabled:
- When queries complete quickly and are tuned for optimal memory usage, there is less chance of performance or capacity problems during times of heavy load.
- The admission control feature also relies on the statistics produced by the COMPUTE STATS statement to generate accurate estimates of memory usage for complex queries. If the estimates are inaccurate due to missing statistics, Impala might hold back queries unnecessarily even though there is sufficient memory to run them, or might allow queries to run that end up exceeding the memory limit and being cancelled.
Overview of Impala Admission Control
On a busy CDH cluster, you might find there is an optimal number of Impala queries that run concurrently. Because Impala queries are typically I/O-intensive, you might not find any throughput benefit in running more concurrent queries when the I/O capacity is fully utilized. Because Impala by default cancels queries that exceed the specified memory limit, running multiple large-scale queries at once can result in having to re-run some queries that are cancelled.
The admission control feature lets you set a cluster-wide upper limit on the number of concurrent Impala queries and on the memory used by those queries. Any additional queries are queued until the earlier ones finish, rather than being cancelled or running slowly and causing contention. As other queries finish, the queued queries are allowed to proceed.
For details on the internal workings of admission control, see How Impala Schedules and Enforces Limits on Concurrent Queries.
How Impala Admission Control Relates to YARN
The admission control feature is similar in some ways to the YARN resource management framework, and they can be used separately or together. This section describes some similarities and differences, to help you decide when to use one, the other, or both together.
Admission control is a lightweight, decentralized system that is suitable
for workloads consisting primarily of Impala queries and other SQL statements.
It sets
Because the admission control system is not aware of other Hadoop workloads such as MapReduce jobs, you might use YARN with static service pools on heterogeneous CDH 5 clusters where resources are shared between Impala and other Hadoop components. Devote a percentage of cluster resources to Impala, allocate another percentage for MapReduce and other batch-style workloads; let admission control handle the concurrency and memory usage for the Impala work within the cluster, and let YARN manage the remainder of work within the cluster.
You could also try out the combination of YARN, Impala, and Llama, where YARN manages all cluster resources and Impala queries request resources from YARN by using the Llama component as an intermediary. YARN is a more centralized, general-purpose service, with somewhat higher latency than admission control due to the requirement to pass requests back and forth through the YARN and Llama components.
The Impala admission control feature uses the same mechanism as the YARN resource manager to map users to pools and authenticate them. Although the YARN resource manager is only available with CDH 5 and higher, internally Impala includes the necessary infrastructure to work consistently on both CDH 4 and CDH 5. You do not need to run the actual YARN and Llama components for admission control to operate.
In Cloudera Manager, the controls for Impala resource management change slightly depending on whether the Llama role is enabled, which brings Impala under the control of YARN. When you use Impala without the Llama role, you can specify three properties (memory limit, query queue size, and queue timeout) for the admission control feature. When the Llama role is enabled, you can specify query queue size and queue timeout, but the memory limit is enforced by YARN and not settable through the Dynamic Resource Pools page.
How Impala Schedules and Enforces Limits on Concurrent Queries
The admission control system is decentralized, embedded in each impalad daemon and communicating through the statestore mechanism. Although the limits you set for memory usage and number of concurrent queries apply cluster-wide, each impalad daemon makes its own decisions about whether to allow each query to run immediately or to queue it for a less-busy time. These decisions are fast, meaning the admission control mechanism is low-overhead, but might be imprecise during times of heavy load. There could be times when the query queue contained more queries than the specified limit, or when the estimated of memory usage for a query is not exact and the overall memory usage exceeds the specified limit. Thus, you typically err on the high side for the size of the queue, because there is not a big penalty for having a large number of queued queries; and you typically err on the low side for the memory limit, to leave some headroom for queries to use more memory than expected, without being cancelled as a result.
