Project Environment Variables
Sometimes your code needs to use secrets, such as passwords and authentication tokens, in order to access external resources.
In general, Cloudera recommends that you not paste secrets into your code. Anyone with read access to your project would be able to view the secrets. Even if you did not give anyone read access, you would have to remember to carefully check any code that you copy and paste into another project, or add to a Git repository.
A better place to store secrets is in your project's environment variables, which you can manage by going to the project's Overview page and from the left sidebar, click .
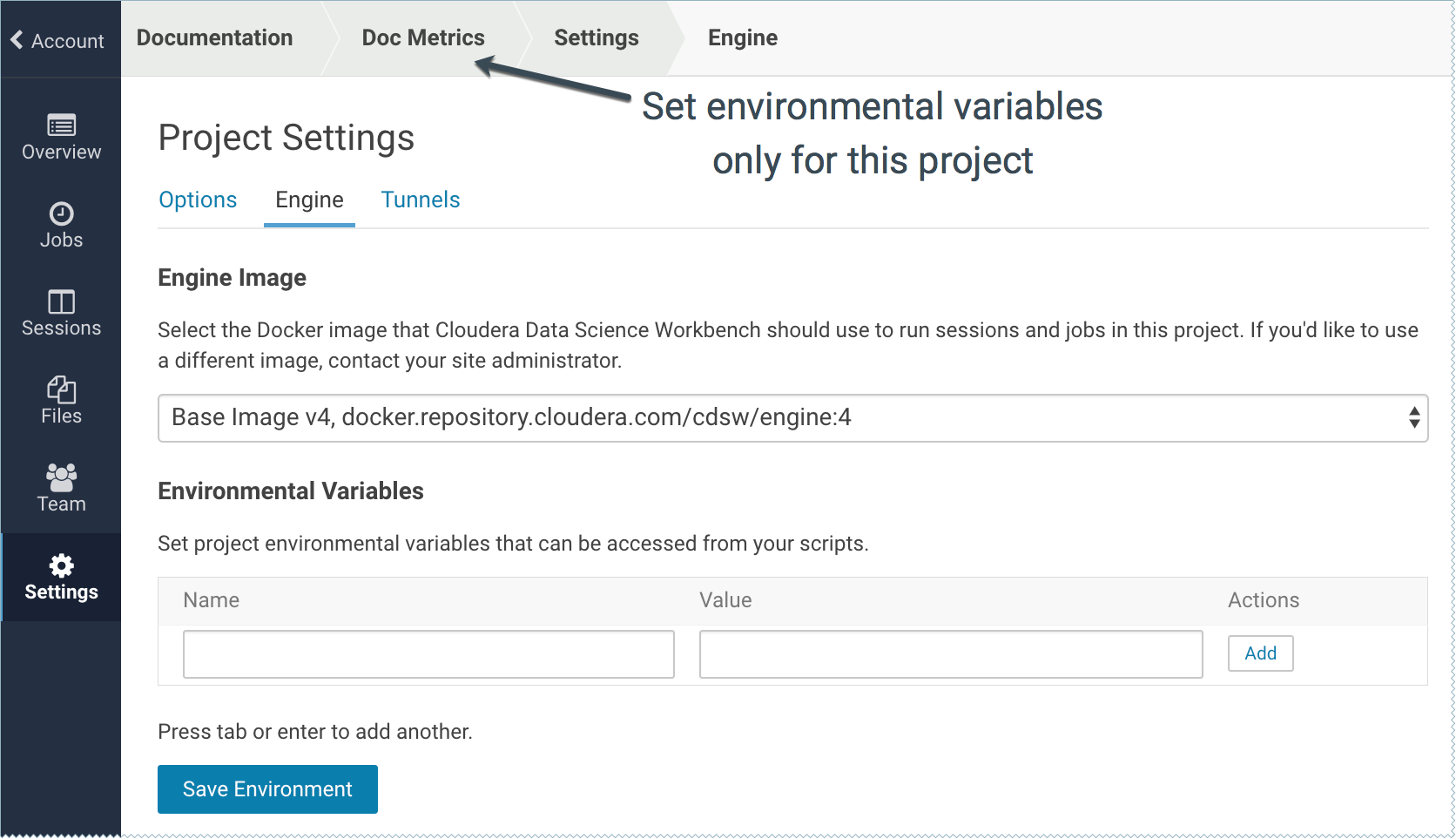
These environment variables are set in every engine that runs in your project. The code samples that follow show how to access the environment variable DATABASE_PASSWORD from your code.
R
database.password <- Sys.getenv("DATABASE_PASSWORD")
Python
import os database_password = os.environ["DATABASE_PASSWORD"]
Scala
System.getenv("DATABASE_PASSWORD")Engine Environment Variables
The following table lists environment variables that can be set in every engine.
| Environment Variable | Description |
|---|---|
| CDSW_PROJECT |
The project to which this engine belongs. |
| CDSW_CREATOR |
The username of the creator of this engine. |
| CDSW_ENGINE_ID |
The ID of this engine. For sessions, this appears in your browser's URL bar. |
| CDSW_MASTER_ID |
If this engine is a worker, this is the CDSW_ENGINE_ID of its master. |
| CDSW_MASTER_IP |
If this engine is a worker, this is the IP address of its master. |
| CDSW_PUBLIC_PORT |
A port on which you can expose HTTP services in the engine to browsers. HTTP services that bind CDSW_PUBLIC_PORT will be available in browsers at: http(s)://<$CDSW_ENGINE_ID>.<$CDSW_DOMAIN>. By default, CDSW_PUBLIC_PORT is set to 8080. A direct link to these web services will be available from the grid icon in the upper right corner of the Cloudera Data Science Workbench web application, as long as the job or session is still running. For more details, see Accessing Web User Interfaces from Cloudera Data Science Workbench. |
| CDSW_DOMAIN |
The domain on which Cloudera Data Science Workbench is being served. This can be useful for iframing services, as demonstrated in the Shiny example. |
| CDSW_CPU_MILLICORES |
The number of CPU cores allocated to this engine, expressed in thousandths of a core. |
| CDSW_MEMORY_MB |
The number of megabytes of memory allocated to this engine. |
| CDSW_IP_ADDRESS |
Other engines in the Cloudera Data Science Workbench cluster can contact this engine on this IP address. |
| IDLE_MAXIMUM_MINUTES |
Maximum number of minutes a session can remain idle before it exits. Default: 60 minutes Maximum Value: 35,000 minutes |
| SESSION_MAXIMUM_MINUTES |
Maximum number of minutes a session can run before it times out. Default: 60*24*7 minutes (7 days) Maximum Value: 35,000 minutes |
| JOB_MAXIMUM_MINUTES |
Maximum number of minutes a job can run before it times out. Default: 60*24*7 minutes (7 days) Maximum Value: 35,000 minutes |
| CONDA_DEFAULT_ENV |
Points to the default Conda environment so you can use Conda to install/manage packages in the Workbench. For more details on when to use this variable, see Using Conda with Cloudera Data Science Workbench. |