Introduction to Data Lakes
A Data Lake is a service which provides a protective ring around the data stored in a cloud object store, including authentication, authorization, and governance support.
A Data Lake provides a way for you to centrally apply and enforce authentication, authorization, and audit policies across multiple workload clusters—even as the workload clusters are created and terminated based on demand. When you register an environment in Cloudera, a Data Lake is automatically deployed for that environment. The Data Lake runs in the virtual network of the environment and provides security and governance layer for the environment’s workload resources (such as Cloudera Data Hub clusters). All workload resources are automatically "attached" to the Data Lake: the attached cluster workloads access data and run in the security context provided by the Data Lake.
While workloads are temporary, the security policies around your data schema are long-running and shared for all workloads. As your workloads come and go, the Data Lake instance lives on, providing consistent and available security policy definitions and auditing that are available for current and future workloads. All information related to schema (Hive Metastore), security policies (Ranger), audit (Ranger), and metadata management and governance (Atlas) is stored on external locations (external databases and cloud storage). These external locations leverage the security and availability features guaranteed by the cloud provider to ensure that even if one or all virtual hosts in a Data Lake fail, the storage remains and the Data Lake hosts can be replaced and reattached to the data storage with little or no downtime and no data loss.
A Data Lake cluster uses Apache Knox to provide a protected gateway for access to Data Lake component UIs. Knox is also installed on all workload clusters, providing a protected gateway for access to cluster component UIs.
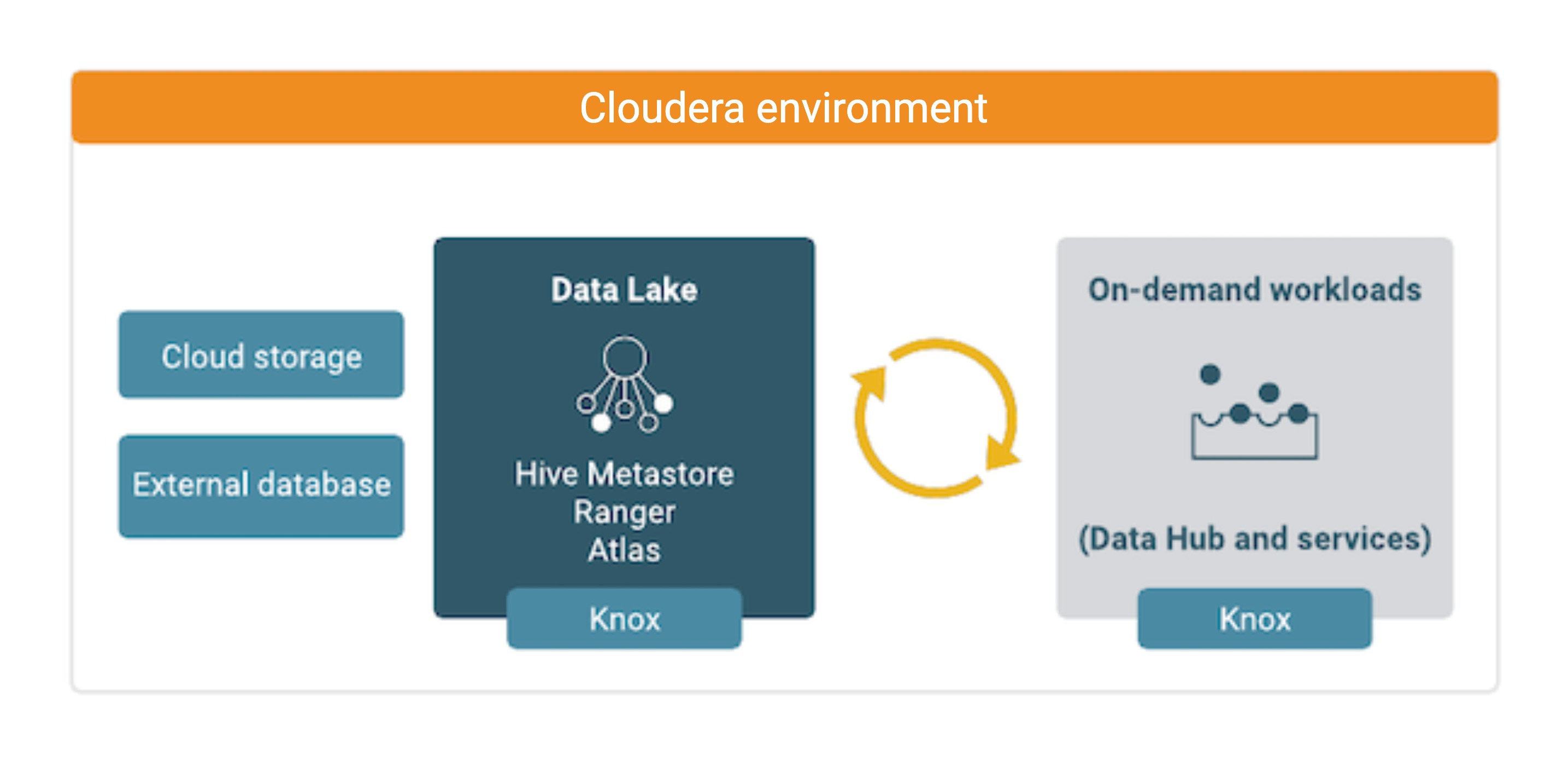
The following technologies provide capabilities for the Data Lake:
| Component | Technology | Description |
|---|---|---|
| Schema | Apache Hive Metastore | Provides Hive schema (tables, views, and so on). If you have two or more workloads accessing the same Hive data, you need to share schema across these workloads. |
| Policy | Apache Ranger | Defines security policies around Hive schema. If you have two or more users accessing the same data, you need security policies to be consistently available and enforced. |
| Audit | Apache Ranger | Audits user access and captures data access activity for the workloads. |
| Governance | Apache Atlas | Provides metadata management and governance capabilities. |
| Gateway | Apache Knox | Supports a single workload endpoint that can be protected with SSL and enabled for authentication to access to resources. |
| Storage | Cloud provider storage, such as AWS S3 or Azure Storage | Isolates Data Lake storage from the compute resources. Data Lake storage is created when the Data Lake is created and is deleted when the Data Lake is terminated. Once created, the Data Lake storage lifecycle is separate from the Data Lake hosts' lifecycle: in case of a Data Lake host failure, the Data Lake storage remains and is reattached to new Data Lake host or hosts. |