At any time, the set of queued queries could include queries submitted through multiple different impalad nodes. All the queries submitted through a particular node will be executed in order, so a CREATE TABLE followed by an INSERT on the same table would succeed. Queries submitted through different nodes are not guaranteed to be executed in the order they were received. Therefore, if you are using load-balancing or other round-robin scheduling where different statements are submitted through different nodes, set up all table structures ahead of time so that the statements controlled by the queueing system are primarily queries, where order is not significant. Or, if a sequence of statements needs to happen in strict order (such as an INSERT followed by a SELECT), submit all those statements through a single session, while connected to the same impalad node.
The limit on the number of concurrent queries is a
To avoid a large backlog of queued requests, you can also set an upper limit on the size of the queue for queries that are delayed. When the number of queued queries exceeds this limit, further queries are cancelled rather than being queued. You can also configure a timeout period, after which queued queries are cancelled, to avoid indefinite waits. If a cluster reaches this state where queries are cancelled due to too many concurrent requests or long waits for query execution to begin, that is a signal for an administrator to take action, either by provisioning more resources, scheduling work on the cluster to smooth out the load, or by doing Impala performance tuning to enable higher throughput.
How Admission Control works with Impala Clients (JDBC, ODBC, HiveServer 2)
Most aspects of admission control work transparently with client interfaces such as JDBC and ODBC:
- If a SQL statement is put into a queue rather than running immediately, the API call blocks until the statement is dequeued and begins execution. At that point, the client program can request to fetch results, which might also block until results become available.
- If a SQL statement is cancelled because it has been queued for too long or because it exceeded the memory limit during execution, the error is returned to the client program with a descriptive error message.
Admission control has the following limitations or special behavior when used with JDBC or ODBC applications:
- If you want to submit queries to different resource pools through the REQUEST_POOL query option, as described in REQUEST_POOL, that option is only settable for a session through the impala-shell interpreter or cluster-wide through an impalad startup option.
- The MEM_LIMIT query option, sometimes useful to work around problems caused by inaccurate memory estimates for complicated queries, is only settable through the impala-shell interpreter and cannot be used directly through JDBC or ODBC applications.
- Admission control does not use the other resource-related query options, RESERVATION_REQUEST_TIMEOUT or V_CPU_CORES. Those query options only apply to the YARN resource management framework.
Configuring Admission Control
The configuration options for admission control range from the simple (a single resource pool with a single set of options) to the complex (multiple resource pools with different options, each pool handling queries for a different set of users and groups). You can configure the settings through the Cloudera Manager user interface, or on a system without Cloudera Manager by editing configuration files or through startup options to the impalad daemon.
Configuring Admission Control with Cloudera Manager
In the Cloudera Manager Admin Console, you can configure pools to manage queued Impala queries, and the options for the limit on number of concurrent queries and how to handle queries that exceed the limit. For details, see the Cloudera Manager documentation for managing resources.
See Examples of Admission Control Configurations for a sample setup for admission control under Cloudera Manager.
Configuring Admission Control Manually
If you do not use Cloudera Manager, you use a combination of startup options for the impalad daemon, and optionally editing or manually constructing the configuration files fair-scheduler.xml and llama-site.xml.
 Note
NoteFor a straightforward configuration using a single resource pool named default, you can specify configuration options on the command line and skip the fair-scheduler.xml and llama-site.xml configuration files.
The impalad configuration options related to the admission control feature are:
- --default_pool_max_queued
-
Purpose:
Maximum number of requests allowed to be queued
before rejecting requests.
Because this limit applies cluster-wide,
but each Impala node makes independent decisions to run queries immediately
or queue them, it is a soft limit; the overall number of queued queries
might be slightly higher during times of heavy load.
A negative value or 0 indicates requests are
always rejected once the maximum concurrent requests are
executing. Ignored if fair_scheduler_config_path and llama_site_path are set.
Type: int64
Default: 0
- --default_pool_max_requests
-
Purpose:
Maximum number of concurrent outstanding requests allowed to run before incoming requests are queued.
Because this limit applies cluster-wide,
but each Impala node makes independent decisions to run queries immediately
or queue them, it is a soft limit; the overall number of concurrent queries
might be slightly higher during times of heavy load.
A negative value indicates no limit.
Ignored if fair_scheduler_config_path and llama_site_path are set.
Type: int64
Default: -1
- --default_pool_mem_limit
-
Purpose:
Maximum amount of memory that all outstanding
requests in this pool can use before new requests to this pool are
queued. Specified in bytes, megabytes, or gigabytes by a number followed by
the suffix b (optional), m, or g, either upper- or lowercase.
You can specify floating-point values for megabytes and gigabytes, to represent fractional numbers such as
1.5.
You can also specify it as a percentage of the physical memory by specifying the suffix %.
0 or no setting indicates no limit.
Defaults to bytes if no unit is given.
Because this limit applies cluster-wide,
but each Impala node makes independent decisions to run queries immediately
or queue them, it is a soft limit; the overall memory used by concurrent queries
might be slightly higher during times of heavy load.
Ignored if fair_scheduler_config_path and llama_site_path are set.
Note
: Impala relies on the statistics produced by the COMPUTE STATS statement to estimate memory usage for each query. See COMPUTE STATS Statement for guidelines about how and when to use this statement.Type: string
Default: "" (empty string, meaning unlimited)
- --disable_admission_control
-
Purpose: Turns off the admission control feature entirely,
regardless of other configuration option settings.
Type: Boolean
Default: false
- --disable_pool_max_requests
-
Purpose:
Disables all per-pool limits on the maximum
number of running requests.
Type: Boolean
Default: false
- --disable_pool_mem_limits
-
Purpose:
Disables all per-pool mem limits.
Type: Boolean
Default: false
- --fair_scheduler_allocation_path
-
Purpose:
Path to the fair scheduler allocation file
(fair-scheduler.xml).
Type: string
Default: "" (empty string)
Usage notes: Admission control only uses a small subset of the settings that can go in this file, as described below. For details about all the Fair Scheduler configuration settings, see the Apache wiki.
- --llama_site_path
-
Purpose:
Path to the Llama configuration file (llama-site.xml). If
set, fair_scheduler_allocation_path must also be set.
Type: string
Default: "" (empty string)
Usage notes: Admission control only uses a small subset of the settings that can go in this file, as described below. For details about all the Llama configuration settings, see the documentation on Github.
- --queue_wait_timeout_ms
-
Purpose:
Maximum amount of time (in milliseconds) that a
request waits to be admitted before timing out.
Type: int64
Default: 60000
For an advanced configuration with multiple resource pools using different settings, set up the fair-scheduler.xml and llama-site.xml configuration files manually. Provide the paths to each one using the impalad command-line options, --fair_scheduler_allocation_path and --llama_site_path respectively.
The Impala admission control feature only uses the Fair Scheduler configuration settings to determine how to map users and groups to different resource pools. For example, you might set up different resource pools with separate memory limits, and maximum number of concurrent and queued queries, for different categories of users within your organization. For details about all the Fair Scheduler configuration settings, see the Apache wiki.
The Impala admission control feature only uses a small subset of possible settings from the llama-site.xml configuration file:
llama.am.throttling.maximum.placed.reservations.queue_name llama.am.throttling.maximum.queued.reservations.queue_name
For details about all the Llama configuration settings, see the documentation on Github.
See Examples of Admission Control Configurations for sample configuration files for admission control using multiple resource pools, without Cloudera Manager.
Examples of Admission Control Configurations
For full instructions about configuring dynamic resource pools through Cloudera Manager, see Dynamic Resource Pools in the Cloudera Manager documentation. The following examples demonstrate some important points related to the Impala admission control feature.
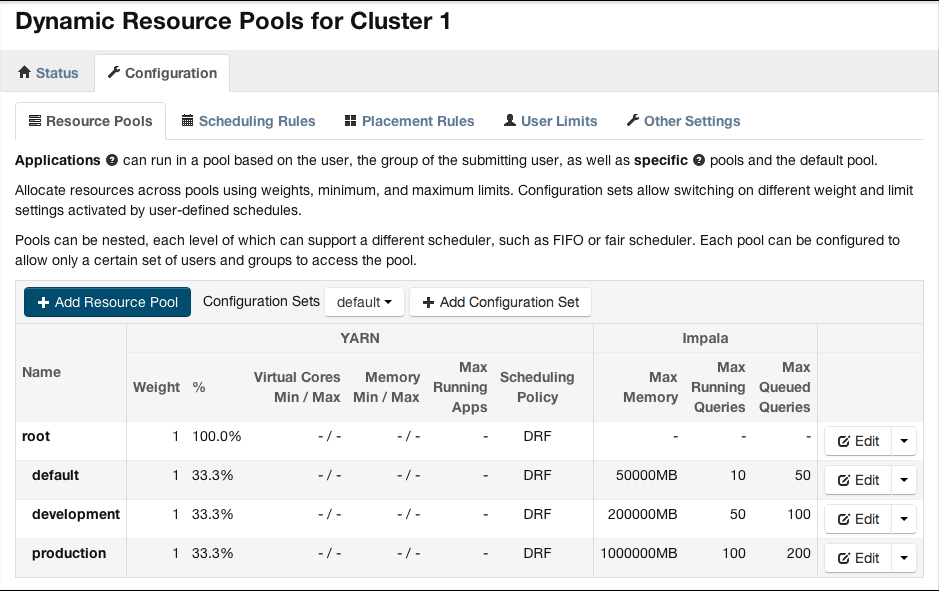
The following figure shows a sample of the Dynamic Resource Pools page in Cloudera Manager, accessed through the menu choice. Numbers from all the resource pools are combined into the topmost root pool. The default pool is for users who are not assigned any other pool by the user-to-pool mapping settings. The development and production pools show how you can set different limits for different classes of users, for total memory, number of concurrent queries, and number of queries that can be queued.
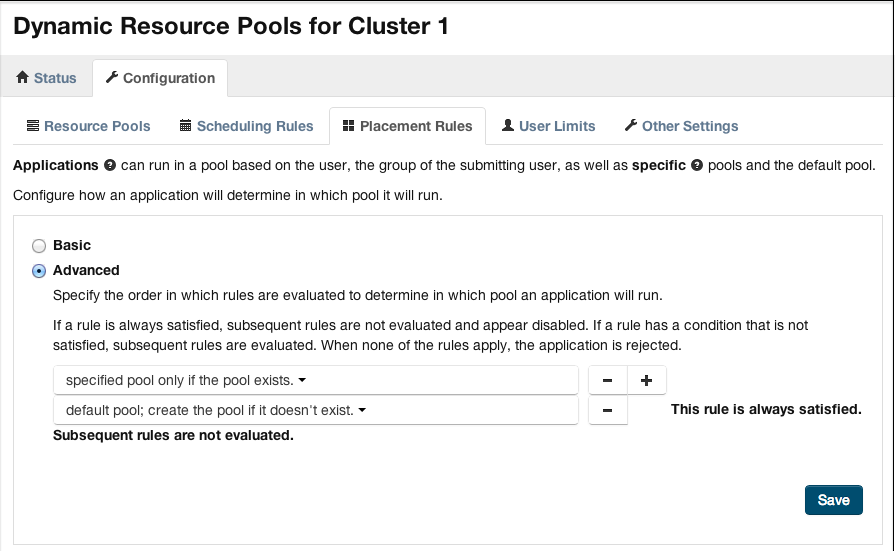
The following figure shows a sample of the Placement Rules page in Cloudera Manager, accessed through the menu choice. The settings demonstrate a reasonable configuration of a pool named default to service all requests where the specified resource pool does not exist, is not explicitly set, or the user or group is not authorized for the specified pool.
For clusters not managed by Cloudera Manager, here are sample fair-scheduler.xml and llama-site.xml files that define resource pools equivalent to the ones in the preceding Cloudera Manager dialog. These sample files are stripped down: in a real deployment they might contain other settings for use with various aspects of the YARN and Llama components. The settings shown here are the significant ones for the Impala admission control feature.
fair-scheduler.xml:
Although Impala does not use the vcores value, you must still specify it to satisfy YARN requirements for the file contents.
Each <aclSubmitApps> tag (other than the one for root) contains a comma-separated list of users, then a space, then a comma-separated list of groups; these are the users and groups allowed to submit Impala statements to the corresponding resource pool.
If you leave the <aclSubmitApps> element empty for a pool, nobody can submit directly to that pool; child pools can specify their own <aclSubmitApps> values to authorize users and groups to submit to those pools.
<allocations>
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<queue name="default">
<maxResources>50000 mb, 0 vcores</maxResources>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name="development">
<maxResources>200000 mb, 0 vcores</maxResources>
<aclSubmitApps>user1,user2 dev,ops,admin</aclSubmitApps>
</queue>
<queue name="production">
<maxResources>1000000 mb, 0 vcores</maxResources>
<aclSubmitApps> ops,admin</aclSubmitApps>
</queue>
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false"/>
<rule name="default" />
</queuePlacementPolicy>
</allocations>
llama-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>llama.am.throttling.maximum.placed.reservations.root.default</name>
<value>10</value>
</property>
<property>
<name>llama.am.throttling.maximum.queued.reservations.root.default</name>
<value>50</value>
</property>
<property>
<name>llama.am.throttling.maximum.placed.reservations.root.development</name>
<value>50</value>
</property>
<property>
<name>llama.am.throttling.maximum.queued.reservations.root.development</name>
<value>100</value>
</property>
<property>
<name>llama.am.throttling.maximum.placed.reservations.root.production</name>
<value>100</value>
</property>
<property>
<name>llama.am.throttling.maximum.queued.reservations.root.production</name>
<value>200</value>
</property>
</configuration>
Guidelines for Using Admission Control
To see how admission control works for particular queries, examine the profile output for the query. This information is available through the PROFILE statement in impala-shell immediately after running a query in the shell, on the queries page of the Impala debug web UI, or in the Impala log file (basic information at log level 1, more detailed information at log level 2). The profile output contains details about the admission decision, such as whether the query was queued or not and which resource pool it was assigned to. It also includes the estimated and actual memory usage for the query, so you can fine-tune the configuration for the memory limits of the resource pools.
Where practical, use Cloudera Manager 5 to configure the admission control parameters. The Cloudera Manager GUI is much simpler than editing the configuration files directly. In Cloudera Manager 4, the admission control settings are not available directly, but you can use the impalad safety valve field to configure appropriate startup options.
Remember that the limits imposed by admission control are
If you have trouble getting a query to run because its estimated memory usage is too high, you can override the estimate by setting the MEM_LIMIT query option in impala-shell, then issuing the query through the shell in the same session. The MEM_LIMIT value is treated as the estimated amount of memory, overriding the estimate that Impala would generate based on table and column statistics. This value is used only for making admission control decisions, and is not pre-allocated by the query.
In impala-shell, you can also specify which resource pool to direct queries to by setting the REQUEST_POOL query option. (This option was named YARN_POOL during the CDH 5 beta period.)
The statements affected by the admission control feature are primarily queries, but also include statements that write data such as INSERT and CREATE TABLE AS SELECT. Most write operations in Impala are not resource-intensive, but inserting into a Parquet table can require substantial memory due to buffering a substantial amount of data before writing out each Parquet data block. See Loading Data into Parquet Tables for instructions about inserting data efficiently into Parquet tables.
Although admission control does not scrutinize memory usage for other kinds of DDL statements, if a query is queued due to a limit on concurrent queries or memory usage, subsequent statements in the same session are also queued so that they are processed in the correct order:
-- This query could be queued to avoid out-of-memory at times of heavy load. select * from huge_table join enormous_table using (id); -- If so, this subsequent statement in the same session is also queued -- until the previous statement completes. drop table huge_table;
If you set up different resource pools for different users and groups, consider reusing any classifications and hierarchy you developed for use with Sentry security. See Enabling Sentry Authorization for Impala for details. For details about all the Fair Scheduler configuration settings, see the Apache wiki, in particular the tags such as <queue> and <aclSubmitApps> to map users and groups to particular resource pools (queues).
| << Impala Administration | Using YARN Resource Management with Impala (CDH 5 Only) >> | |